samsum
收藏Hugging Face2024-11-29 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/nyamuda/samsum
下载链接
链接失效反馈官方服务:
资源简介:
Samsum Dataset是一个重新组织的对话摘要数据集,由Gliwa, Bogdan等人创建。该数据集包含对话及其对应的摘要,语言为英语,大小在10K到100K之间。数据集遵循CC BY-NC-ND 4.0许可证。
The Samsum Dataset is a reorganized conversational summarization dataset created by Gliwa, Bogdan et al. It contains dialogues and their corresponding summaries, all in English, with a scale ranging from 10K to 100K. The dataset is licensed under CC BY-NC-ND 4.0.
创建时间:
2024-11-24
原始信息汇总
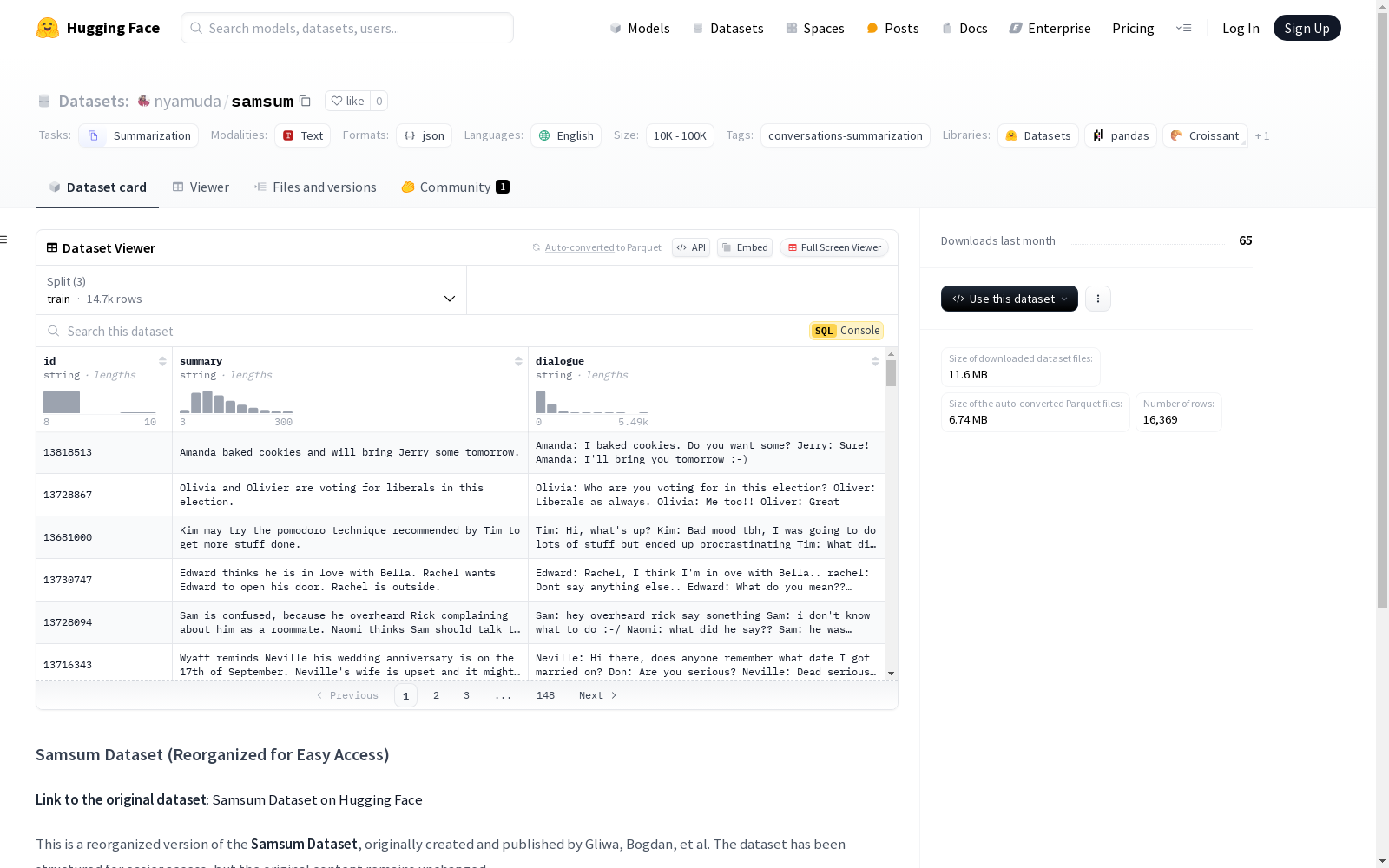
Samsum Dataset (Reorganized for Easy Access)
数据集信息
- 任务类别: 摘要生成
- 语言: 英语
- 数据规模: 10K<n<100K
- 标签: 对话摘要
- 原始作者: Gliwa, Bogdan, et al.
