CoNLL 2000
收藏www.cnts.ua.ac.be2024-11-02 收录
下载链接:
http://www.cnts.ua.ac.be/conll2000/chunking/
下载链接
链接失效反馈官方服务:
资源简介:
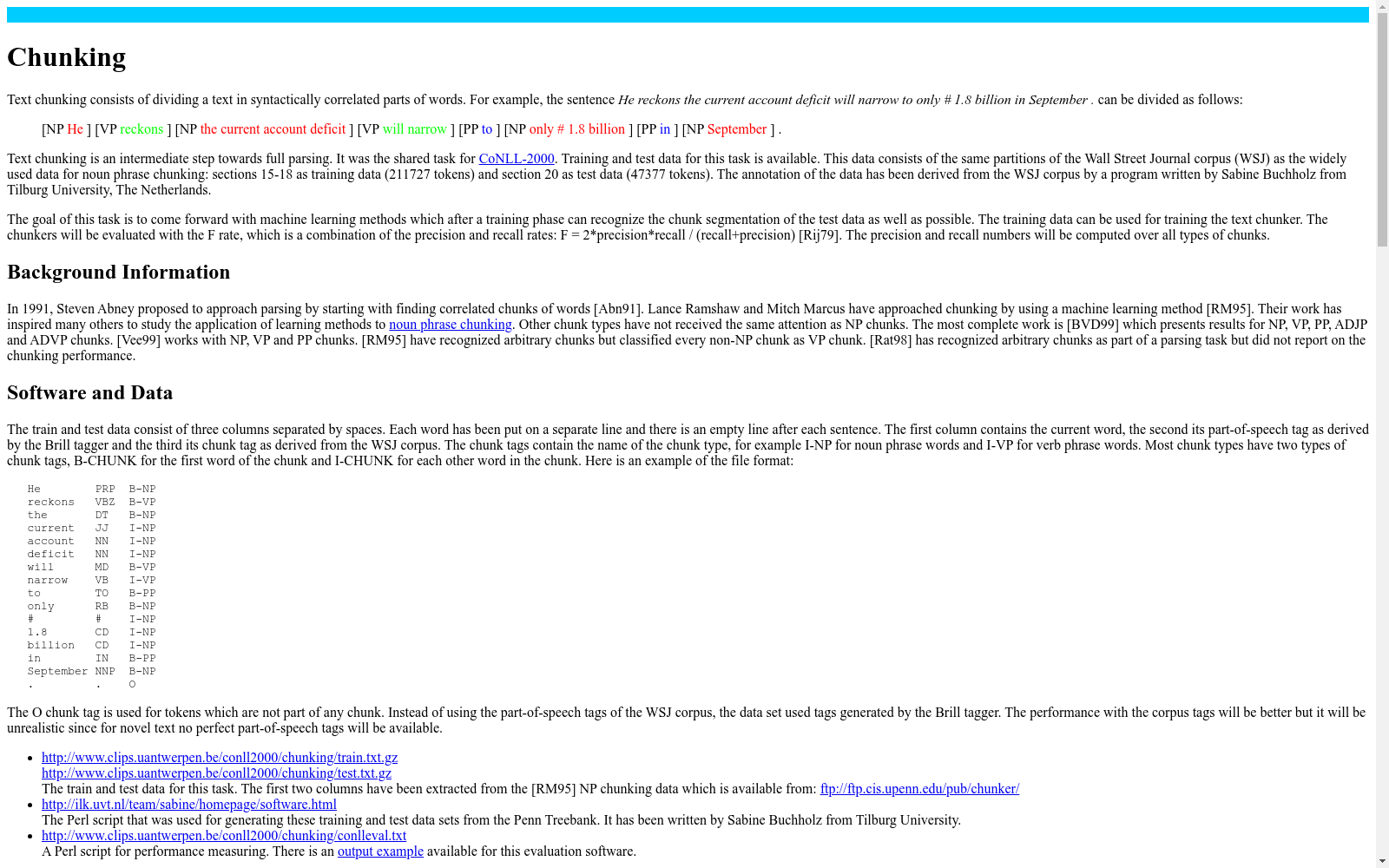
CoNLL 2000数据集是一个用于词性标注和组块分析的语料库。它包含了从华尔街日报中提取的文本,分为训练集和测试集。该数据集主要用于自然语言处理任务,特别是用于评估和训练词性标注和组块分析模型。
The CoNLL 2000 dataset is a corpus dedicated to part-of-speech tagging and chunking tasks. It comprises texts extracted from the Wall Street Journal, and is divided into training and test sets. This dataset is primarily applied in natural language processing (NLP) tasks, especially for evaluating and training models for part-of-speech tagging and chunking.
