ChemCoTBench
收藏github2025-06-10 更新2025-06-11 收录
下载链接:
https://github.com/HowardLi1984/ChemCoTBench
下载链接
链接失效反馈官方服务:
资源简介:
ChemCoTBench是首个针对复杂化学问题逐步推理的大规模基准测试,专为大型语言模型(LLMs)设计。它超越了简单的问答,涵盖了对化学理解至关重要的全面任务套件。该数据集基于200万原始化学分子样本,生成了近2万高质量思维链样本,包含四个核心任务,挑战LLMs在不同化学任务方面的能力。
ChemCoTBench is the first large-scale benchmark designed for the step-by-step reasoning of complex chemical problems, specifically tailored for Large Language Models (LLMs). It transcends simple question-answering and encompasses a comprehensive suite of tasks crucial for chemical understanding. The dataset is based on 2 million original chemical molecule samples, generating nearly 20,000 high-quality reasoning chain samples, containing four core tasks that challenge the capabilities of LLMs across various chemical tasks.
创建时间:
2025-06-04
原始信息汇总
ChemCoTBench 数据集概述
基本信息
- 名称: ChemCoTBench
- 类型: 化学领域大规模基准测试数据集
- 设计目标: 评估大型语言模型(LLM)在复杂化学问题上的逐步推理能力
- 许可证: CC BY 4.0
- 相关链接:
- 论文: https://arxiv.org/abs/2505.21318
- 数据集: https://huggingface.co/datasets/OpenMol/ChemCoTBench
- 大规模数据集: https://huggingface.co/datasets/OpenMol/ChemCoTBench-CoT
- 主页: https://howardli1984.github.io/ChemCoTBench.github.io/
- 排行榜: https://howardli1984.github.io/ChemCoTBench.github.io/
数据集特点
- 数据规模:
- 基于200万原始化学分子样本
- 生成近2万高质量思维链样本
- 任务类型:
- 分子SMILES级别理解
- 分子Murcko骨架理解
- 分子官能团计数
- 分子编辑(添加、删除、替换)
- 分子物理化学性质优化(QED、LogP、溶解度)
- 分子蛋白质激活优化(DRD-2、JNK-3、GSK-3beta)
- 逆合成预测
- 正向主产物预测
- 正向副产物预测
- 反应条件预测
- 反应机理预测
- 评估框架:
- 结合标准NLP指标和新型领域特定指标
- 采用LLM判断与13位化学家专家评审的双重验证过程
创新点
- 将复杂化学任务分解为可验证的模块化化学操作序列
- 专注于分子建模和设计的逐步推理评估
- 包含从基础分子操作到复杂化学反应的多层次挑战任务
引用信息
bibtex @article{li2025beyond, title={Beyond Chemical QA: Evaluating LLMs Chemical Reasoning with Modular Chemical Operations}, author={Li, Hao and Cao, He and Feng, Bin and Shao, Yanjun and Tang, Xiangru and Yan, Zhiyuan and Yuan, Li and Tian, Yonghong and Li, Yu}, journal={arXiv preprint arXiv:2505.21318}, year={2025} }
