EduardoPacheco/FoodSeg103
收藏Hugging Face2024-04-29 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/EduardoPacheco/FoodSeg103
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
size_categories:
- n<1K
task_categories:
- image-segmentation
task_ids:
- semantic-segmentation
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype: image
- name: classes_on_image
sequence: int64
- name: id
dtype: int64
splits:
- name: train
num_bytes: 1140887299.125
num_examples: 4983
- name: validation
num_bytes: 115180784.125
num_examples: 2135
download_size: 1254703923
dataset_size: 1256068083.25
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
# Dataset Card for FoodSeg103
## Table of Contents
- [Dataset Card for FoodSeg103](#dataset-card-for-foodseg103)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Dataset Structure](#dataset-structure)
- [Data categories](#data-categories)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Refinement process](#refinement-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** [Dataset homepage](https://xiongweiwu.github.io/foodseg103.html)
- **Repository:** [FoodSeg103-Benchmark-v1](https://github.com/LARC-CMU-SMU/FoodSeg103-Benchmark-v1)
- **Paper:** [A Large-Scale Benchmark for Food Image Segmentation](https://arxiv.org/pdf/2105.05409.pdf)
- **Point of Contact:** [Not Defined]
### Dataset Summary
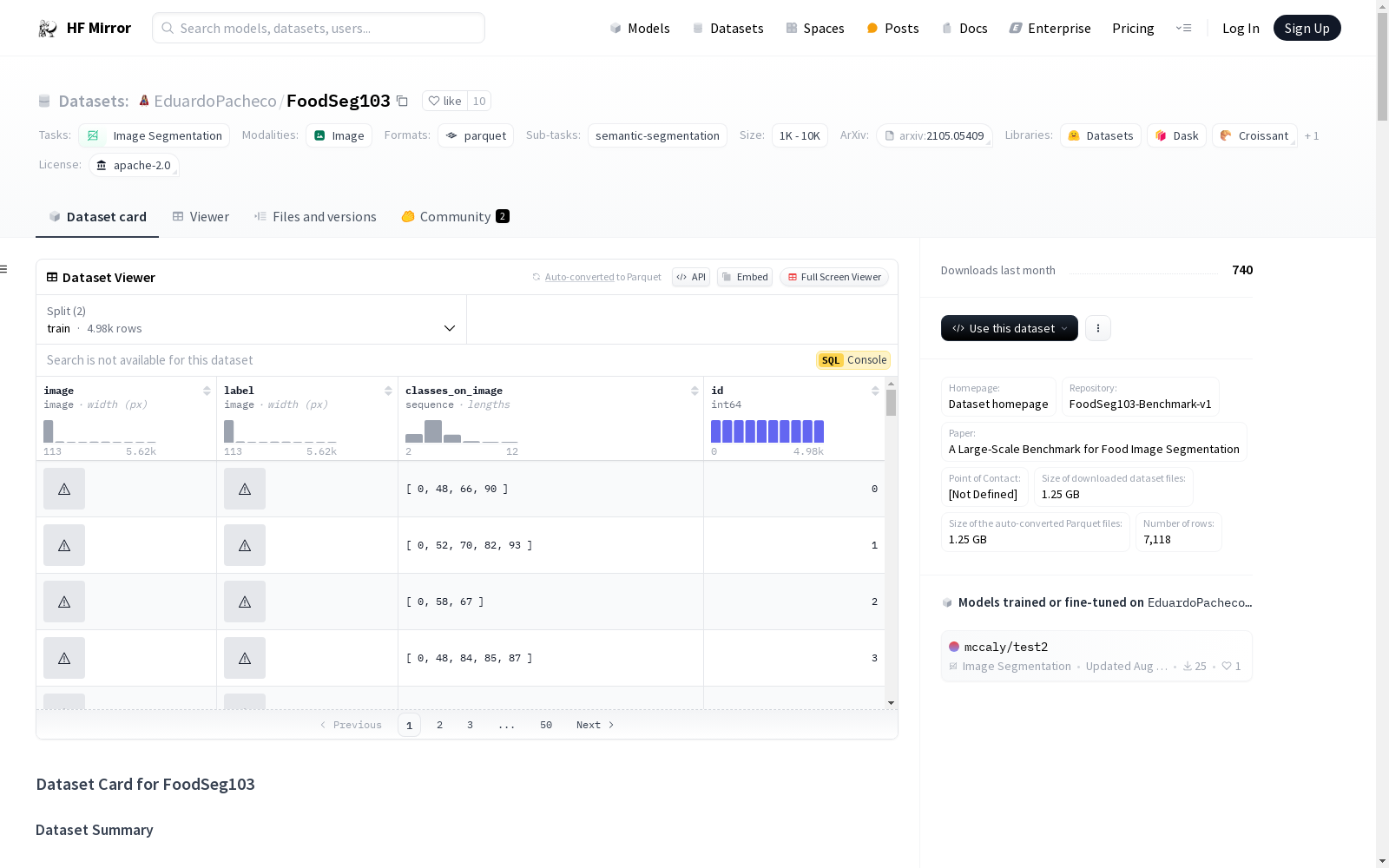
FoodSeg103 is a large-scale benchmark for food image segmentation. It contains 103 food categories and 7118 images with ingredient level pixel-wise annotations. The dataset is a curated sample from [Recipe1M](https://github.com/facebookresearch/inversecooking) and annotated and refined by human annotators. The dataset is split into 2 subsets: training set, validation set. The training set contains 4983 images and the validation set contains 2135 images.
### Supported Tasks and Leaderboards
No leaderboard is available for this dataset at the moment.
## Dataset Structure
### Data categories
| id | ingridient |
