Geo_Benchmark
收藏Hugging Face2026-01-29 更新2026-01-30 收录
下载链接:
https://huggingface.co/datasets/rfr2003/Geo_Benchmark
下载链接
链接失效反馈官方服务:
资源简介:
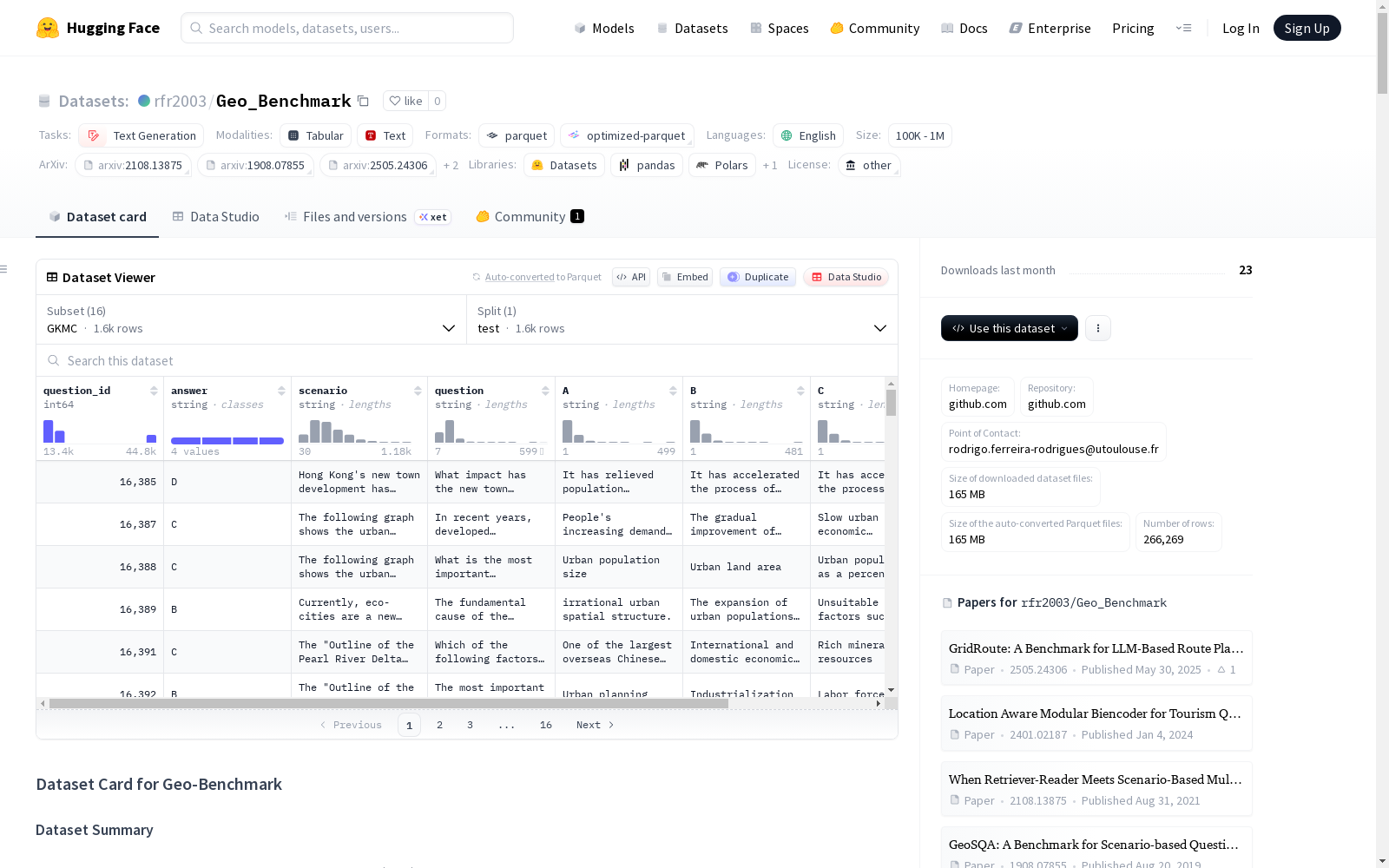
Geo-Benchmark是一个旨在评估大型语言模型(LLM)在地理领域多任务能力的综合基准数据集。该数据集整合了来自12个子集的8种不同任务,包括知识类任务(如坐标预测、是/否问题、回归问题、地点预测)和推理类任务(如场景复杂问答、空间推理)以及应用类任务(如兴趣点推荐、路径规划)。数据集主要包含文本生成任务,所有数据均为英文。数据规模方面,训练集包含236,290个样本,开发集29,942个样本,测试集176,628个样本。每个子集具有不同的数据结构,但都经过预处理以便于访问和使用。数据集可用于评估LLM在地理空间理解、推理和应用方面的能力。
创建时间:
2026-01-26
原始信息汇总
Geo Benchmark 数据集概述
数据集基本信息
- 数据集名称:Geo Benchmark
- 主页:https://github.com/Rfr2003/GeoBenchmark
- 仓库:https://github.com/Rfr2003/GeoBenchmark
- 联系人:rodrigo.ferreira-rodrigues@utoulouse.fr
- 语言:英语 (en)
- 许可证:other
- 主要任务类别:文本生成 (text-generation)
数据集目标
Geo-Benchmark 旨在评估大型语言模型 (LLM) 在多种任务中的地理能力。
数据集构成与任务
数据集由 12 个来源数据集构成,涵盖 8 种不同的任务类型。
知识类任务 (Knowledge)
- 坐标预测 (Coordinates Prediction)
- 来源数据集:GeoQuestions1089
- 是/否问题 (Yes|No questions)
- 来源数据集:GeoQuestions1089
- 回归问题 (Regression questions)
- 来源数据集:GeoQuestions1089, GeoQuery
- 地点预测 (Place Prediction)
- 来源数据集:GeoQuestions1089, GeoQuery, Ms Marco
推理类任务 (Reasoning)
- 场景复杂问答 (Scenario Complex QA)
- 来源数据集:GeoSQA, GKMC
- 空间推理 (Spatial Reasoning)
- 来源数据集:SpartUN, StepGame, SpatialEvalLLM
应用类任务 (Application)
- 兴趣点推荐 (POI Recommendation)
- 来源数据集:TourismQA, NY-QA
- 路径查找 (Path Finding)
- 来源数据集:GridRoute, PPNL, bAbI (task 19)
数据集配置与结构
数据集包含多个配置 (config),每个配置对应一个特定的任务或数据集变体。
配置列表
- GKMC
- GeoQuery_place
- GeoQuery_regression
- GeoQuestions1089_YN
- GeoQuestions1089_coord
- GeoQuestions1089_place
- GeoQuestions1089_regression
- GeoSQA
