TextDiffuser-MARIO-10M
收藏TextDiffuser-MARIO-10M 数据集概述
数据集描述
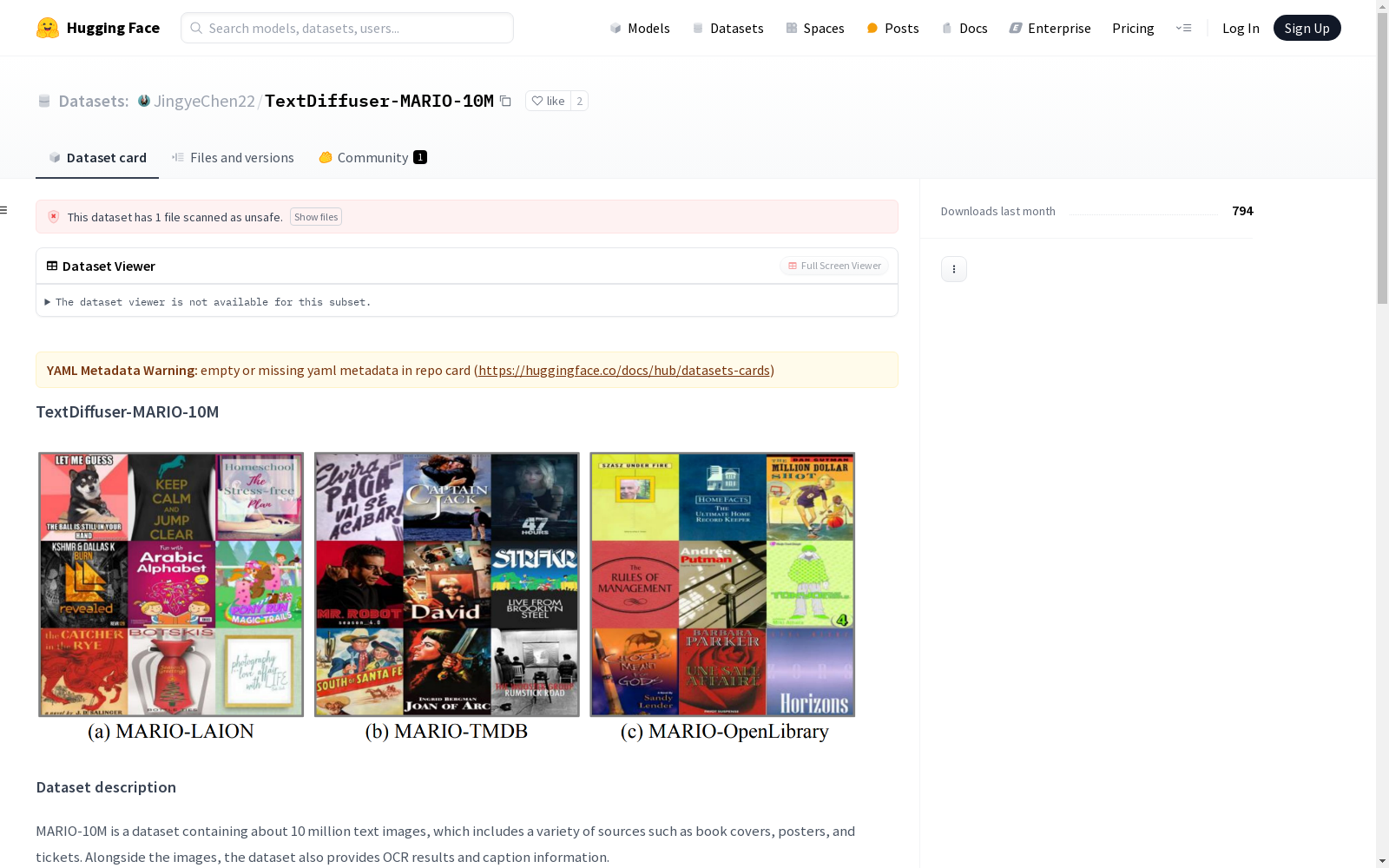
MARIO-10M 是一个包含约1000万张文本图像的数据集,这些图像来自多种来源,如书籍封面、海报和票据。数据集不仅包含图像,还提供了OCR结果和描述信息。
下载步骤
数据集的下载过程包括三个步骤:
-
下载所有tar文件 bash for i in {0..500}; do wget -O $i.tar.gz https://huggingface.co/datasets/JingyeChen22/TextDiffuser-MARIO-10M/resolve/main/$i.tar.gz?download=true; done
-
解压顶级目录 bash for i in {0..500}; do tar -xvf $i.tar.gz --strip-components=5 && rm $i.tar.gz; done
-
解压次级目录 bash for i in {0..500}; do cd $i && for file in *.tar.gz; do tar -xvf "$file" --strip-components=5 && rm $file; done; cd ..; done
最终的目录结构如下: bash MARIO-10M/ │ ├── 0/ │ ├── 00000/ │ ├──── 000000012/ │ ├──────── caption.txt │ ├──────── charseg.npy │ ├──────── image.jpg │ ├──────── info.json │ ├──────── ocr.txt ...
引用
如果在研究中使用了MARIO数据集,请引用以下论文:
@article{chen2024textdiffuser, title={Textdiffuser: Diffusion models as text painters}, author={Chen, Jingye and Huang, Yupan and Lv, Tengchao and Cui, Lei and Chen, Qifeng and Wei, Furu}, journal={Advances in Neural Information Processing Systems}, volume={36}, year={2024} }
@article{chen2023textdiffuser, title={Textdiffuser-2: Unleashing the power of language models for text rendering}, author={Chen, Jingye and Huang, Yupan and Lv, Tengchao and Cui, Lei and Chen, Qifeng and Wei, Furu}, journal={arXiv preprint arXiv:2311.16465}, year={2023} }