LREBench
收藏arXiv2023-09-18 更新2024-06-21 收录
下载链接:
https://zjunlp.github.io/project/LREBench
下载链接
链接失效反馈官方服务:
资源简介:
LREBench是由浙江大学与AZFT联合实验室知识引擎创建的数据集,包含8个覆盖不同语言、领域和上下文的实体关系抽取(RE)数据集。这些数据集旨在评估低资源环境下关系抽取系统的性能,特别关注极端少样本实例和长尾分布问题。数据集创建过程中,采用了多种方法如提示调优、数据平衡和数据增强等,以提高模型在资源有限情况下的泛化能力。LREBench的应用领域主要集中在信息抽取,特别是解决低资源环境下的关系抽取问题,推动相关技术向实际工业场景的过渡。
LREBench is a dataset developed by the Knowledge Engine of the Joint Laboratory of Zhejiang University and AZFT. It consists of 8 entity relation extraction (RE) datasets covering diverse languages, domains and contexts. These datasets are designed to evaluate the performance of relation extraction systems in low-resource scenarios, with a particular focus on extremely few-shot instances and long-tail distribution problems. During the dataset construction process, multiple methods such as prompt tuning, data balancing and data augmentation were adopted to enhance the generalization ability of models in resource-constrained settings. The application scenarios of LREBench mainly focus on information extraction, particularly addressing relation extraction problems in low-resource environments, and promoting the transition of related technologies to real-world industrial applications.
提供机构:
浙江大学 & AZFT 联合实验室知识引擎
创建时间:
2022-10-19
搜集汇总
数据集介绍
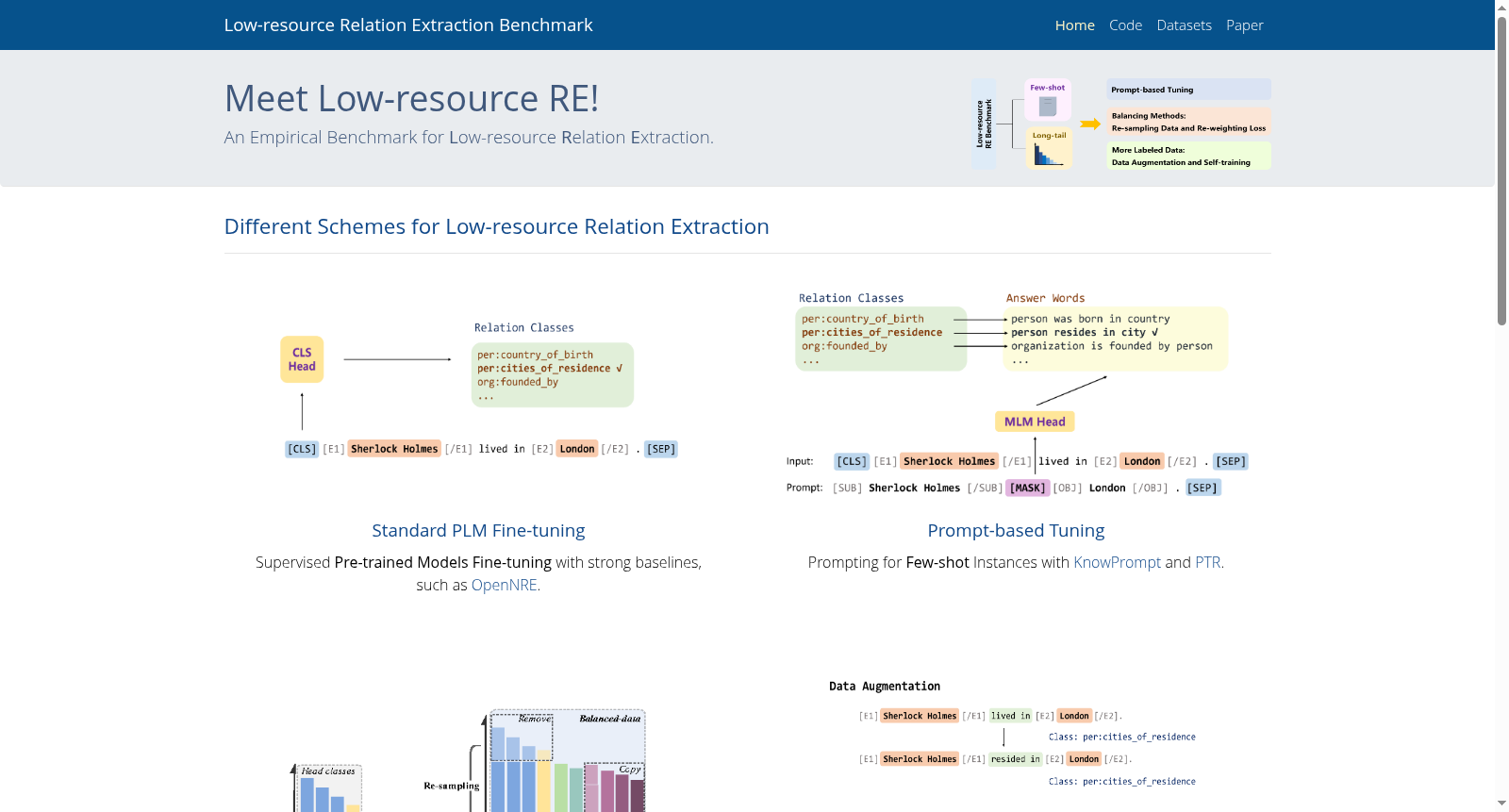
构建方式
在低资源关系抽取领域,LREBench的构建体现了对现实场景的深刻模拟。该数据集整合了八个涵盖不同语言、领域和上下文的关系抽取基准,包括SemEval、TACREV、Wiki80、SciERC、ChemProt、DialogRE、DuIE2.0和CMeIE。构建过程中,研究团队通过统一输入输出格式,将多关系三元组的文本拆分为独立实例,确保模型评估的一致性。为模拟低资源条件,数据集设计了8-shot、10%和100%三种训练数据比例,并通过五次随机采样以增强结果的稳定性,从而为低资源关系抽取提供了全面且可靠的实验平台。
使用方法