提供机构:
www.cnts.ua.ac.be
搜集汇总
数据集介绍
构建方式
CoNLL 2000数据集的构建基于自然语言处理领域的命名实体识别(NER)任务,旨在提供一个标准化的测试平台。该数据集从华尔街日报(WSJ)语料库中提取,包含1998年1月至1998年8月的文本数据。构建过程中,数据被分为训练集和测试集,分别包含8,936和2,012个句子。每个句子中的词汇和词性标签被标注,并进一步标注了短语结构,为后续的句法分析和命名实体识别提供了丰富的信息。
使用方法
CoNLL 2000数据集主要用于评估和训练命名实体识别和句法分析模型。研究者和开发者可以使用该数据集进行模型的训练和测试,通过比较不同模型在测试集上的表现,评估其性能。此外,该数据集还可用于开发和验证新的NLP算法和方法,特别是在需要句法信息的任务中。使用时,建议遵循数据集提供的训练集和测试集划分,以确保评估的公正性和一致性。
背景与挑战
背景概述
在自然语言处理领域,句法分析一直是核心任务之一。CoNLL 2000数据集由Tjong Kim Sang和De Meulder于2000年发布,旨在推动基于特征的机器学习方法在句法分析中的应用。该数据集基于华尔街日报的文本,包含了大量的名词短语块标注,为研究人员提供了一个标准化的测试平台。CoNLL 2000的发布极大地促进了句法分析技术的发展,尤其是在早期机器学习方法的应用上,为后续研究奠定了坚实的基础。
当前挑战
尽管CoNLL 2000数据集在句法分析领域具有重要地位,但其构建过程中也面临诸多挑战。首先,数据集的标注工作需要高度专业化的知识,确保每个名词短语块的边界和类型准确无误。其次,数据集的规模和多样性对于模型的泛化能力提出了高要求,如何在有限的资源下平衡数据量与质量是一个关键问题。此外,随着深度学习技术的兴起,传统的基于特征的方法逐渐被神经网络模型取代,如何将CoNLL 2000数据集与现代技术结合,以适应新的研究需求,也是一个亟待解决的挑战。
发展历史
创建时间与更新
CoNLL 2000数据集于2000年首次发布,作为自然语言处理领域的重要资源,它为句法分析任务提供了标准化的测试平台。此后,该数据集未有显著更新,但其基础数据和评估方法仍被广泛应用于相关研究中。
重要里程碑
CoNLL 2000数据集的发布标志着句法分析任务在自然语言处理领域的重要进展。它首次引入了基于词性标注和句法块分析的任务,为研究人员提供了一个统一的基准数据集。这一数据集的成功应用,不仅促进了句法分析技术的发展,还为后续的语义分析和机器翻译等高级任务奠定了基础。
当前发展情况
尽管CoNLL 2000数据集自发布以来未有重大更新,但其对自然语言处理领域的贡献依然显著。该数据集的标准化评估方法和高质量数据,持续为句法分析算法的研发和评估提供支持。近年来,随着深度学习技术的兴起,CoNLL 2000数据集被重新用于验证新型神经网络模型的有效性,进一步推动了自然语言处理技术的进步。
发展历程
- CoNLL 2000数据集首次发表,作为第七届计算自然语言学习会议(CoNLL-2000)的一部分,主要用于词性标注和组块分析任务。
- CoNLL 2000数据集首次应用于自然语言处理研究,成为词性标注和组块分析领域的标准基准数据集。
- CoNLL 2000数据集在自然语言处理社区中广泛应用,促进了词性标注和组块分析算法的发展和比较。
- CoNLL 2000数据集被用于评估和改进基于机器学习的自然语言处理模型,进一步推动了该领域的技术进步。
- CoNLL 2000数据集继续作为词性标注和组块分析任务的重要基准,支持了深度学习技术在该领域的应用和研究。
- CoNLL 2000数据集在自然语言处理研究中仍然具有重要地位,被广泛用于评估和比较不同模型的性能。
- CoNLL 2000数据集在自然语言处理领域持续发挥作用,支持了新一代词性标注和组块分析模型的开发和验证。
常用场景
经典使用场景
在自然语言处理领域,CoNLL 2000数据集以其丰富的语料和结构化的标注信息,成为词性标注和语块分析的经典基准。该数据集包含新闻文章的文本,每个词都标注了词性和语块标签,为研究者提供了一个标准化的测试平台。通过使用CoNLL 2000,研究者可以评估和比较不同算法的性能,特别是在处理复杂句法结构时。
解决学术问题
CoNLL 2000数据集在解决词性标注和语块分析的学术研究问题中发挥了关键作用。它不仅为研究人员提供了一个统一的评估标准,还促进了新算法的开发和验证。通过该数据集,研究者能够深入探讨如何更准确地识别和标注文本中的词性和语块,从而推动自然语言处理技术的发展。
实际应用
在实际应用中,CoNLL 2000数据集的成果被广泛应用于文本分析、信息提取和机器翻译等领域。例如,在自动文档摘要和情感分析中,准确的词性标注和语块识别是提高系统性能的关键。此外,该数据集还为开发智能助手和聊天机器人提供了基础,使得这些系统能够更自然地理解和生成人类语言。
数据集最近研究
最新研究方向
在自然语言处理领域,CoNLL 2000数据集作为词性标注和句法分析的经典基准,近年来研究者们致力于提升其在大规模语料上的应用性能。前沿研究方向包括利用深度学习模型如BERT和GPT-3进行预训练,以增强模型的泛化能力和上下文理解。此外,跨语言和多模态数据的融合也成为热点,旨在通过多语言和多模态信息的互补,提升单一语言数据集的表现。这些研究不仅推动了自然语言处理技术的发展,也为跨文化交流和多语言信息处理提供了新的解决方案。
相关研究论文
- 1A Neural Architecture for Named Entity RecognitionUniversity of Cambridge · 2016年
- 2Evaluating the Utility of Hand-crafted Features in Sequence LabelingUniversity of Edinburgh · 2011年
- 3Deep Biaffine Attention for Neural Dependency ParsingUniversity of Washington · 2017年
- 4Neural Architectures for Named Entity RecognitionStanford University · 2016年
- 5A Survey on Recent Advances in Named Entity Recognition from Deep Learning modelsUniversity of Amsterdam · 2019年
以上内容由遇见数据集搜集并总结生成


