CRAFT
收藏github2024-09-04 更新2024-09-05 收录
下载链接:
https://github.com/ziegler-ingo/CRAFT
下载链接
链接失效反馈资源简介:
CRAFT是一个用于任务特定合成数据集生成的项目,通过语料库检索和增强技术,提供了多个领域的合成数据集,如生物医学问答、常识问答、医学问答等。
CRAFT is a project dedicated to task-specific synthetic dataset generation. Leveraging corpus retrieval and augmentation techniques, it provides synthetic datasets across multiple domains, including biomedical question answering, commonsense question answering, medical question answering, and more.
创建时间:
2024-08-09
原始信息汇总
CRAFT: Corpus Retrieval and Augmentation for Fine-Tuning
数据集概述
CRAFT项目提供了多个合成数据集,这些数据集适用于不同的任务,包括生物学问答(BioQA)、常识问答(CommonSenseQA, CSQA)、医学问答(MedQA)、食谱生成(RecipeGen)和摘要生成(Summarization)。这些数据集在Hugging Face平台上可用。
数据集链接
- BioQA: https://huggingface.co/datasets/ingoziegler/CRAFT-BioQA
- CommonSenseQA (CSQA): https://huggingface.co/datasets/ingoziegler/CRAFT-CommonSenseQA
- MedQA: https://huggingface.co/datasets/ingoziegler/CRAFT-MedQA
- RecipeGen: https://huggingface.co/datasets/ingoziegler/CRAFT-RecipeGen
- Summarization: https://huggingface.co/datasets/ingoziegler/CRAFT-Summarization
数据集使用
要使用人工编写的小样本数据,可以通过过滤数据集中的is_few_shot == 1来获取,或者直接加载assets/{task}/few-shot/corpus-task-32.jsonl文件。8个小样本实验使用每个文件的前8行。
性能表现
在合成数据集上训练的模型能够匹配通用指令调优的大型语言模型(LLMs)的性能,甚至在某些任务(如摘要生成)上超过人类策划数据的训练效果。合成数据在面对分布偏移时更为稳健,因为数据不是为特定测试集生成,而是为整体任务生成。
5-gram重叠率比较
| BioQA | CSQA | MedQA | Summarization | |