- 论文: Samsum Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization
- 出版: Proceedings of the 2nd Workshop on New Frontiers in Summarization, 2019.
- 许可证: Attribution-NonCommercial-NoDerivatives 4.0 International (CC BY-NC-ND 4.0)
搜集汇总
数据集介绍
构建方式
Samsum数据集的构建源于对话摘要领域的需求,旨在为抽象摘要任务提供高质量的标注数据。该数据集由Gliwa, Bogdan等人通过人工标注的方式创建,涵盖了多样化的日常对话场景。每段对话均经过专业标注人员的精心处理,生成了简洁且信息丰富的摘要。数据集的构建过程严格遵循学术标准,确保了数据的可靠性和实用性。
特点
Samsum数据集以其丰富的对话内容和高质量的摘要标注而著称。数据集包含超过16,000条对话及其对应的摘要,涵盖了日常生活中的多种话题。对话长度适中,摘要内容凝练,能够有效支持抽象摘要任务的研究与开发。此外,数据集的多样性和真实性使其成为评估和训练摘要模型的理想选择。
使用方法
Samsum数据集适用于对话摘要任务的研究与开发。用户可以通过Hugging Face平台轻松访问该数据集,并利用其进行模型训练、评估和对比实验。数据集的结构化设计使得数据加载和处理更加便捷。研究人员可以基于该数据集探索先进的摘要算法,或将其作为基准数据集进行性能验证。
背景与挑战
背景概述
Samsum数据集由Gliwa, Bogdan等人于2019年创建,旨在为对话摘要任务提供高质量的标注数据。该数据集收录了超过16,000条对话及其对应的摘要,涵盖了日常生活中的多种对话场景。其核心研究问题在于如何从对话中提取关键信息并生成简洁、连贯的摘要。Samsum数据集的发布填补了对话摘要领域的数据空白,推动了自然语言处理技术在对话摘要任务中的应用与发展。该数据集在相关领域的影响力显著,已成为对话摘要研究的重要基准之一。
当前挑战
Samsum数据集在解决对话摘要问题时面临多重挑战。首先,对话文本通常具有非结构化和多轮交互的特点,如何从中提取关键信息并生成连贯的摘要是一个复杂的问题。其次,对话中常包含口语化表达、省略和上下文依赖,这对模型的语义理解和生成能力提出了更高要求。在构建过程中,研究人员需确保对话与摘要之间的高质量对齐,同时避免引入偏见或噪声。此外,数据集的规模虽较大,但如何进一步提升其多样性和代表性,以覆盖更广泛的对话场景,仍是一个亟待解决的问题。
常用场景
经典使用场景
Samsum数据集在对话摘要领域具有广泛的应用,尤其在自然语言处理(NLP)研究中,它被用于训练和评估对话摘要模型。该数据集包含了大量真实对话及其对应的人工标注摘要,为研究者提供了一个标准的基准,用于测试模型在生成简洁且信息丰富的摘要方面的能力。通过使用Samsum数据集,研究者能够深入探讨如何从复杂的对话中提取关键信息,并将其转化为连贯的摘要。
实际应用
在实际应用中,Samsum数据集为开发智能对话系统提供了重要支持。例如,在客户服务领域,基于该数据集训练的模型能够自动生成客户与客服人员之间的对话摘要,帮助快速回顾和总结服务内容。此外,该数据集还可用于教育领域,辅助教师生成课堂讨论的摘要,提升教学效率。通过应用Samsum数据集,企业和教育机构能够显著提升信息处理的自动化水平,减少人工干预。
衍生相关工作
Samsum数据集自发布以来,催生了大量相关研究工作。例如,基于该数据集的BERT-based模型在对话摘要任务中取得了显著进展,展示了预训练语言模型在摘要生成中的潜力。此外,研究者还利用Samsum数据集开发了多任务学习框架,将对话摘要与其他NLP任务结合,进一步提升了模型的泛化能力。这些工作不仅推动了对话摘要技术的发展,也为其他NLP任务提供了新的研究思路。
以上内容由遇见数据集搜集并总结生成