- GridRoute
- MsMarco
- NY-POI
- PPNL_multi
- PPNL_single
- SpartUN
- SpatialEvalLLM
- TourismQA
数据划分统计
| 类别 | 任务 | 数据集 | 训练集样本数 | 验证集样本数 | 测试集样本数 |
|---|---|---|---|---|---|
| 知识 | 坐标预测 | GeoQuestions1089 | – | – | 84 |
| 是/否问题 | GeoQuestions1089 | – | – | 181 | |
| 回归问题 | GeoQuestions1089<br>GeoQuery | –<br>180 | –<br>17 | 234<br>88 | |
| 地点预测 | GeoQuestions1089<br>GeoQuery<br>MS-Marco | –<br>348<br>23,513 | –<br>32<br>4,149 | 455<br>184<br>2,907 | |
| 推理 | 场景复杂问答 | GeoSQA<br>GKMC | –<br>– | –<br>– | 4,110<br>1,600 |
| 空间推理 | SpatialEvalLLM<br>SpartUN<br>StepGame | –<br>37,095<br>50,000 | –<br>5,600<br>5,000 | 1,400<br>5,551<br>100,000 | |
| 应用 | 兴趣点推荐 | TourismQA<br>NY-QA | 19,960<br>– | 2,119<br>– | 2,173<br>1,347 |
| 路径查找 | bAbI (task 19)<br>GridRoute<br>PPNL | 9,000<br>–<br>69,472 | 1,000<br>–<br>8,684 | 1,000<br>300<br>74,484 | |
| 总计 | – | – | 236,290 | 29,942 | 176,628 |
使用方式
python import datasets dataset = datasets.load_dataset("rfr2003/Geo_Benchmark", "GeoSQA")
引用信息
数据集整合了多个来源的工作,使用时请引用相关原始论文。部分引用如下:
- Huang et al. (2021) - GKMC
- Finegan-Dollak et al. (2018) - GeoQuery
- Zelle & Mooney (1996) - Geography, original
- Huang et al. (2019) - GeoSQA
- Li et al. (2025) - GridRoute
- Nguyen et al. (2016) - MS MARCO
- Hamzei et al. (2020) - Place questions
- Aghzal et al. (2024) - PPNL
搜集汇总
数据集介绍
构建方式
在空间信息科学领域,Geo_Benchmark数据集通过集成与重构多个现有地理空间数据集构建而成。该数据集系统性地汇集了来自GeoQuestions1089、GeoQuery、GeoSQA等12个异构数据源,覆盖坐标预测、地点识别、空间推理等八类核心任务。构建过程中,研究团队对原始数据进行了统一的预处理与格式标准化,确保了不同任务间数据结构的兼容性与可访问性,最终形成一个旨在全面评估大语言模型地理空间认知能力的综合性基准。
特点