| --- | ---- |
| 0 | background |
| 1 | candy |
| 2 | egg tart |
| 3 | french fries |
| 4 | chocolate |
| 5 | biscuit |
| 6 | popcorn |
| 7 | pudding |
| 8 | ice cream |
| 9 | cheese butter |
| 10 | cake |
| 11 | wine |
| 12 | milkshake |
| 13 | coffee |
| 14 | juice |
| 15 | milk |
| 16 | tea |
| 17 | almond |
| 18 | red beans |
| 19 | cashew |
| 20 | dried cranberries |
| 21 | soy |
| 22 | walnut |
| 23 | peanut |
| 24 | egg |
| 25 | apple |
| 26 | date |
| 27 | apricot |
| 28 | avocado |
| 29 | banana |
| 30 | strawberry |
| 31 | cherry |
| 32 | blueberry |
| 33 | raspberry |
| 34 | mango |
| 35 | olives |
| 36 | peach |
| 37 | lemon |
| 38 | pear |
| 39 | fig |
| 40 | pineapple |
| 41 | grape |
| 42 | kiwi |
| 43 | melon |
| 44 | orange |
| 45 | watermelon |
| 46 | steak |
| 47 | pork |
| 48 | chicken duck |
| 49 | sausage |
| 50 | fried meat |
| 51 | lamb |
| 52 | sauce |
| 53 | crab |
| 54 | fish |
| 55 | shellfish |
| 56 | shrimp |
| 57 | soup |
| 58 | bread |
| 59 | corn |
| 60 | hamburg |
| 61 | pizza |
| 62 | hanamaki baozi |
| 63 | wonton dumplings |
| 64 | pasta |
| 65 | noodles |
| 66 | rice |
| 67 | pie |
| 68 | tofu |
| 69 | eggplant |
| 70 | potato |
| 71 | garlic |
| 72 | cauliflower |
| 73 | tomato |
| 74 | kelp |
| 75 | seaweed |
| 76 | spring onion |
| 77 | rape |
| 78 | ginger |
| 79 | okra |
| 80 | lettuce |
| 81 | pumpkin |
| 82 | cucumber |
| 83 | white radish |
| 84 | carrot |
| 85 | asparagus |
| 86 | bamboo shoots |
| 87 | broccoli |
| 88 | celery stick |
| 89 | cilantro mint |
| 90 | snow peas |
| 91 | cabbage |
| 92 | bean sprouts |
| 93 | onion |
| 94 | pepper |
| 95 | green beans |
| 96 | French beans |
| 97 | king oyster mushroom |
| 98 | shiitake |
| 99 | enoki mushroom |
| 100 | oyster mushroom |
| 101 | white button mushroom |
| 102 | salad |
| 103 | other ingredients |
### Data Splits
This dataset only contains two splits. A training split and a validation split with 4983 and 2135 images respectively.
