magpie-preference
收藏数据集卡片 - Magpie Preference 数据集
数据集描述
Magpie Preference 数据集是一个通过众包收集的人类对使用 Magpie 方法生成的合成指令-响应对偏好的集合。该数据集通过用户与 Magpie Preference Gradio Space 的交互持续更新。
数据集概要
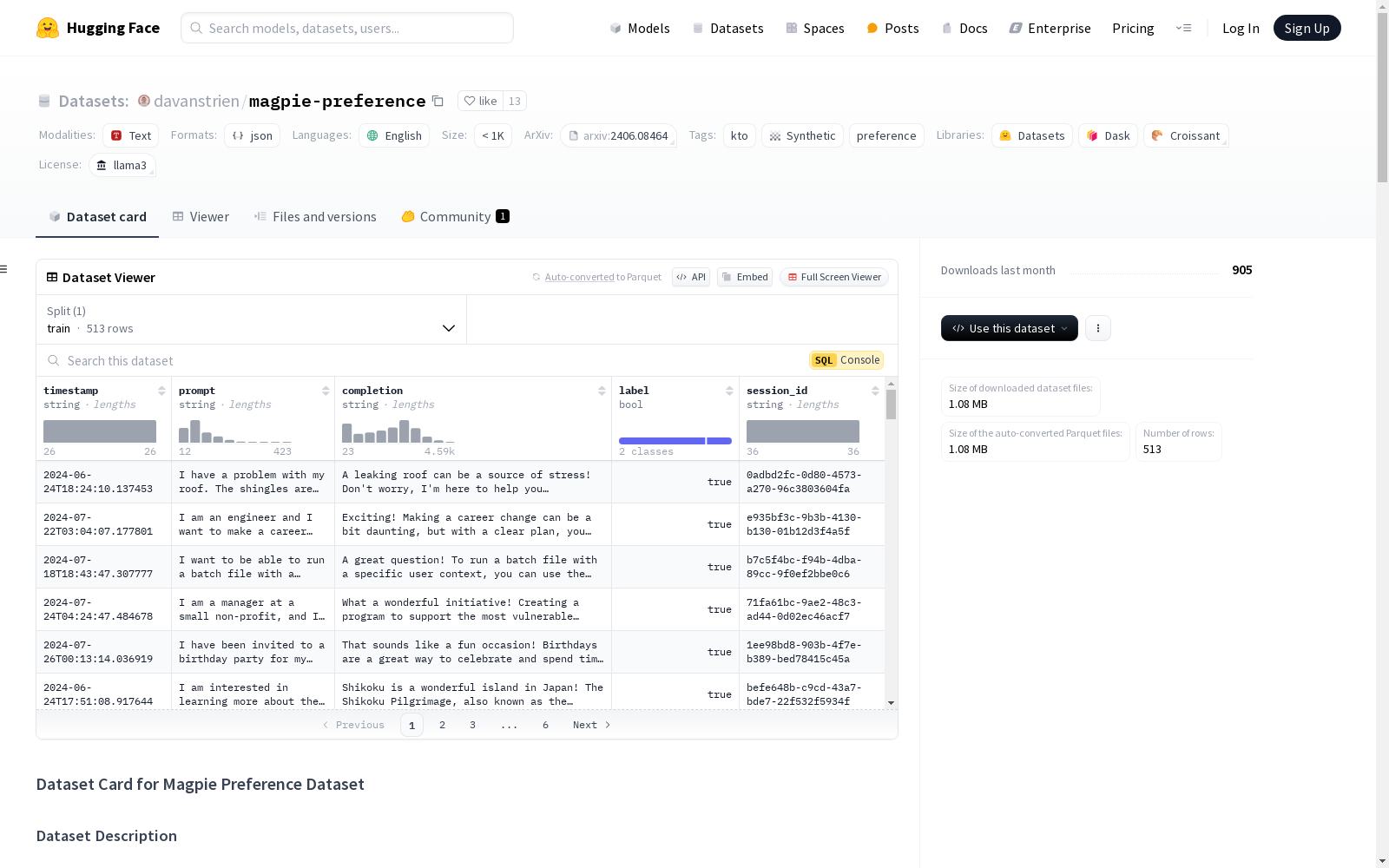
该数据集包含由大型语言模型(LLM)使用 Magpie 方法生成的指令-响应对和人类偏好标签。数据通过 Gradio 界面收集,用户可以生成指令-响应对并提供对其质量的反馈。
支持的任务
该数据集主要支持语言模型的偏好学习任务,特别是在指令跟随和响应生成方面。
语言
数据集中的语言取决于用于生成的模型(meta-llama/Meta-Llama-3-8B-Instruct)。主要语言是英语,但也可能包括模型支持的其他语言。
数据集结构
数据实例
每个实例包含:
- 时间戳
- 生成的指令(提示)
- 生成的响应(完成)
- 用户偏好标签(点赞/踩)
- 会话 ID
数据字段
timestamp:数据生成和评级的 ISO 格式时间戳prompt:LLM 生成的指令completion:LLM 生成的响应label:表示用户偏好的二进制标签(true 表示点赞,false 表示踩)session_id:用于分组同一会话反馈的 UUID
数据分割
该数据集没有预定义的分割,持续更新新条目。
数据集创建
策划理由
该数据集支持语言模型的偏好学习研究,特别是使用 Magpie 方法生成高质量合成数据。
源数据
源数据实时生成,使用 meta-llama/Meta-Llama-3-8B-Instruct。
初始数据收集和规范化
指令和响应使用预定义模板和 LLM 生成。用户偏好通过 Gradio 界面收集。
注释
注释以二进制偏好标签的形式提供,由 Gradio Space 的用户提供。
注释过程
用户通过 Gradio 界面生成指令-响应对并提供点赞/踩反馈。
注释者
注释者是公共 Gradio Space 的用户,无需特定资格。
个人和敏感信息
数据集不应包含个人信息。每个会话分配一个随机 UUID,不收集用户识别信息。
使用数据的注意事项
数据集的社会影响
该数据集旨在提高语言模型遵循指令和生成高质量响应的能力,可能带来更有用和一致的 AI 系统。
偏见的讨论
数据集可能反映生成模型和用户反馈偏好的偏见。在使用数据集时应考虑这些偏见。
其他已知限制
- 数据质量取决于用户在提供反馈时的理解和细致程度。
- 数据集持续演化,可能导致时间上的不一致。
附加信息
数据集策展人
该数据集由 Magpie Preference Gradio Space 的创建者和 Hugging Face 社区的贡献者策展。
引用信息
如果您使用此数据集,请引用 Magpie 论文:
bibtex @misc{xu2024magpie, title={Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing}, author={Zhangchen Xu and Fengqing Jiang and Luyao Niu and Yuntian Deng and Radha Poovendran and Yejin Choi and Bill Yuchen Lin}, year={2024}, eprint={2406.08464}, archivePrefix={arXiv}, primaryClass={cs.CL} }
贡献
该数据集因 Magpie Preference Gradio Space 用户的贡献而不断增长。我们欢迎并感谢所有贡献!