|---|---|---|---|---|
| CRAFT<sub>XS</sub> | 0.0% | 0.0% | 0.0% | 0.0% |
| CRAFT<sub>S</sub> | 0.0% | 0.1% | 0.1% | 0.0% |
| CRAFT<sub>M</sub> | 0.0% | 0.2% | 0.1% | 0.1% |
| CRAFT<sub>L</sub> | 0.0% | 0.4% | 0.3% | 0.2% |
| CRAFT<sub>XL</sub> | 0.0% | 0.2% | 0.2% | 0.2% |
| Baseline <small>(In-domain Train Set)</small> | 17.9% | 4.4% | 1.1% | 0.3% |
跨测试集性能比较
| Dataset | Baseline | CRAFT<sub>XL</sub> |
|---|---|---|
| In-domain | 89.9 | 78.1 |
| MMLU<sub>Medical Genetics</sub> | 60.0 | 69.0 |
| MMLU<sub>Anatomy</sub> | 55.6 | 57.0 |
| MMLU<sub>High School Biology</sub> | 69.3 | 67.4 |
| MMLU<sub>College Biology</sub> | 66.7 | 74.3 |
| MMLU-Avg | 62.9 | 66.9 |
适配器检查点
提供了在CRAFT-XL版本上微调后得到的适配器检查点的下载链接:
- BioQA: https://huggingface.co/ingoziegler/CRAFT-BioQA-XL
- CommonSenseQA (CSQA): https://huggingface.co/ingoziegler/CRAFT-CommonSenseQA-XL
- MedQA: https://huggingface.co/ingoziegler/CRAFT-MedQA-XL
- RecipeGen: https://huggingface.co/ingoziegler/CRAFT-RecipeGen-XL
- Summarization: https://huggingface.co/ingoziegler/CRAFT-Summarization-XL
AI搜集汇总
数据集介绍
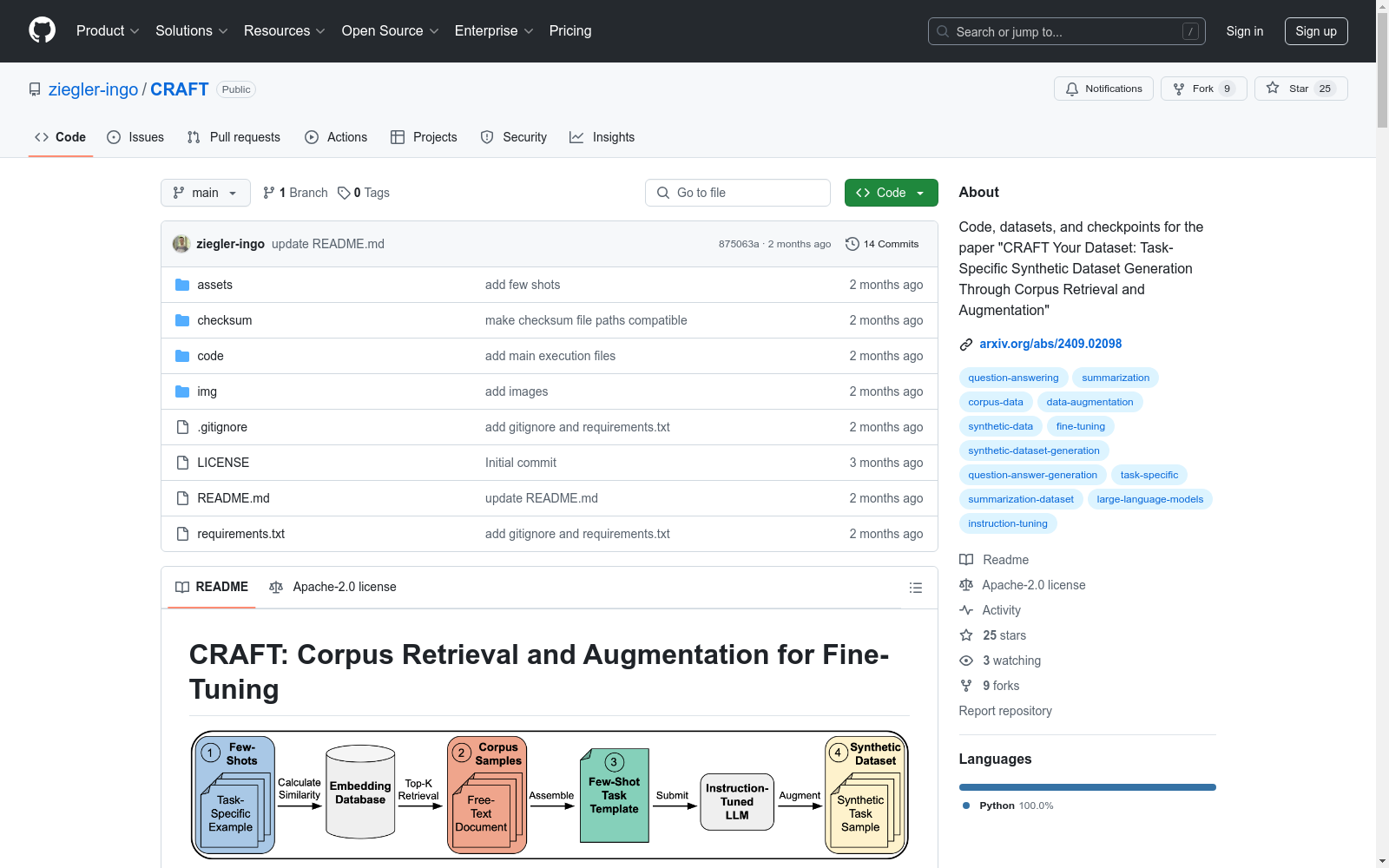
构建方式
CRAFT数据集的构建方式基于任务特定的合成数据生成技术,通过语料库检索和数据增强实现。首先,利用预训练的嵌入模型(如multi-qa-MiniLM-L6-cos-v1)对公开或私有语料库进行嵌入,生成一个包含文档嵌入的数据库。随后,根据任务需求设计少量示例(few-shots),并通过检索和数据增强技术生成大规模的合成数据集。这一过程确保了数据集的多样性和任务相关性,同时避免了特定测试集的偏差。
特点
