turkish-fake-news-detection
收藏Hugging Face2024-07-10 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/ogozcelik/turkish-fake-news-detection
下载链接
链接失效反馈官方服务:
资源简介:
MiDe22数据集包含5,064条土耳其语推文,这些推文带有关于多个近期事件(如俄罗斯-乌克兰战争、COVID-19大流行和难民问题)的错误信息标签。数据集包括推文的用户互动数据,如点赞、回复、转发和引用。推文被标记为三个类别:True(正确信息)、False(错误信息)和Other(无法归类为True或False的信息)。数据集由五名标注者标注,每条推文至少由两名标注者标注,并通过Krippendorf’s alpha可靠性测量方法评估了标注者间的一致性。
The MiDe22 dataset includes 5,064 Turkish tweets annotated with misinformation labels related to several recent events, namely the Russia-Ukraine war, the COVID-19 pandemic, and the refugee crisis. The dataset contains user interaction data associated with the tweets, including likes, replies, retweets, and quote tweets. The tweets are categorized into three classes: True (correct information), False (misinformation), and Other (information that cannot be classified as either True or False). The dataset was annotated by five annotators, with each tweet being annotated by at least two annotators, and the inter-annotator agreement was evaluated using Krippendorf’s alpha reliability measure.
创建时间:
2024-07-10
原始信息汇总
MiDe22: An Annotated Multi-Event Tweet Dataset for Misinformation Detection
概述
- 数据集名称: MiDe22
- 任务类别: 文本分类
- 语言: 土耳其语
- 数据规模: 1K<n<10K
- 别名: mide22-tr
数据描述
- 数据量: 5,064条土耳其语推文
- 时间范围: 2020年至2022年
- 事件类型: 包括俄罗斯-乌克兰战争、COVID-19疫情、难民事件等
- 用户互动: 包括点赞、回复、转发和引用
数据字段
tweet: 字符串类型的推文内容label: 分类标签,可能值包括True,False,Other
数据规模
| 类别 | 真实 | 虚假 | 其他 |
|---|---|---|---|
| 推文 | 669 | 1,732 | 2,663 |
标注
- 标注类别: True, False, Other
True: 推文包含关于相应事件的正确信息False: 推文包含关于相应事件的错误信息Other: 推文无法归类为真实或虚假信息
标注过程
- 标注者数量: 5名
- 标注一致性: 每条推文至少由两名标注者标注,使用Krippendorf’s alpha系数衡量标注者间一致性,结果为0.791
数据来源
- GitHub仓库: MiDe22
- 论文: LREC-COLING 2024
引用
