MNLP_M2_mcqa_dataset_2
收藏Hugging Face2025-05-27 更新2025-05-28 收录
下载链接:
https://huggingface.co/datasets/youssefbelghmi/MNLP_M2_mcqa_dataset_2
下载链接
链接失效反馈官方服务:
资源简介:
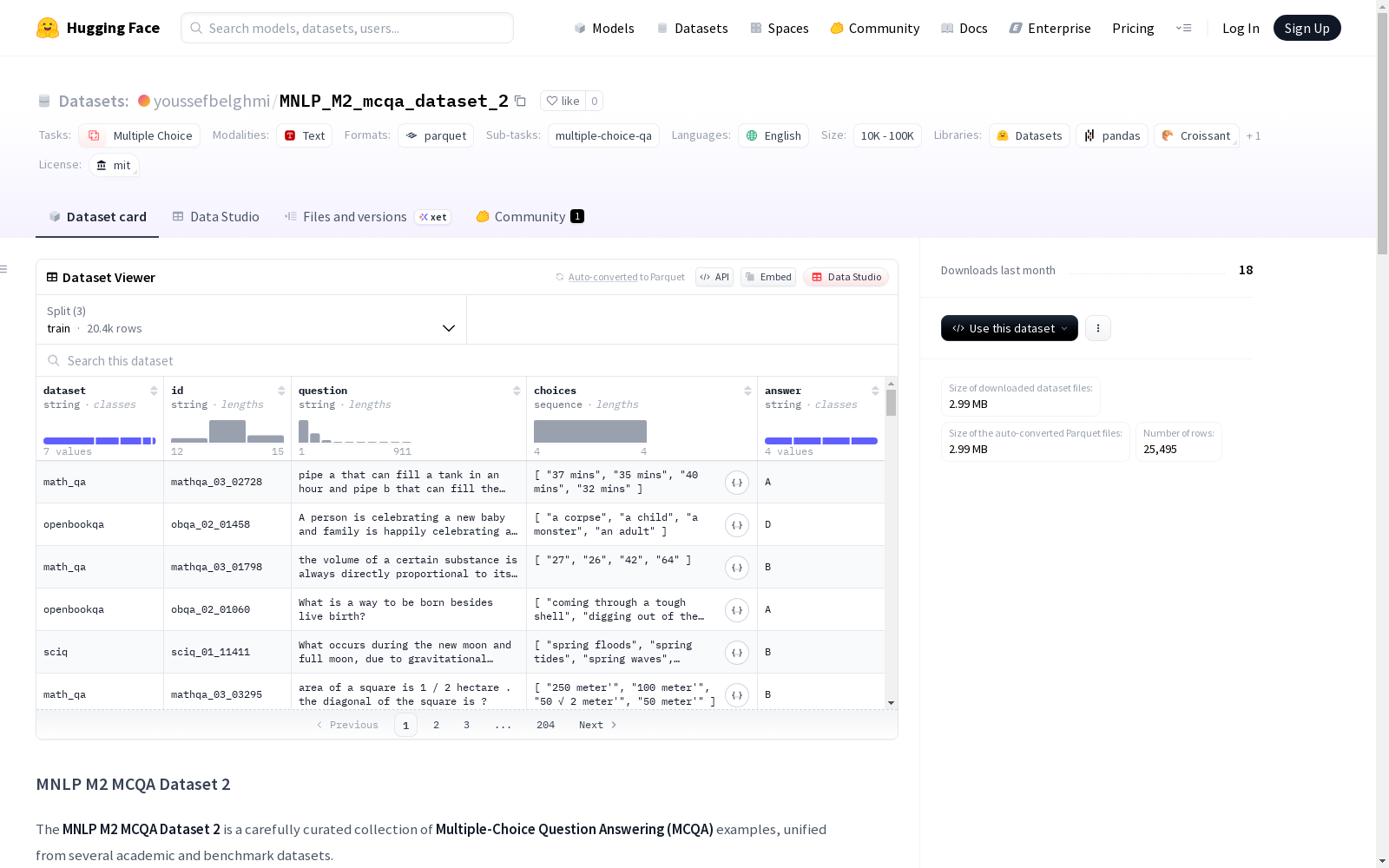
MNLP M2 MCQA数据集2是一个精心策划的多项选择题问答(MCQA)示例集合,从多个学术和基准数据集中统一整理而来。该数据集作为EPFL大学现代自然语言处理课程的一部分,旨在用于训练和评估在STEM领域(科学、技术、工程、数学)的多项选择题问答任务模型。数据集包含约25,000个多项选择题,涵盖广泛的主题,并提供7个不同来源的数据,包括SciQ、OpenBookQA、MathQA等。
创建时间:
2025-05-25
原始信息汇总
MNLP M2 MCQA Dataset 2 概述
数据集基本信息
- 创建方式:专家生成
- 语言:英语
- 许可协议:MIT
- 多语言性:单语言
- 规模:10K<n<100K
- 任务类别:多项选择
- 任务ID:multiple-choice-qa
- 数据集名称:MNLP M2 MCQA Dataset
数据集描述
MNLP M2 MCQA Dataset 2 是一个精心策划的多项选择问答(MCQA)数据集,整合了多个学术和基准数据集。该数据集由 EPFL 的 CS-552: Modern NLP 课程(2025年春季)开发,旨在用于训练和评估多项选择问答任务模型,特别是在 STEM 和常识领域。
关键特征
- 问题数量:约25,000个MCQA问题
- 来源多样性:7个不同来源,包括
SciQ、OpenBookQA、MathQA、ARC-Easy、ARC-Challenge、HPCPerfOpt-MCQA和GPT生成的STEM问题 - 问题格式:每个问题有4个选项(A–D)和一个正确答案
- 覆盖范围:科学、技术、工程、数学和常识
数据集结构
每个示例为一个字典,包含以下字段:
| 字段 | 类型 | 描述 |
|---|---|---|
dataset |
string |
来源数据集(如 sciq、openbookqa 等) |
id |
string |
问题的唯一标识符 |
question |
string |
问题文本 |
choices |
list |
4个答案选项(对应A–D) |
answer |
string |
正确答案选项("A"、"B"、"C" 或 "D") |
示例
json { "dataset": "sciq", "id": "sciq_01_00042", "question": "What does a seismograph measure?", "choices": ["Earthquakes", "Rainfall", "Sunlight", "Temperature"], "answer": "A" }