CRAFT数据集的主要特点在于其合成数据的任务特定性和鲁棒性。通过任务特定的数据生成,CRAFT能够提供与任务高度相关的训练数据,从而提升模型在特定任务上的表现。此外,CRAFT数据集在分布偏移方面表现出显著的鲁棒性,其合成数据与测试集的5-gram重叠率远低于传统的人工策划数据集,确保了模型在不同测试集上的稳定性能。
使用方法
使用CRAFT数据集时,用户首先需下载并设置必要的文件和目录结构,包括嵌入数据库和相关语料库。接着,用户可以通过运行一系列Python脚本,依次完成语料库检索、任务样本创建、模型微调及模型评估等步骤。具体操作包括使用提供的运行配置文件执行数据检索和任务样本生成,然后进行模型微调,最后通过评估脚本对模型性能进行评估。用户还可以根据需要调整和扩展数据集,以适应不同的任务需求。
背景与挑战
背景概述
CRAFT数据集,全称为Corpus Retrieval and Augmentation for Fine-Tuning,是由Ingo Ziegler、Abdullatif Köksal、Desmond Elliott和Hinrich Schütze等研究人员于2024年创建的。该数据集的核心研究问题是通过语料库检索和增强技术生成特定任务的合成数据集,以提升模型在特定任务上的表现。CRAFT数据集的发布对自然语言处理领域,特别是数据增强和微调技术的发展产生了重要影响。其通过合成数据的方式,不仅提高了模型的泛化能力,还显著减少了数据偏差,为后续研究提供了新的方向和方法。
当前挑战
CRAFT数据集在构建过程中面临多项挑战。首先,合成数据的生成需要精确的语料库检索和增强技术,以确保数据的质量和多样性。其次,数据集的构建涉及多个领域的知识,如生物学、医学、常识等,这要求研究人员具备跨学科的专业知识。此外,合成数据的有效性验证也是一个重要挑战,需要通过严格的实验设计和对比分析来证明其对模型性能的提升。最后,数据集的规模和复杂性增加了存储和计算资源的负担,如何在有限的资源下高效地生成和使用数据集是一个亟待解决的问题。
常用场景
经典使用场景
CRAFT数据集的经典使用场景主要集中在自然语言处理领域,特别是在任务特定的数据生成和增强方面。通过利用CRAFT,研究者可以生成高质量的合成数据集,用于微调大型语言模型(LLMs)。例如,在生物医学问答(BioQA)、常识问答(CommonSenseQA)、医学问答(MedQA)、食谱生成(RecipeGen)和文本摘要(Summarization)等任务中,CRAFT能够提供丰富的合成数据,帮助模型在这些特定任务上达到甚至超越人类标注数据的效果。
解决学术问题
CRAFT数据集解决了自然语言处理领域中数据稀缺和数据分布偏移的常见学术问题。通过生成任务特定的合成数据,CRAFT不仅增加了训练数据的多样性,还提高了模型在面对不同测试集时的鲁棒性。具体来说,CRAFT的合成数据在5-gram重叠率上显著低于传统的人类标注数据,从而减少了过拟合的风险,增强了模型在多任务和跨领域测试中的表现。
衍生相关工作
CRAFT数据集的发布催生了一系列相关研究和工作。例如,基于CRAFT的合成数据,研究者们开发了新的微调策略和模型评估方法,进一步提升了大型语言模型在特定任务上的表现。此外,CRAFT的成功应用也激发了对数据生成和增强技术的深入研究,推动了自然语言处理领域在数据高效利用和模型泛化能力方面的进步。
以上内容由AI搜集并总结生成


