Manga109
收藏arXiv2015-10-15 更新2024-06-21 收录
下载链接:
http://www.manga109.org
下载链接
链接失效反馈官方服务:
资源简介:
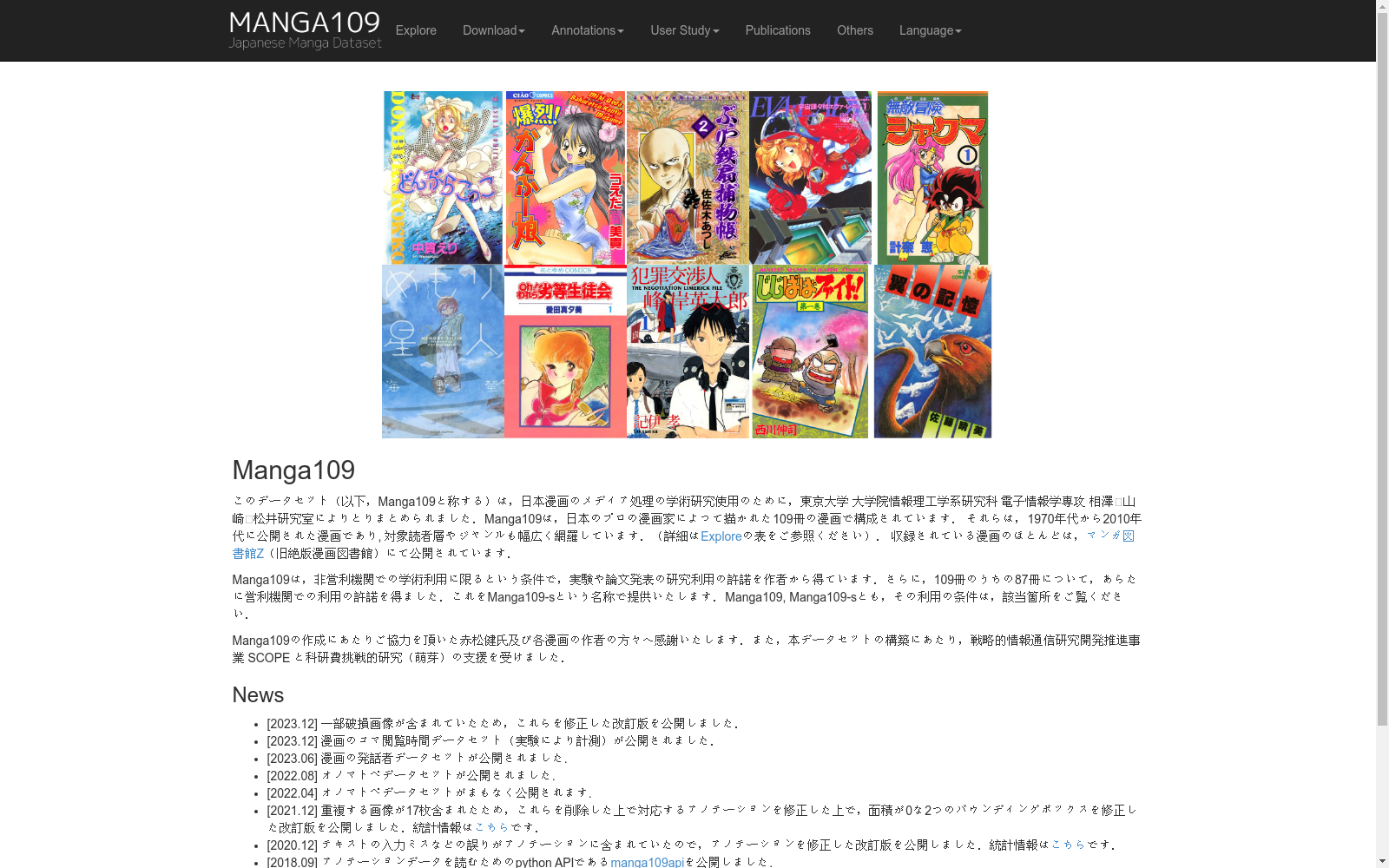
Manga109是由东京大学创建的大型漫画图像数据集,包含109部由专业漫画家绘制的漫画,总计21142页。该数据集通过与版权方合作,解决了版权问题,使得研究者可以自由使用高质量的漫画图像进行研究。数据集涵盖多种漫画类型,适用于漫画图像处理、检索和本地化等研究领域,旨在提升漫画搜索的直观性、效率和乐趣。
Manga109 is a large-scale comic image dataset developed by The University of Tokyo. It consists of 109 comics created by professional cartoonists, totaling 21,142 pages. Through collaboration with copyright holders, the copyright issues associated with this dataset have been resolved, allowing researchers to freely utilize high-quality comic images for their research. Covering a wide range of comic genres, this dataset is applicable to research fields including comic image processing, retrieval and localization, aiming to enhance the intuitiveness, efficiency and enjoyment of comic searching.