来源数据集
该数据集整合了多个高质量的MCQA来源,以支持STEM教育和推理的研究和微调。完整语料库包含来自以下来源的 25,495个多项选择题:
| 来源(Hugging Face) | 名称 | 数量 | 描述与作用 |
|---|---|---|---|
allenai/sciq |
SciQ | 11,679 | 科学问题(物理、化学、生物、地球科学),提供平衡的STEM问题 |
allenai/openbookqa |
OpenBookQA | 4,957 | 需要多步推理和常识的科学考试风格问题 |
allenai/math_qa |
MathQA | 5,500 | 数学应用题,引入数值推理和问题解决 |
allenai/ai2_arc (config: ARC-Easy) |
ARC-Easy | 2,140 | 中学水平的科学问题,测试基本STEM理解和事实回忆 |
allenai/ai2_arc (config: ARC-Challenge) |
ARC-Challenge | 1,094 | 需要推理和推断的更难的科学问题 |
sharmaarushi17/HPCPerfOpt-MCQA |
HPCPerfOpt-MCQA | 85 | 高性能计算(HPC)性能优化问题 |
local GPT-generated |
ChatGPT | 40 | 使用GPT-4生成的STEM和计算主题问题 |
数据集划分
- 训练集(约80%):用于训练MCQA模型
- 验证集(约10%):用于调整和监控训练过程中的性能
- 测试集(约10%):用于对未见问题的最终评估
适用领域
该数据集适用于多项选择问答任务,特别是在 STEM 领域(科学、技术、工程、数学)。
作者
该数据集由 Youssef Belghmi 创建并发布,作为 EPFL CS-552: Modern NLP 课程(2025年春季)的一部分。
搜集汇总
数据集介绍
构建方式
在自然语言处理领域中,多选问答数据集的构建需要严谨的学术基础。MNLP M2 MCQA数据集通过整合七个权威学术资源,包括SciQ、OpenBookQA、MathQA等标准化题库,采用专家标注与自动化校验相结合的方式,确保每个问题均包含四个标准化选项和唯一正确答案。该构建过程特别注重STEM领域知识的覆盖广度,通过去重和格式统一处理,最终形成包含25,495个问题的结构化语料库。
使用方法
针对机器学习工作流程的标准化需求,数据集已预划分为训练集、验证集和测试集,分别占比80%、10%和10%。研究者可通过HuggingFace平台直接加载数据,每个样本以字典结构呈现问题文本、选项列表和答案标识。该设计特别适配Transformer架构的微调任务,支持端到端的多选问答模型开发,同时预留的源数据集字段便于进行领域特异性性能分析。
背景与挑战
背景概述
