MSU音频视频室内监控(MSU-AVIS)数据集
收藏帕依提提2024-03-04 收录
下载链接:
https://www.payititi.com/opendatasets/show-26615.html
下载链接
链接失效反馈官方服务:
资源简介:
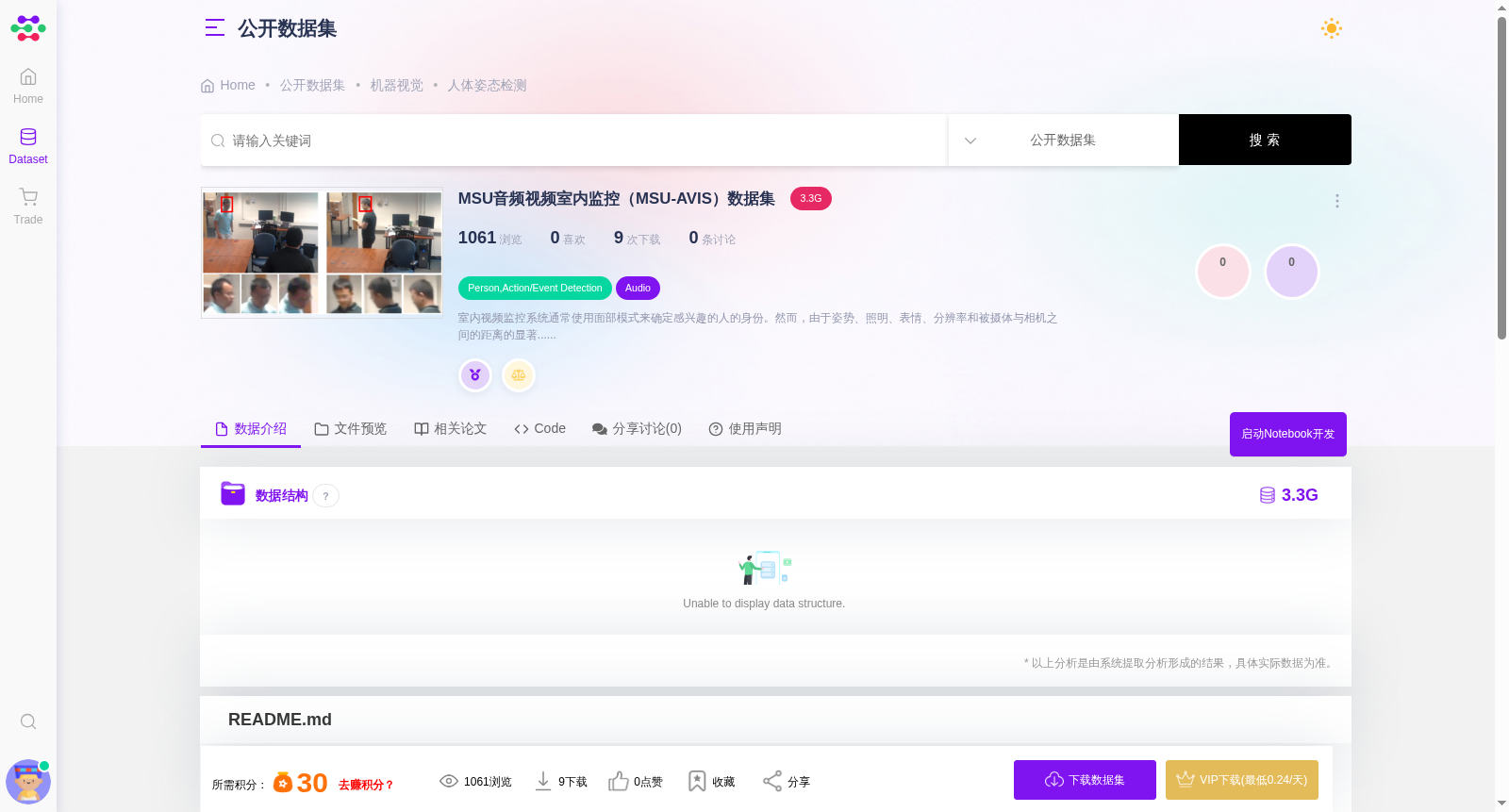
室内视频监控系统通常使用面部模式来确定感兴趣的人的身份。然而,由于姿势、照明、表情、分辨率和被摄体与相机之间的距离的显著变化,面部图像在许多场景中可能无法提供足够的辨别信息。 在这种情况下,包含额外的生物特征模态可以有助于识别过程。在这方面,我们考虑了语音和面部模态的融合,以提高识别精度。这项工作的主要贡献是组装一个多模态(面部和语音)、半应变的室内视频监控数据集,称为MSU音频视频室内监控(MSU-AVIS)数据集。为此,我们使用带有内置麦克风的消费级摄像头来获取数据。我们使用当前最先进的基于深度学习的方法在收集的数据集上执行人脸和说话人识别,以建立基线性能。我们还探索了多种融合方案,将人脸和说话人识别结合起来,对音频视频监控数据进行有效的人物识别。实验表明,在监控场景中,所提出的多模态融合方案(人脸和语音)优于单峰方法。收集的数据集正用于研究目的。 Figure 1: 人脸识别失败的视频剪辑示例。较大的图像是来自从剪辑获得的帧的子区域。较小的图像是从同一剪辑中获得的一些其他人脸。
Indoor video surveillance systems typically employ facial modalities to verify the identities of persons of interest. However, due to significant variations in pose, illumination, expression, resolution, and the distance between the subject and the camera, facial images may fail to provide sufficient discriminative information in many scenarios. In such cases, incorporating additional biometric modalities can facilitate the identification process. In this regard, we consider the fusion of facial and speech modalities to enhance recognition accuracy.
The primary contribution of this work is the assembly of a multimodal (facial and speech), semi-unconstrained indoor video surveillance dataset, termed the MSU Audio-Visual Indoor Surveillance (MSU-AVIS) dataset. To collect this dataset, we utilized consumer-grade cameras equipped with built-in microphones. We implemented state-of-the-art deep learning-based methods for face and speaker recognition on the collected dataset to establish baseline performance. We also explored multiple fusion schemes to combine face and speaker recognition for effective person identification in audio-visual surveillance data. Experiments demonstrate that the proposed multimodal fusion scheme (facial and speech) outperforms unimodal methods in surveillance scenarios. The collected dataset is made available for research purposes.
Figure 1: Example video clips where face recognition fails. The larger image is a sub-region cropped from a frame extracted from the clip. The smaller images are several other facial crops obtained from the same clip.
提供机构:
帕依提提
搜集汇总
数据集介绍
背景与挑战
背景概述
MSU音频视频室内监控(MSU-AVIS)数据集是一个多模态数据集,专注于室内视频监控场景,融合了面部和语音两种生物特征模态,旨在提高人物识别的准确性,解决单一面部识别在监控中因姿势、光照等因素导致的局限性。该数据集大小为3.3G,用于研究目的,支持基于深度学习方法的人脸和说话人识别基线性能评估,并探索多模态融合方案以优化监控系统中的人物识别。
以上内容由遇见数据集搜集并总结生成


