norwegian-dynaword
收藏Hugging Face2026-01-25 更新2026-01-26 收录
下载链接:
https://huggingface.co/datasets/danish-foundation-models/norwegian-dynaword
下载链接
链接失效反馈官方服务:
资源简介:
Norwegian Dynaword是一个收集自不同领域的挪威语自由文本数据集集合。所有数据集都是开放许可的,适合用于训练大型语言模型。该数据集持续开发,会随着新数据集的可用而更新。数据集包含来自不同领域的文本(如法律、书籍、社交媒体等),并提供了详细的统计数据、加载方法、语言信息和许可证信息。
创建时间:
2026-01-25
原始信息汇总
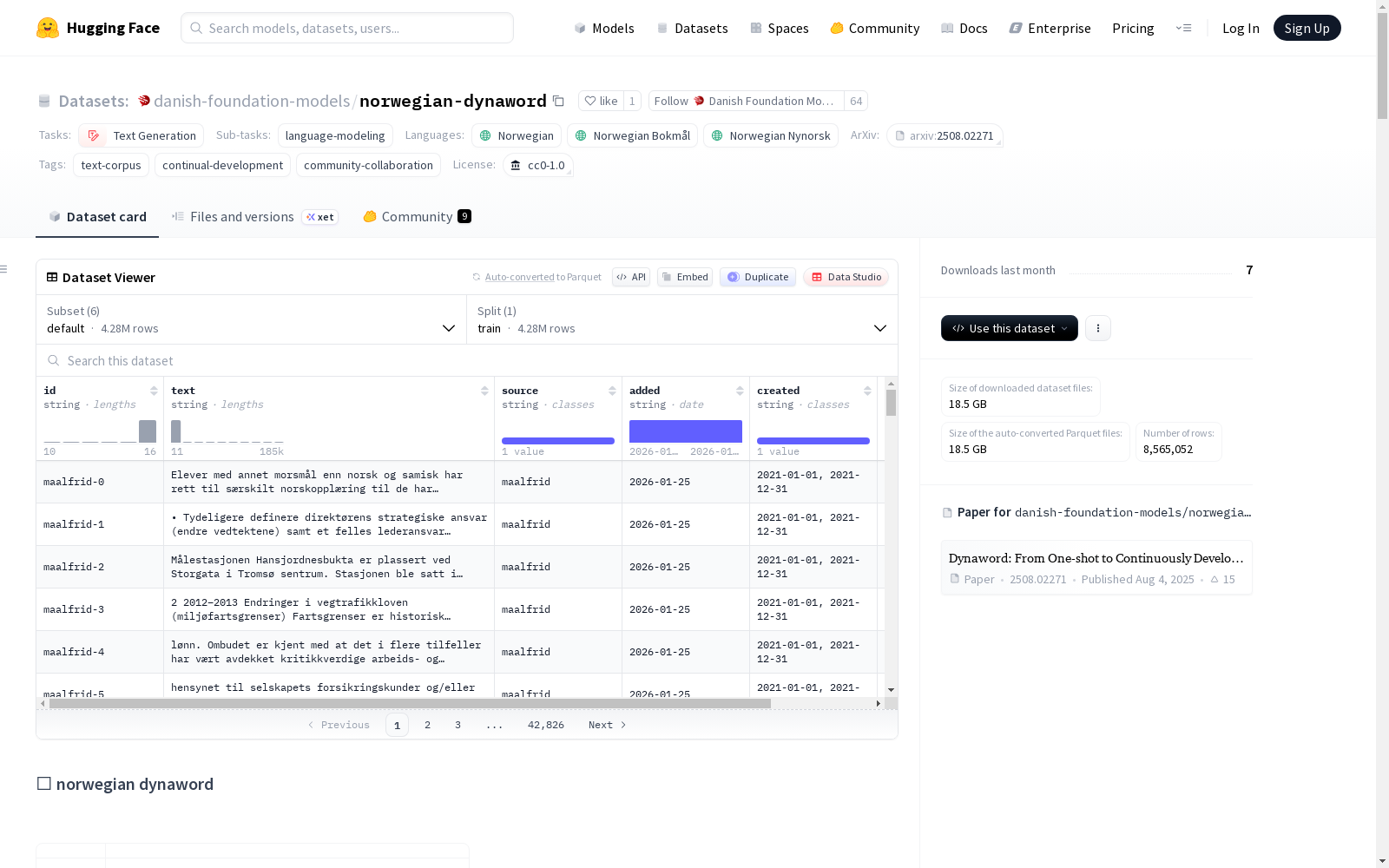
Norwegian Dynaword 数据集概述
数据集基本信息
- 数据集名称: Norwegian Dynaword
- 维护者: Danish Foundation Models
- 版本: 0.0.3
- 许可证: 数据集集合(元数据、质量控制等)采用 CC-0 许可证。构成数据(文本)的许可证因来源而异,具体见源数据表。
- 任务类别: 文本生成
- 任务ID: 语言建模
- 标签: 文本语料库、持续开发、社区协作
数据集描述
- 数据集摘要: Norwegian Dynaword 是一个来自不同领域的挪威语自由形式文本数据集的集合。该数据集中的所有数据集都是开放许可的,并被允许用于训练大型语言模型。该数据集是持续开发的,会随着新数据集的可用而积极更新。
- 样本数量: 3.59M
- 词元数量 (Llama 3): 2.37B
- 平均文档长度(词元数,最小,最大): 660.92 (4, 62.24K)
语言与领域
- 包含语言:
- 挪威语 (nor-Latn),包括书面挪威语 (nob-Latn) 和新挪威语 (nno-Latn)。
- 由于语码转换,可能包含少量英语;由于历史关系和语言相似性导致的错误分类,可能包含少量丹麦语。
- 领域分布:
领域 来源 词元数量 网络 maalfrid 2.23B 新闻 ncc-newspapers 143.73M 总计 2.37B
数据集结构
- 数据配置:
default: 包含所有数据。maalfrid: 仅包含 maalfrid 子集。ncc-newspapers: 仅包含 ncc-newspapers 子集。
- 数据拆分: 整个语料库仅提供
train拆分。 - 数据实例(字段):
id(str): 每个文档的唯一标识符。text(str): 文档内容。source(str): 文档来源。added(str): 文档被添加到此集合的日期。created(str): 文档原始创建日期范围。token_count(int): 使用 Llama 8B 分词器计算的样本词元数。