## Dataset Creation
### Curation Rationale
Select images from a large-scale recipe dataset and annotate them with pixel-wise segmentation masks.
### Source Data
The dataset is a curated sample from [Recipe1M](https://github.com/facebookresearch/inversecooking).
#### Initial Data Collection and Normalization
After selecting the source of the data two more steps were added before image selection.
1. Recipe1M contains 1.5k ingredient categoris, but only the top 124 categories were selected + a 'other' category (further became 103).
2. Images should contain between 2 and 16 ingredients.
3. Ingredients should be visible and easy to annotate.
Which then resulted in 7118 images.
### Annotations
#### Annotation process
Third party annotators were hired to annotate the images respecting the following guidelines:
1. Tag ingredients with appropriate categories.
2. Draw pixel-wise masks for each ingredient.
3. Ignore tiny regions (even if contains ingredients) with area covering less than 5% of the image.
#### Refinement process
The refinement process implemented the following steps:
1. Correct mislabelled ingredients.
2. Deleting unpopular categories that are assigned to less than 5 images (resulting in 103 categories in the final dataset).
3. Merging visually similar ingredient categories (e.g. orange and citrus)
#### Who are the annotators?
A third party company that was not mentioned in the paper.
## Additional Information
### Dataset Curators
Authors of the paper [A Large-Scale Benchmark for Food Image Segmentation](https://arxiv.org/pdf/2105.05409.pdf).
### Licensing Information
[Apache 2.0 license.](https://github.com/LARC-CMU-SMU/FoodSeg103-Benchmark-v1/blob/main/LICENSE)
### Citation Information
```bibtex
@inproceedings{wu2021foodseg,
title={A Large-Scale Benchmark for Food Image Segmentation},
author={Wu, Xiongwei and Fu, Xin and Liu, Ying and Lim, Ee-Peng and Hoi, Steven CH and Sun, Qianru},
booktitle={Proceedings of ACM international conference on Multimedia},
year={2021}
