swimmiing/VGGSynth1
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/swimmiing/VGGSynth1
下载链接
链接失效反馈官方服务:
资源简介:
VGGSynth1是VGGSound数据集的高保真合成克隆,采用最先进的生成模型构建。该数据集旨在探索合成数据在训练音频-视觉声源定位(SSL)模型中的边界和实用性。视觉部分通过Stable Diffusion 3(SD3)生成,音频部分通过Stable Audio生成。
VGGSynth1 is a high-fidelity synthetic clone of the VGGSound dataset, built using state-of-the-art generative models. This dataset is designed to explore the boundaries and utility of synthetic data in training models for Audio-Visual Sound Source Localization (SSL). Visuals are generated via Stable Diffusion 3 (SD3), and audio is generated via Stable Audio.
提供机构:
swimmiing
搜集汇总
数据集介绍
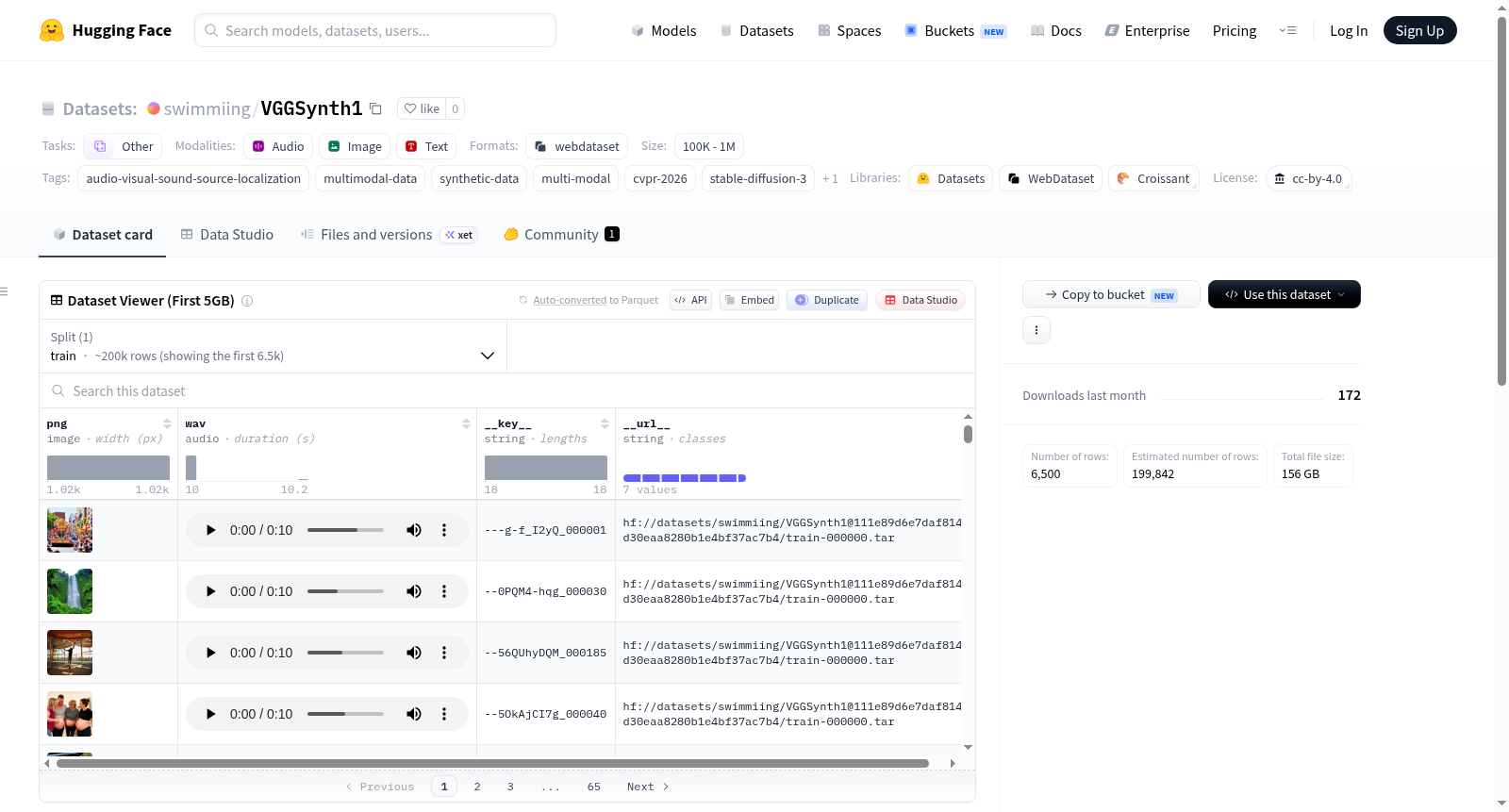
构建方式
VGGSynth1作为VGGSound数据集的高保真合成克隆版本,其构建方式充分体现了前沿生成式模型的协同应用。在视觉模态方面,研究团队采用Stable Diffusion 3(SD3)模型,依据原数据集中的语义标签与场景描述,逐帧生成与真实场景高度一致的图像内容。在听觉模态上,则借助Stable Audio模型,基于对应事件的声学特征与标签信息,合成了具有空间感和真实度的音频信号。两个模态的生成过程保持严格的时序与语义对齐,从而确保了音视频数据在时间与内容维度上的精准耦合。最终,通过自动化流程将上述生成的视觉与听觉样本配对整合,形成了首个专为音视频声源定位研究设计的大规模合成数据集。
使用方法
VGGSynth1的使用方法遵循标准的音视频多模态数据处理流程。用户可直接通过HuggingFace Datasets库加载该数据集,利用其内置的音频波形与图像张量接口进行模型输入构建。对于音视频声源定位任务,推荐将配对的音频频谱图与视频帧作为双流网络的输入,以监督学习方式预测声音在视觉场中的空间位置。同时,由于数据集提供了纯净的合成环境,研究者可将其作为预训练数据,在下游真实场景数据上进行微调,以评估合成数据对定位精度的提升效益。此外,该数据集也适用于跨模态对齐、视听表征学习等研究方向,具备良好的扩展性与兼容性。
背景与挑战
背景概述
VGGSynth1是由Arda Senocak、Sooyoung Park、Tae-Hyun Oh及Joon Son Chung等人于2026年联合创建的高保真合成视听数据集,作为VGGSound数据集的合成克隆,旨在探索合成数据在视听声源定位(SSL)任务中的极致效用。该研究发表于CVPR 2026,利用Stable Diffusion 3生成视觉内容,Stable Audio生成音频信号,构建了完全由合成样本构成的基准资源。其核心贡献在于打破真实数据采集的瓶颈,为多模态感知领域提供可扩展的合成数据范式,显著推动了SSL任务在无标注真实场景下的模型泛化能力研究。