提供机构:
东京大学
创建时间:
2015-10-15
搜集汇总
数据集介绍
构建方式
Manga109数据集的构建基于对109部经典日本漫画的数字化处理。研究团队精心挑选了这些漫画作品,涵盖了从经典到现代的多个时期和风格。每部漫画都经过高分辨率扫描,并进行了详细的标注,包括角色、对话框、文本等元素的位置和属性。此外,数据集还包括了每部漫画的元数据,如作者、出版年份和故事情节概述,以提供更全面的上下文信息。
使用方法
Manga109数据集适用于多种研究场景,包括但不限于漫画内容理解、角色识别、对话框检测和文本提取。研究者可以通过访问数据集的官方网站下载图像和标注文件,并使用标准的图像处理工具和编程语言进行数据分析。此外,数据集还提供了API接口,方便研究者在深度学习框架中集成和使用。通过这些方法,研究者可以深入探索漫画的视觉和文本特征,推动相关领域的技术进步。
背景与挑战
背景概述
Manga109数据集由东京大学和日本国立情报学研究所于2017年联合发布,专注于日本漫画(Manga)的数字化和分析。该数据集包含了109部经典漫画作品,涵盖了从1970年代到2010年代的不同风格和主题。Manga109的发布标志着漫画研究领域的一个重要里程碑,为研究人员提供了丰富的视觉和文本数据,推动了漫画图像分析、文本识别和情感分析等方向的研究。
当前挑战
Manga109数据集在构建过程中面临了多重挑战。首先,漫画图像的复杂性和多样性使得图像分割和对象识别任务变得异常困难。其次,漫画中的文本识别需要处理手写体和印刷体的混合,增加了文本分析的复杂度。此外,漫画中的情感表达和叙事结构分析也对数据集的标注和分类提出了高要求。这些挑战不仅影响了数据集的质量,也对其在实际应用中的效果产生了深远影响。
发展历史
创建时间与更新
Manga109数据集由东京大学于2017年首次发布,旨在为漫画图像分析提供一个标准化的基准。该数据集自发布以来,经历了多次更新,最近一次更新是在2021年,增加了更多的漫画作品和详细的标注信息。
重要里程碑
Manga109的发布标志着漫画图像分析领域的一个重要里程碑。其首次引入的109部高质量漫画作品,涵盖了多种风格和主题,为研究人员提供了丰富的数据资源。此外,数据集中的详细标注,包括角色、对话框和背景元素等,极大地推动了漫画图像理解与分析技术的发展。随着时间的推移,Manga109不断扩展其内容和标注的深度,进一步巩固了其在该领域的核心地位。
当前发展情况
当前,Manga109数据集已成为漫画图像分析领域的标杆,广泛应用于各种研究项目和实际应用中。其丰富的内容和详细的标注不仅促进了学术研究,还为工业界提供了宝贵的资源,推动了漫画图像识别、理解和生成技术的发展。随着深度学习和计算机视觉技术的进步,Manga109的持续更新和扩展将继续为该领域带来新的突破和创新。
发展历程
- Manga109数据集首次发表,由东京大学和日本国立情报学研究所联合发布,旨在为漫画图像分析提供一个标准化的数据集。
- Manga109数据集首次应用于学术研究,特别是在计算机视觉和自然语言处理领域,推动了漫画内容理解和分析技术的发展。
- Manga109数据集的扩展版本发布,增加了更多的漫画样本和详细的标注信息,进一步提升了其在学术界的影响力。
- Manga109数据集被广泛应用于多个国际会议和竞赛中,成为评估和比较漫画分析算法性能的标准数据集之一。
常用场景
经典使用场景
在计算机视觉领域,Manga109数据集以其丰富的漫画图像资源而闻名。该数据集包含了109部日本漫画的扫描图像,涵盖了多种风格和主题。研究者常利用此数据集进行图像分割、对象检测和场景理解等任务,特别是在漫画图像的自动分析和理解方面。通过Manga109,研究者能够开发和验证各种算法,以实现对漫画内容的高效处理和分析。
解决学术问题
Manga109数据集在解决学术研究问题方面具有重要意义。它为研究者提供了一个标准化的测试平台,用于评估和改进图像处理算法在漫画领域的应用。例如,通过该数据集,研究者可以探索如何自动识别和分割漫画中的对话框、人物和背景元素,从而推动图像识别和自然语言处理技术的交叉应用。此外,Manga109还促进了跨文化图像分析的研究,为理解不同文化背景下的视觉表达提供了宝贵的数据资源。
实际应用
在实际应用中,Manga109数据集为漫画产业带来了诸多创新。例如,它支持开发自动化的漫画翻译工具,通过识别和处理漫画中的文本元素,实现多语言翻译的自动化。此外,该数据集还促进了漫画内容的数字化管理,帮助出版商和创作者更高效地组织和检索漫画资源。在教育和研究领域,Manga109也为学生和学者提供了丰富的素材,用于研究和教学活动。
数据集最近研究
最新研究方向
在动漫领域,Manga109数据集的最新研究方向主要集中在图像理解和文本识别的深度融合。研究者们致力于开发能够自动解析漫画图像中的复杂视觉元素和文本内容的算法,以实现更高层次的语义理解。这一方向的研究不仅推动了动漫图像分析技术的发展,也为跨模态信息处理提供了新的视角。通过结合先进的深度学习模型,如Transformer和卷积神经网络,研究者们期望能够提升漫画内容检索、分类和生成的能力,从而在动漫产业中引发深远的影响。
相关研究论文
- 1Manga109: A Large-scale Dataset of Manga with 109 TitlesUniversity of Tokyo · 2017年
- 2Manga OCR: A New Dataset and Baseline for Text Recognition in MangaUniversity of Tokyo · 2021年
- 3Manga Character Recognition Using Deep Learning TechniquesKyushu Institute of Technology · 2020年
- 4Exploring the Use of Manga109 Dataset for Scene Understanding in MangaUniversity of Tokyo · 2019年
- 5Manga109-s: A Dataset for Scene Understanding in MangaUniversity of Tokyo · 2022年
以上内容由遇见数据集搜集并总结生成