源数据与许可
| 来源 | 描述 | 领域 | 词元数量 | 许可证 |
|---|---|---|---|---|
| maalfrid | 来自挪威机构网站的挪威语内容 | 网络 | 2.23B | NLOD 2.0 |
| ncc-newspapers | 源自 NCC 的 OCR 报纸文本 | 新闻 | 143.73M | CC-0 |
| 总计 | 2.37B |
创建与维护
- 策划理由: 收集和策划这些数据集是为了提供开放许可的挪威语数据,主要用于开发语言模型,也可能用于研究跨领域的语言发展和差异。
- 注释: 数据通常不包含注释,仅包含每个样本的元数据(如所属领域)。
- 数据处理: 数据收集和处理因数据集而异,记录在各自的数据表中。此外,运行一系列自动化质量检查以确保格式、质量和文档质量。
- 贡献: 欢迎对数据集做出贡献,包括新的数据源、改进的数据过滤和其他增强功能。
引用信息
如果使用此工作,请引用介绍 Dynaword 方法的科学文章:
Enevoldsen, K.C., et al. (2025). Dynaword: From One-shot to Continuously Developed Datasets. arXiv preprint arXiv:2508.02271. 建议同时引用相关的源数据集。
注意事项
- 个人和敏感信息: 据我们所知,数据集不包含识别性取向、政治信仰、宗教或健康的信息,也不包含任何非公开或非历史人物的个人标识符。
- 偏见、风险和限制: 该集合中的某些作品是历史作品,因此反映了其时代的语言、文化和意识形态规范。其中包含的观点、假设和偏见可能符合当时的特点,但按当代标准可能被视为具有冒犯性或排他性。
- 通知和下架政策: 我们根据允许再分发的许可证重新分发文件。如果您对文件的许可有疑问,或认为数据包含侵犯您版权的材料,请通过讨论区联系我们。我们将通过从语料库的下一个版本中删除受影响的来源来配合合法请求。
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,构建高质量语料库是推动语言模型发展的基石。Norwegian Dynaword数据集的构建采用了动态演进策略,通过整合多个公开许可的挪威语文本资源,实现了语料的持续扩展。其构建过程主要依赖于众包方式,从挪威机构网站、OCR处理的报纸等多样化领域收集原始文本,并经过自动化质量检查,确保数据格式规范与文档完整性。该数据集遵循开放许可协议,支持社区协作贡献,体现了数据收集的前瞻性与可扩展性。
特点