@inproceedings{toraman-etal-2024-mide22-annotated, title = "{M}i{D}e22: An Annotated Multi-Event Tweet Dataset for Misinformation Detection", author = "Toraman, Cagri and Ozcelik, Oguzhan and Sahinuc, Furkan and Can, Fazli", booktitle = "Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)", month = may, year = "2024", address = "Torino, Italia", publisher = "ELRA and ICCL", url = "https://aclanthology.org/2024.lrec-main.986", pages = "11283--11295", }
联系信息
- 邮箱: ogozcelik[at]gmail[dot]com
搜集汇总
数据集介绍
构建方式
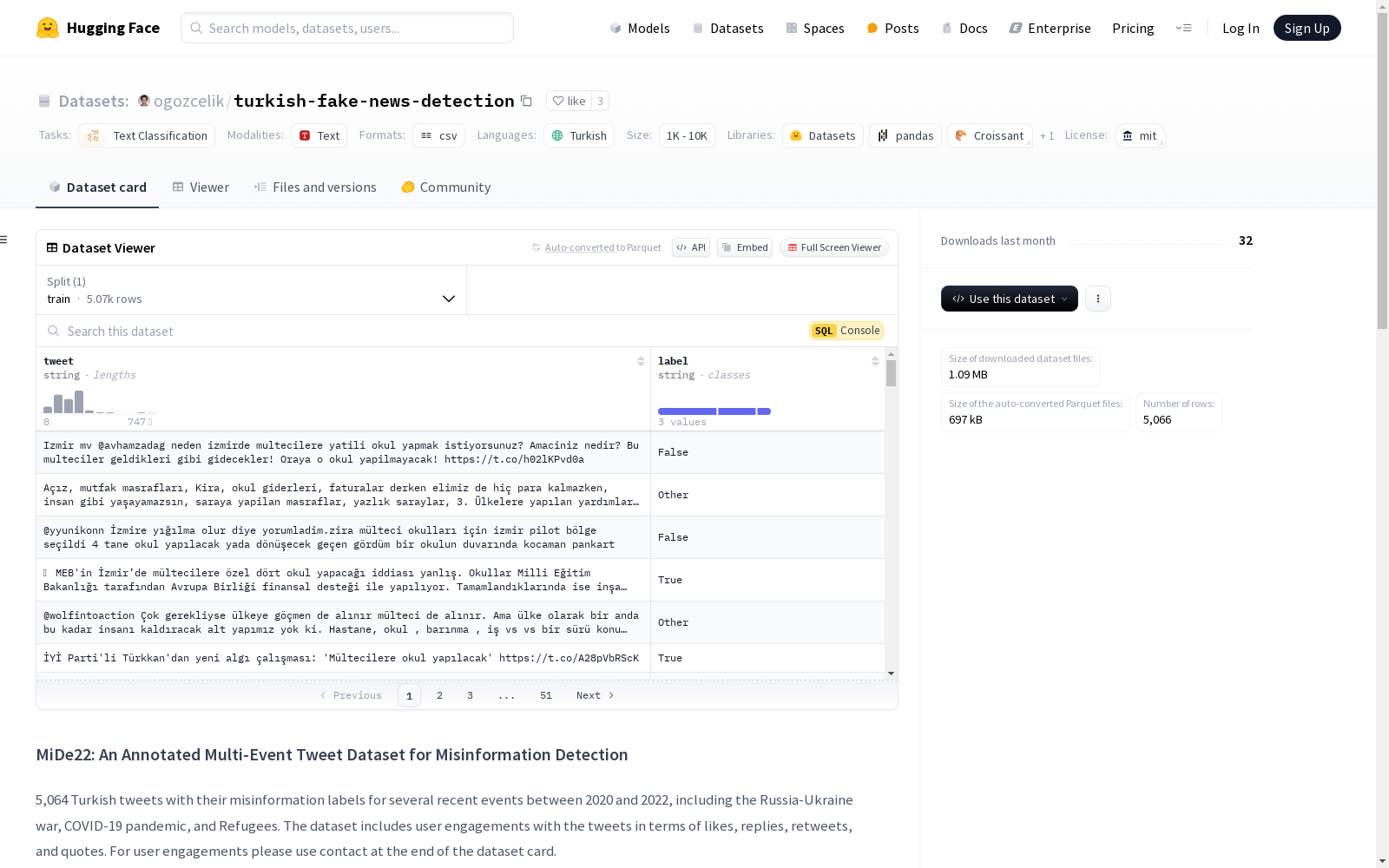
MiDe22数据集的构建过程基于2020年至2022年间多个重大事件的土耳其推文,包括俄乌战争、COVID-19疫情和难民问题。数据集由五位标注者共同完成,每条推文至少由两位标注者进行标注,并通过Krippendorf’s alpha系数(0.791)评估标注者间的一致性。推文被分为三类:真实信息、虚假信息和其他无法明确分类的信息。
特点
MiDe22数据集包含5,064条土耳其推文,每条推文均标注了其信息真实性,分为‘True’、‘False’和‘Other’三类。此外,数据集还记录了每条推文的用户互动数据,如点赞、回复、转发和引用。这种多事件、多类别的标注方式为研究虚假信息检测提供了丰富的语料支持。
使用方法
MiDe22数据集适用于文本分类任务,特别是虚假信息检测研究。用户可通过HuggingFace平台或GitHub仓库获取数据集,并利用其标注信息训练和评估模型。数据集中的用户互动数据可用于分析虚假信息的传播模式。引用时请遵循提供的引用格式,并可通过数据集卡片中的联系方式获取更多信息。
背景与挑战
背景概述
MiDe22数据集是由Cagri Toraman、Oguzhan Ozcelik、Furkan Sahinuc和Fazli Can等研究人员于2024年发布的一个土耳其语虚假新闻检测数据集。该数据集包含了2020年至2022年间与多个重大事件相关的5,064条土耳其推文,包括俄乌战争、COVID-19疫情和难民问题等。每条推文都标注了其信息真实性,分为“真实”、“虚假”和“其他”三类。该数据集的发布旨在为土耳其语社交媒体中的虚假信息检测提供高质量的训练和评估资源,推动了自然语言处理领域在虚假新闻检测方面的研究进展。
当前挑战
MiDe22数据集在构建过程中面临了多方面的挑战。首先,虚假信息的界定本身具有主观性,尤其是在涉及复杂事件时,如何准确标注推文的真实性成为一大难题。其次,土耳其语作为一种形态丰富的语言,其语法结构和词汇变化增加了文本处理的复杂性。此外,社交媒体文本的噪声问题,如拼写错误、缩写和非正式表达,进一步加大了数据清洗和标注的难度。尽管通过多标注者机制和Krippendorf’s alpha系数(0.791)确保了标注的一致性,但如何在未来扩展数据集规模并保持标注质量仍是一个亟待解决的问题。
常用场景
经典使用场景
在自然语言处理领域,turkish-fake-news-detection数据集主要用于土耳其语文本的分类任务,特别是在虚假新闻检测方面。该数据集包含了2020年至2022年间多个重大事件的土耳其推文,如俄乌战争、COVID-19疫情和难民问题,每条推文都标注了其信息的真实性。研究人员可以利用这些标注数据训练和评估机器学习模型,以提高对土耳其语虚假新闻的识别能力。
解决学术问题
turkish-fake-news-detection数据集解决了在土耳其语环境下虚假新闻检测的学术研究问题。通过提供大量标注数据,该数据集帮助研究人员开发更精确的分类模型,以区分真实信息、虚假信息和其他无法分类的内容。这不仅提升了土耳其语文本分类的技术水平,还为多语言虚假新闻检测提供了重要的参考和基准。
衍生相关工作
基于turkish-fake-news-detection数据集,许多相关研究工作得以展开。例如,研究人员开发了针对土耳其语的深度学习模型,用于虚假新闻检测和情感分析。此外,该数据集还促进了跨语言虚假新闻检测的研究,推动了多语言自然语言处理技术的发展。这些工作不仅丰富了学术界的知识库,也为实际应用提供了技术支持。
以上内容由遇见数据集搜集并总结生成