该数据集以其任务多样性与结构异构性为显著特征,涵盖了从基础地理知识问答到复杂路径规划的广泛应用场景。其数据实例不仅包含传统的文本问答对,还纳入了网格坐标、障碍物列表、多模态上下文等结构化空间信息。这种多任务、多模态的设计使得数据集能够深入检验模型在理解、推理与应用地理空间概念方面的综合能力,为评估模型的泛化性与鲁棒性提供了丰富维度。
使用方法
研究人员可通过HuggingFace的`datasets`库便捷加载Geo_Benchmark的任一子数据集配置,例如使用`load_dataset("rfr2003/Geo_Benchmark", "GeoSQA")`调用地理情景问答数据。数据集已预先划分为训练集、验证集与测试集,支持针对特定任务进行模型微调、零样本评估或跨任务能力分析。在使用时,需依据所选配置关注其特有的数据字段,例如`world`、`path`等空间结构描述,以适配相应的文本生成或空间推理建模流程。
背景与挑战
背景概述
Geo_Benchmark数据集是评估大型语言模型地理空间理解能力的综合性基准测试工具。该数据集由研究者Rodrigo Ferreira-Rodrigues等人于近期构建,旨在系统性地衡量模型在知识获取、空间推理及实际应用等多维度的地理能力。其核心研究问题聚焦于探索人工智能对复杂地理信息的解析与生成水平,通过整合GeoQuestions1089、GeoSQA、SpartUN等十二个异构子数据集,覆盖了坐标预测、地点识别、路径规划等八大任务类型。这一基准的建立为地理信息科学和自然语言处理的交叉领域提供了标准化的评估框架,推动了空间认知智能的深入研究与发展。
当前挑战
Geo_Benchmark所应对的核心挑战在于解决模型对地理空间信息的深度理解与逻辑推理问题。地理问题往往涉及多尺度空间关系、模糊语义表达及动态环境约束,要求模型不仅掌握事实性知识,还需具备场景化推理能力。在数据集构建过程中,挑战主要源于异构数据源的整合与标准化。各子数据集在格式、标注规范及任务定义上存在显著差异,需进行大量的数据清洗、结构对齐与质量校验工作,以确保评估的一致性与可靠性。此外,地理数据的时空敏感性与领域专业性也为标注验证带来了额外复杂度。
常用场景
经典使用场景
在地理信息科学与自然语言处理交叉领域,Geo_Benchmark数据集为评估大型语言模型的地理空间能力提供了综合性基准。其经典使用场景集中于对模型进行多维度地理知识测试,涵盖坐标预测、地点识别、空间推理及路径规划等任务。研究者通过该数据集能够系统性地检验模型在理解地理实体、处理空间关系以及解决实际地理问题方面的表现,从而推动地理智能技术的演进。
衍生相关工作
围绕Geo_Benchmark衍生了一系列经典研究工作,例如基于GeoSQA的场景化问答模型改进、利用SpartUN增强空间关系理解,以及借助GridRoute探索语言模型在网格环境中的路径规划能力。这些工作不仅深化了对模型地理认知机制的探索,还催生了如地理知识增强预训练、多模态空间推理等创新方法,持续拓展地理人工智能的边界。
数据集最近研究
最新研究方向
在空间智能与地理信息科学交叉领域,Geo_Benchmark数据集正成为评估大语言模型空间认知能力的前沿基准。其最新研究方向聚焦于提升模型对复杂空间关系的理解与推理,特别是在多模态地理问答、动态路径规划以及兴趣点推荐等实际应用场景中的性能。随着自动驾驶、增强现实等技术的蓬勃发展,该数据集为检验模型能否处理真实世界中的模糊空间描述、进行几何推理与逻辑决策提供了关键测试平台。相关研究致力于探索模型在知识检索、符号推理与数值计算间的协同机制,以推动具备稳健空间智能的下一代人工智能系统发展,对智慧城市、地理信息服务等领域具有深远影响。
以上内容由遇见数据集搜集并总结生成