当前挑战
数据集面临的核心挑战在于:1)领域问题层面,视听声源定位任务长期依赖真实采集数据,但真实场景中声源与视觉信号的多模态对齐标注成本高昂,且存在隐私与版权限制,VGGSynth1需验证合成数据能否弥合与真实数据间的语义鸿沟。2)构建过程中,利用生成模型同步合成高保真视听对面临跨模态一致性难题,例如SD3生成的图像与Stable Audio生成的音频在时序和语义上的精准对齐极具技术挑战,需设计复杂的生成调度策略以避免模态间的幻觉与错位。
常用场景
经典使用场景
在视听源定位(Audio-Visual Sound Source Localization)领域,VGGSynth1作为VGGSound的高保真合成克隆版本,被广泛用于训练和评估多模态模型。该数据集通过Stable Diffusion 3生成视觉内容,并由Stable Audio生成对应的音频信号,确保视听模态之间的自然对齐。研究者利用该数据集探索合成数据在模拟真实场景中的有效性,特别是在缺乏大规模真实标注数据的情况下,VGGSynth1为训练稳健的定位模型提供了替代方案。其高精度的合成质量使得模型能够学习从音频信号中定位图像中发声物体的空间位置,成为该领域标准化的基准测试平台。
解决学术问题
VGGSynth1核心解决了由于真实多模态数据标注成本高昂、隐私限制及场景多样性不足所引发的学术难题。传统视听定位任务依赖大量人工标注的视听配对数据,而合成数据的引入突破了这一瓶颈,使得研究者能够在不依赖真实环境采集的情况下,系统性探讨数据质量、模态对齐精度对定位性能的影响。该数据集揭示了合成数据在减少领域差异、提升模型泛化能力方面的潜力,推动了视听定位从数据密集型向数据高效型研究范式的转变,为后续小样本学习、跨域迁移等方向奠定了理论和实验基础。
实际应用
在实际应用中,VGGSynth1训练出的模型可部署于智能监控系统,实现基于音频线索自动锁定视频中的关键声源(如报警器、人声或机械故障声),提升安防场景的事件响应效率。在机器人交互领域,该技术赋予机器人根据环境音频定位目标的能力,例如在嘈杂家庭环境中识别并走向发出呼唤的人员。此外,在沉浸式媒体制作中,合成数据训练的模型能够辅助自动生成与视觉内容精确同步的音频空间信息,优化虚拟现实和增强现实中的声场渲染,提升用户体验的真实感。
数据集最近研究
最新研究方向
当前,随着生成式人工智能的飞速迭代,利用合成数据驱动多模态感知任务已成为前沿热点。VGGSynth1正是在这一浪潮中应运而生的高保真合成音视频数据集,通过Stable Diffusion 3与Stable Audio模型对经典VGGSound数据集进行了忠实克隆,旨在系统性地探讨合成数据在音视频声源定位(SSL)中的潜力与边界。该研究在CVPR 2026上以Highlight论文形式亮相,标志着合成数据在视觉-听觉联合推理任务中迈出了决定性的一步,不仅为缓解真实数据标注成本高、隐私风险大等瓶颈提供了全新范式,更推动了无监督与跨模态对齐技术迈向更普适的解决方案,对智能感知系统的自主进化具有深远意义。
以上内容由遇见数据集搜集并总结生成