使用LREBench时,研究者可基于预训练语言模型(如RoBERTa-large、BioBERT-large)进行标准微调或提示学习。数据集支持三种实验设置:极低资源的8-shot、中等资源的10%标注数据以及全量数据的100%设置,以全面评估模型在不同资源水平下的表现。评估时需采用Macro F1和Micro F1指标,以兼顾长尾分布中头尾类别的性能平衡。此外,用户可结合数据增强、重采样或重加权损失等方法,探索模型在应对数据稀疏和分布不均衡问题时的优化策略,推动低资源关系抽取技术的实际应用。
背景与挑战
背景概述
LREBench作为低资源关系抽取领域的基准数据集,由浙江大学与腾讯等机构的研究团队于2023年联合构建。该数据集旨在应对现实场景中标注数据稀缺的挑战,核心研究问题聚焦于在有限标注样本下提升关系抽取模型的泛化能力。通过整合涵盖多语言、多领域及多上下文的八种关系抽取数据集,LREBench系统评估了提示学习、长尾分布平衡及数据增强等关键方法,为低资源自然语言处理研究提供了重要的实证基础,推动了信息抽取技术在真实工业环境中的应用演进。
当前挑战
LREBench所针对的低资源关系抽取任务面临多重挑战:在领域问题层面,模型需克服标注数据极端稀疏与长尾分布带来的性能衰减,尤其在跨句子上下文及多关系三元组抽取中表现显著困难;构建过程中,数据集需统一异构数据的格式与评估标准,并确保在少样本设定下实验的稳定性与可复现性。此外,特定领域术语的复杂性及伪标注噪声进一步增加了数据增强与自训练方法的优化难度,要求研究者在模型设计与资源利用间寻求更精细的平衡。
常用场景
经典使用场景
在自然语言处理领域,关系抽取任务常面临标注数据稀缺的挑战,LREBench数据集为此提供了系统性的评估基准。该数据集整合了涵盖多语言、多领域及多样化上下文的八个关系抽取数据集,如SemEval、TACREV和ChemProt等,支持在低资源设置下对提示学习、数据平衡及数据增强等方法进行实证研究。其经典使用场景包括在8-shot、10%和100%数据比例下,评估预训练语言模型在极端少样本和长尾分布情境中的泛化能力,为低资源关系抽取模型的开发与比较提供了标准化实验平台。
解决学术问题
LREBench致力于解决低资源关系抽取中的核心学术问题,包括在标注数据有限时模型性能显著下降的困境。通过系统评估提示学习、数据平衡技术和数据增强策略,该数据集揭示了提示学习在少样本场景中的优势,以及长尾分布下平衡方法的局限性。其意义在于首次为低资源关系抽取提供了全面实证分析,明确了跨句子上下文和多关系三元组抽取的挑战,推动了针对数据稀疏和类别不平衡问题的模型创新,为信息提取领域的实际应用奠定了理论基础。
实际应用
在实际应用层面,LREBench支持构建适用于真实场景的低资源关系抽取系统,尤其在医疗、科学和对话等领域。例如,在生物医学文本中提取化学物质与蛋白质的交互关系,或在多轮对话中识别实体间的语义关联。数据集的多语言特性(如中文DuIE2.0和CMeIE)进一步促进了跨语言信息提取工具的研发,帮助企业在标注成本高昂或数据分布不均的情况下,仍能实现高效的知识图谱构建和自动化信息处理,提升工业级自然语言处理系统的适应性与鲁棒性。
数据集最近研究
最新研究方向
在低资源关系抽取领域,LREBench数据集的最新研究聚焦于探索预训练语言模型在数据稀缺情境下的泛化能力。前沿方向主要围绕提示学习、长尾分布平衡以及数据增强技术的融合应用展开。研究揭示了提示学习在跨句子多关系三元组抽取中的潜力与局限,同时指出平衡方法在复杂语境下的不稳定性,而数据增强则展现出显著的性能提升空间。这些发现为低资源关系抽取模型的鲁棒性优化和实际部署提供了关键洞见,推动了信息抽取技术向更广泛的语言和领域迁移。
相关研究论文
- 1Towards Realistic Low-resource Relation Extraction: A Benchmark with Empirical Baseline Study浙江大学 & AZFT 联合实验室知识引擎 · 2023年
以上内容由遇见数据集搜集并总结生成