}
```
---
许可证:Apache 2.0
规模类别:
- 样本量小于1000
任务类别:
- 图像分割(image-segmentation)
任务子类别:
- 语义分割(semantic-segmentation)
数据集信息:
特征字段:
- 字段名:图像,数据类型:图像
- 字段名:标签,数据类型:图像
- 字段名:图像包含的类别,类型为int64序列
- 字段名:样本ID,数据类型:int64
数据划分:
- 划分名称:训练集,占用字节数:1140887299.125,样本数:4983
- 划分名称:验证集,占用字节数:115180784.125,样本数:2135
下载总大小:1254703923字节
数据集总大小:1256068083.25字节
配置项:
- 配置名称:默认配置
数据文件:
- 划分:训练集,路径:data/train-*
- 划分:验证集,路径:data/validation-*
---
# FoodSeg103数据集卡片
## 目录
- [FoodSeg103数据集卡片](#foodseg103数据集卡片)
- [目录](#目录)
- [数据集描述](#数据集描述)
- [数据集概述](#数据集概述)
- [支持任务与排行榜](#支持任务与排行榜)
- [数据集结构](#数据集结构)
- [数据类别](#数据类别)
- [数据划分](#数据划分)
- [数据集构建](#数据集构建)
- [构建初衷](#构建初衷)
- [源数据](#源数据)
- [初始数据收集与归一化](#初始数据收集与归一化)
- [标注信息](#标注信息)
- [标注流程](#标注流程)
- [优化流程](#优化流程)
- [标注人员构成](#标注人员构成)
- [附加信息](#附加信息)
- [数据集策展人](#数据集策展人)
- [许可证信息](#许可证信息)
- [引用信息](#引用信息)
## 数据集描述
- **主页**:[数据集主页](https://xiongweiwu.github.io/foodseg103.html)
- **代码仓库**:[FoodSeg103-Benchmark-v1](https://github.com/LARC-CMU-SMU/FoodSeg103-Benchmark-v1)
- **相关论文**:[A Large-Scale Benchmark for Food Image Segmentation](https://arxiv.org/pdf/2105.05409.pdf)
- **联系人**:[未定义]
### 数据集概述
FoodSeg103是一款面向食品图像分割的大规模基准数据集,涵盖103类食品类别,共7118张带有食材级逐像素标注的图像。该数据集从Recipe1M(Recipe1M)中精选得到,并由人工标注者完成标注与优化。数据集划分为训练集与验证集两个子集,其中训练集包含4983张图像,验证集包含2135张图像。
### 支持任务与排行榜
目前该数据集暂无官方排行榜。
## 数据集结构
### 数据类别
| 类别ID | 食材名称 |
| --- | ---- |
| 0 | 背景 |
| 1 | 糖果 |
| 2 | 蛋挞 |
| 3 | 薯条 |
| 4 | 巧克力 |
| 5 | 饼干 |
| 6 | 爆米花 |
| 7 | 布丁 |
| 8 | 冰淇淋 |
| 9 | 芝士黄油 |
| 10 | 蛋糕 |
| 11 | 葡萄酒 |
| 12 | 奶昔 |
| 13 | 咖啡 |
| 14 | 果汁 |
| 15 | 牛奶 |
| 16 | 茶 |
| 17 | 杏仁 |
| 18 | 红豆 |
| 19 | 腰果 |
| 20 | 蔓越莓干 |
| 21 | 大豆 |
| 22 | 核桃 |
| 23 | 花生 |
| 24 | 鸡蛋 |
| 25 | 苹果 |
| 26 | 枣 |
| 27 | 杏 |
| 28 | 牛油果 |
| 29 | 香蕉 |
| 30 | 草莓 |
| 31 | 樱桃 |
| 32 | 蓝莓 |
| 33 | 树莓 |
| 34 | 芒果 |
| 35 | 橄榄 |
| 36 | 桃 |
| 37 | 柠檬 |
| 38 | 梨 |
| 39 | 无花果 |
| 40 | 菠萝 |
| 41 | 葡萄 |
| 42 | 猕猴桃 |
| 43 | 甜瓜 |
| 44 | 橙子 |
| 45 | 西瓜 |
| 46 | 牛排 |
| 47 | 猪肉 |
| 48 | 鸡鸭 |
| 49 | 香肠 |
| 50 | 煎炒肉类 |
| 51 | 羊肉 |
| 52 | 酱汁 |
| 53 | 螃蟹 |
| 54 | 鱼肉 |