搜集汇总
数据集介绍
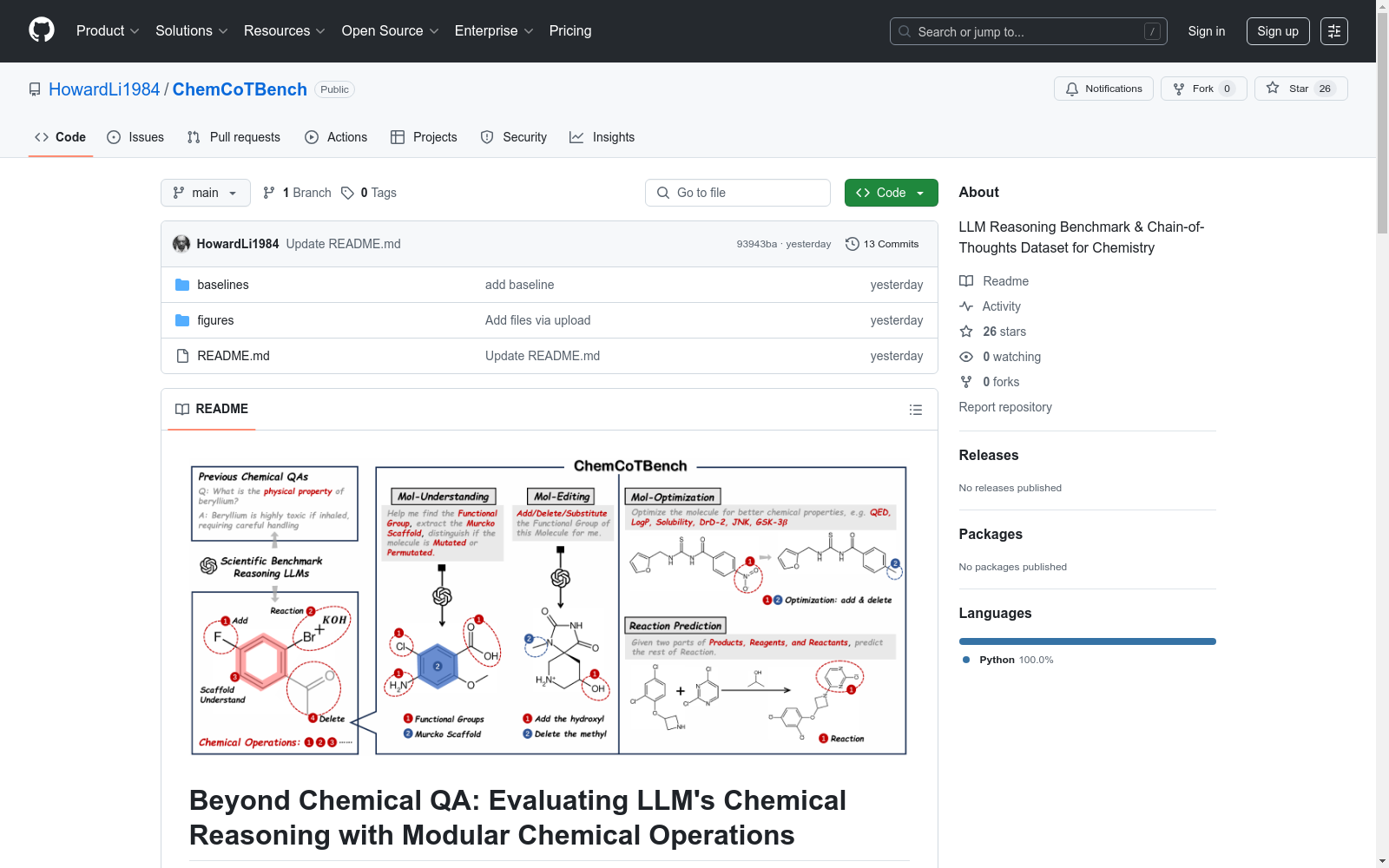
构建方式
在化学信息学领域,ChemCoTBench通过系统化方法构建了首个面向复杂化学问题分步推理的大规模评估基准。该数据集基于200万原始化学分子样本,经过多阶段处理与专家验证,最终精选出2万条高质量思维链样本。构建过程采用模块化化学操作理念,将分子建模与设计任务分解为可验证的SMILES结构操作序列,并由13位化学家组成专家团队进行双重验证,确保数据严谨性与领域相关性。
特点
作为化学推理领域的突破性评估工具,ChemCoTBench展现出鲜明的专业特征。其覆盖分子SMILES理解、骨架分析、官能团计数等基础任务,延伸至分子编辑、物化性质优化及蛋白质激活等高级应用,更包含逆合成预测、反应机制推断等前沿课题。数据集创新性地采用链式思维标注,通过四类核心任务的渐进式设计,实现了从单分子操作到多分子反应的难度梯度,配合领域专属的混合评估指标,为模型能力提供多维度的精准度量。
使用方法
研究人员可通过Hugging Face平台直接加载ChemCoTBench数据集开展评估工作。使用时应遵循任务模块的划分逻辑,首先验证模型在基础分子操作的表现,再逐步测试复杂反应预测能力。官方提供的标准化评估框架支持自动指标计算,建议结合Leaderboard公布的基线结果进行横向比对。对于特定子任务如逆合成分析,可单独提取对应数据子集进行针对性测试,但需注意保持与原始数据划分的一致性以确保结果可比性。
背景与挑战
背景概述
ChemCoTBench由Hao Li等研究人员于2025年推出,是首个针对大型语言模型在化学领域逐步推理能力的大规模基准测试。该数据集由OpenMol团队构建,基于200万原始化学分子样本,生成了近2万条高质量思维链样本,覆盖从分子结构理解到复杂化学反应预测等12项核心任务。作为化学与人工智能交叉领域的重要基础设施,它突破了传统化学问答评估的局限,通过模块化操作链的设计,首次实现了对LLMs在药物发现、材料科学等实际应用场景中结构化推理能力的系统评估。其双阶段专家验证机制为化学AI领域提供了迄今为止最严谨的评估框架。
当前挑战
在领域问题层面,化学推理存在分子操作可解释性差与多步反应路径耦合两大核心挑战。传统评估难以量化模型在Murcko骨架修饰或反应条件预测等任务中,对官能团空间位阻、电子效应等专业知识的隐式运用。构建过程中,研究团队面临化学操作模块化定义的复杂性,需平衡SMILES字符串的符号逻辑与化学家直觉认知;同时为确保20K样本的标注质量,需设计兼顾自动化验证与13位化学专家人工审核的混合质量控制体系,这对标注协议的设计和领域知识的形式化表达提出了极高要求。
常用场景
经典使用场景
在化学信息学与计算药物发现领域,ChemCoTBench通过构建模块化化学操作链,为大型语言模型(LLMs)提供了系统性评估框架。其核心价值体现在对分子编辑、性质优化及反应预测等任务的逐步推理验证,例如指导模型从SMILES字符串解析开始,逐步完成Murcko骨架识别、官能团修饰,最终实现溶解度或蛋白靶点活性的定向优化。这种分阶段任务设计模拟了药物化学家实际工作中的分子设计迭代流程。
解决学术问题
该数据集有效解决了化学AI研究中两个关键瓶颈:传统QA任务缺乏可解释的推理过程,以及混合评估导致的技能归因模糊性。通过将复杂化学问题解构为原子操作序列(如取代基添加/删除、反应条件预测),研究者可精确量化模型在分子层面理解、变换逻辑和性质关联推理等维度的能力。这种评估范式为开发具有真实化学思维能力的AI系统提供了可量化的基准。
衍生相关工作
基于ChemCoTBench的评估方法论,学术界衍生出多个创新研究方向:MIT团队开发了基于化学操作树的分子优化框架ChemTreeGPT;DeepChem社区将其任务拆解逻辑整合进强化学习环境ChemGym;另有研究通过迁移学习将基准中的模块化推理能力应用于金属有机催化剂设计,推动了计算化学与AI的深度融合。
以上内容由遇见数据集搜集并总结生成