MNLP M2 MCQA Dataset 2诞生于2025年春季,由EPFL大学CS-552现代自然语言处理课程团队主导开发,核心研究人员Youssef Belghmi致力于构建一个面向STEM领域的多选问答基准。该数据集整合了SciQ、OpenBookQA等七个权威子集,涵盖科学、技术、工程和数学等多学科知识,旨在推动机器在复杂学科推理能力上的进步。其超过2.5万道四选一问题的规模,为教育智能和知识推理模型提供了重要实验基础,显著丰富了自然语言处理在学术评估场景的应用生态。
当前挑战
该数据集直面STEM领域多选问答的核心难题:如何让模型在涉及数理逻辑、科学事实与常识推理的交叉命题中保持精准判断。构建过程中需攻克多源数据格式统一、学科知识体系平衡等挑战,例如将MathQA的数学符号与OpenBookQA的开放知识推理进行标准化对齐,同时确保ARC挑战集的高难度问题与基础科学问题的梯度分布合理。此外,HPC等小众领域数据的稀缺性也考验着数据集的代表性和泛化能力。
常用场景
经典使用场景
在自然语言处理领域,MNLP M2 MCQA数据集作为多选问答任务的重要资源,主要应用于STEM学科的知识评估与模型训练。该数据集通过整合七个权威子集,构建了覆盖科学、技术、工程和数学的综合性题库,为研究者提供了标准化的评估基准。其经典使用场景包括训练语言模型进行多步推理、事实检索以及选项分析,尤其在教育智能系统中,能够有效模拟学术考试环境,提升模型对复杂科学问题的解析能力。
解决学术问题
该数据集致力于解决自然语言处理中多项核心学术问题,例如知识推理的泛化性挑战和跨领域迁移学习的局限性。通过融合ARC挑战集的高阶推理题与MathQA的数学逻辑问题,它为模型提供了从基础事实记忆到复杂推理的渐进式训练样本。这种设计显著降低了模型对表面模式的依赖,推动了可解释AI研究,并为STEM教育中的自适应学习系统奠定了数据基础。
实际应用
在实际应用层面,该数据集已嵌入智能辅导系统与在线教育平台,用于生成个性化学习路径和实时知识诊断。例如,基于HPCPerfOpt子集的专业内容,可辅助高性能计算领域的技能评估;而SciQ和OpenBookQA的融合则支持K-12科学课程的自动化命题。这些应用不仅提升了教育资源的可及性,还为工业界提供了可部署的轻量级问答引擎解决方案。
数据集最近研究
最新研究方向
在自然语言处理领域,多项选择题回答任务正逐渐成为评估模型推理能力的重要基准。MNLP M2 MCQA数据集整合了多个高质量来源,涵盖科学、技术、工程和数学等广泛主题,为研究社区提供了丰富的实验材料。当前前沿研究聚焦于提升模型在复杂推理场景中的表现,特别是在需要多步逻辑推断和常识知识的科学问题解答上。该数据集的应用不仅推动了教育技术中自适应学习系统的发展,还为大型语言模型在专业领域的微调提供了关键支持。随着人工智能在教育评估和知识检索中的深入应用,此类数据集的重要性日益凸显,成为连接学术研究与实际应用的重要桥梁。
以上内容由遇见数据集搜集并总结生成