| 55 | 贝类 |
| 56 | 虾 |
| 57 | 汤品 |
| 58 | 面包 |
| 59 | 玉米 |
| 60 | 汉堡 |
| 61 | 披萨 |
| 62 | 花卷包子 |
| 63 | 馄饨饺子 |
| 64 | 意面 |
| 65 | 面条 |
| 66 | 米饭 |
| 67 | 派 |
| 68 | 豆腐 |
| 69 | 茄子 |
| 70 | 土豆 |
| 71 | 大蒜 |
| 72 | 花椰菜 |
| 73 | 番茄 |
| 74 | 海带 |
| 75 | 海藻 |
| 76 | 小葱 |
| 77 | 油菜 |
| 78 | 生姜 |
| 79 | 秋葵 |
| 80 | 生菜 |
| 81 | 南瓜 |
| 82 | 黄瓜 |
| 83 | 白萝卜 |
| 84 | 胡萝卜 |
| 85 | 芦笋 |
| 86 | 竹笋 |
| 87 | 西兰花 |
| 88 | 西芹 |
| 89 | 香菜薄荷 |
| 90 | 荷兰豆 |
| 91 | 卷心菜 |
| 92 | 豆芽 |
| 93 | 洋葱 |
| 94 | 辣椒 |
| 95 | 青豆 |
| 96 | 四季豆 |
| 97 | 杏鲍菇 |
| 98 | 香菇 |
| 99 | 金针菇 |
| 100 | 蚝菇 |
| 101 | 双孢菇 |
| 102 | 沙拉 |
| 103 | 其他食材 |
### 数据划分
该数据集仅包含两个划分:训练集与验证集,分别包含4983张与2135张图像。
## 数据集构建
### 构建初衷
从大规模食谱数据集中遴选图像,并为其添加逐像素分割掩码标注。
### 源数据
该数据集从Recipe1M(Recipe1M)中精选得到。
#### 初始数据收集与归一化
在选定数据源后,在图像遴选前还需完成以下三步预处理:
1. Recipe1M(Recipe1M)原包含1500种食材类别,仅选取排名前124的类别并新增“其他”类别(最终精简为103类);
2. 图像需包含2至16种食材;
3. 食材需清晰可见且易于标注。
最终共得到7118张图像。
### 标注信息
#### 标注流程
聘请第三方标注人员按照以下规范完成标注:
1. 为食材匹配对应类别标签;
2. 为每一类食材绘制逐像素掩码;
3. 忽略占图像总面积不足5%的微小区域(即使其中包含食材)。
#### 优化流程
优化流程包含以下步骤:
1. 修正标注错误的食材类别;
2. 删除标注样本少于5张的冷门类别(最终确定103类食材);
3. 合并视觉相似的食材类别(例如橙子与柑橘类)。
#### 标注人员构成
标注工作由论文未提及的第三方公司完成。
## 附加信息
### 数据集策展人
论文《A Large-Scale Benchmark for Food Image Segmentation》的作者。
### 许可证信息
采用Apache 2.0许可证,详情参见[仓库许可证文件](https://github.com/LARC-CMU-SMU/FoodSeg103-Benchmark-v1/blob/main/LICENSE)。
### 引用信息
bibtex
@inproceedings{wu2021foodseg,
title={A Large-Scale Benchmark for Food Image Segmentation},
author={Wu, Xiongwei and Fu, Xin and Liu, Ying and Lim, Ee-Peng and Hoi, Steven CH and Sun, Qianru},
booktitle={Proceedings of ACM international conference on Multimedia},
year={2021}
}
提供机构:
EduardoPacheco
原始信息汇总
数据集概述
数据集名称
- 名称: FoodSeg103
数据集描述
- 描述: FoodSeg103是一个大规模的食物图像分割基准数据集,包含103个食物类别和7118张图像,这些图像具有成分级别的像素级标注。数据集是从Recipe1M中精选并由人工标注和细化。
数据集结构
- 特征:
- image: 图像数据
- label: 图像标签
- classes_on_image: 图像上的类别序列,数据类型为int64
- id: 数据集中的ID,数据类型为int64
- 数据分割:
- 训练集: 包含4983张图像,总大小为1140887299.125字节
- 验证集: 包含2135张图像,总大小为115180784.125字节
数据集类别
- 类别列表: 包括背景、糖果、蛋挞、薯条等103个类别。