作为挪威语文本资源的重要集合,Norwegian Dynaword展现出多方面的显著特点。该数据集覆盖了网络文本与新闻报纸等多个领域,总规模达到359万样本,包含约23.7亿个令牌,平均文档长度约为661个令牌。其语言构成以挪威语为主,同时涵盖了博克马尔语和新挪威语两种官方变体,并可能包含少量英语和丹麦语文本。数据集采用模块化结构,支持按子集加载,且每个样本均附有来源、创建时间等元数据,为语言分析与模型训练提供了丰富的上下文信息。
使用方法
在应用层面,Norwegian Dynaword为研究人员和开发者提供了灵活便捷的使用途径。通过Hugging Face的datasets库,用户可直接加载整个数据集或特定子集,如maalfrid或ncc-newspapers。数据集支持流式读取模式,适合处理大规模语料;同时允许指定版本修订号,确保实验的可复现性。该语料库主要适用于文本生成和语言建模任务,也可用于跨领域语言演变研究,其开放许可特性为学术与商业应用提供了广泛的可能性。
背景与挑战
背景概述
挪威语Dynaword数据集由丹麦基础模型研究团队于2025年构建,旨在为挪威语大规模语言模型训练提供开放许可的文本资源。该数据集汇集了来自网络、新闻等多个领域的自由文本,涵盖博克马尔语和新挪威语两种主要书面变体,总规模达到23.7亿标记。作为动态发展的语料库,其采用持续更新机制,随着新数据源的加入而不断扩展,为低资源语言的自然语言处理研究提供了重要基础设施。
当前挑战
该数据集致力于解决挪威语文本生成与语言建模任务中高质量训练数据稀缺的核心挑战。构建过程面临多重困难:首先需要从分散的开放数据源中协调不同许可协议,确保法律合规性;其次需处理历史文本中的语言变体差异与当代语言规范之间的平衡问题;最后在持续更新机制下,维持数据质量一致性、避免重复内容以及处理代码切换现象构成了持续的技术挑战。
常用场景
经典使用场景
在自然语言处理领域,挪威语Dynaword数据集为挪威语大规模语言模型的训练提供了核心语料支持。该数据集整合了来自网络、新闻等多个领域的开放许可文本,覆盖了书面挪威语和新挪威语两种官方变体。其动态更新的特性确保了语料库能够持续纳入新兴的文本资源,为构建适应语言演变的模型奠定了数据基础。
解决学术问题
该数据集有效缓解了挪威语自然语言处理研究中高质量、大规模开放语料稀缺的困境。通过汇集并规范化多源异构文本,它为语言模型预训练、跨领域语言差异分析以及历史语言变迁研究提供了标准化数据支撑。其明确的许可信息和元数据标注,亦促进了语料使用的合规性与可复现性,推动了北欧语言技术研究的开放科学发展。
衍生相关工作
围绕该数据集,研究社区已衍生出多项经典工作。其遵循的Dynaword框架论文系统阐述了持续开发数据集的方法论,为多语言语料库建设提供了范式参考。基于该语料训练的挪威语基础模型,进一步推动了下游任务如文本摘要、情感分析等应用的性能提升。相关数据质量控制与贡献流程的规范化,亦激励了社区协作与语料生态的持续完善。
以上内容由遇见数据集搜集并总结生成