数据集创建
- 来源: 数据集是从Recipe1M中精选而来。
- 标注过程: 第三方标注者根据以下指南进行标注:
- 标记成分与适当的类别
- 为每个成分绘制像素级掩码
- 忽略面积小于图像5%的微小区域
- 细化过程: 包括纠正错误标签、删除不常用类别、合并视觉上相似的成分类别。
许可证
- 许可证: Apache-2.0
引用信息
bibtex @inproceedings{wu2021foodseg, title={A Large-Scale Benchmark for Food Image Segmentation}, author={Wu, Xiongwei and Fu, Xin and Liu, Ying and Lim, Ee-Peng and Hoi, Steven CH and Sun, Qianru}, booktitle={Proceedings of ACM international conference on Multimedia}, year={2021} }
搜集汇总
数据集介绍
构建方式
FoodSeg103数据集的构建始于从Recipe1M数据集中精选出符合特定标准的图像。首先,从Recipe1M的1.5k种食材类别中筛选出前124种,并增加一个‘其他’类别,最终形成103种食材类别。其次,选择包含2至16种食材且易于标注的图像,共计7118张。随后,通过第三方标注公司进行像素级标注,确保每个食材的区域被准确标记。最后,通过一系列的精炼过程,包括纠正错误标注、删除不常用的类别以及合并视觉上相似的类别,确保数据集的高质量。
特点
FoodSeg103数据集的主要特点在于其大规模和高精度。该数据集包含103种食材类别,覆盖了广泛的食品种类,适用于复杂的图像分割任务。其7118张图像均经过像素级标注,确保了标注的精细度和准确性。此外,数据集的分割设计合理,包含4983张训练图像和2135张验证图像,为模型训练和评估提供了良好的数据基础。
使用方法
FoodSeg103数据集主要用于食品图像的语义分割任务。用户可以通过加载数据集中的图像和对应的标注图像进行模型训练。数据集提供了详细的分割信息,包括每个图像中出现的食材类别及其对应的像素级掩码。用户可以根据需要选择训练集或验证集进行实验,利用这些数据训练和评估食品图像分割模型。此外,数据集的结构清晰,便于用户进行数据预处理和模型集成。
背景与挑战
背景概述
FoodSeg103数据集是由Wu, Xiongwei等人于2021年创建的一个大规模食品图像分割基准。该数据集包含103个食品类别和7118张图像,每张图像都带有成分级别的像素级标注。FoodSeg103是从Recipe1M数据集中精选出来的,并由第三方标注公司进行了详细的标注和优化。该数据集的创建旨在推动食品图像分割领域的发展,为研究人员提供一个高质量的基准数据集。通过提供详细的成分标注,FoodSeg103不仅有助于提升图像分割算法的性能,还为食品识别和分析提供了宝贵的资源。
当前挑战
FoodSeg103数据集在构建过程中面临了多项挑战。首先,从Recipe1M数据集中筛选出符合条件的图像是一个复杂的过程,需要确保图像中的成分数量和可见性。其次,像素级标注的准确性要求极高,标注过程中需要严格遵循标注指南,以避免错误标注。此外,数据集的优化过程涉及删除不受欢迎的类别和合并视觉相似的成分类别,这增加了数据处理的复杂性。最后,尽管FoodSeg103提供了丰富的标注信息,但其规模相对较小,可能限制了其在某些深度学习模型训练中的应用效果。
常用场景
经典使用场景
在食品图像分析领域,FoodSeg103数据集的经典使用场景主要集中在食品图像的语义分割任务上。该数据集通过提供103种食品类别的高质量像素级标注,使得研究人员能够训练和评估食品图像分割模型。这些模型可以精确识别和分割图像中的各种食品成分,从而为食品识别、营养分析和烹饪建议等应用提供基础支持。
实际应用
在实际应用中,FoodSeg103数据集被广泛用于开发智能食品识别系统、营养分析工具和个性化烹饪建议平台。例如,餐饮行业可以利用该数据集训练的模型来快速识别和分类食材,提高供应链管理的效率;健康管理应用则可以通过分析食品图像中的成分,为用户提供个性化的营养建议和饮食计划。
衍生相关工作
基于FoodSeg103数据集,研究者们开发了多种先进的食品图像分割算法,并在多个国际会议上发表了相关论文。例如,Wu等人提出的基于深度学习的食品图像分割模型,显著提升了分割精度和效率。此外,该数据集还被用于训练和评估其他食品相关任务的模型,如食品识别、食品推荐系统等,进一步推动了食品图像分析领域的发展。
以上内容由遇见数据集搜集并总结生成


