Firoj/HumAID
收藏Hugging Face2022-05-18 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/Firoj/HumAID
下载链接
链接失效反馈官方服务:
资源简介:
# Dataset Card for HumAID
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://crisisnlp.qcri.org/humaid_dataset
- **Repository:** https://crisisnlp.qcri.org/data/humaid/humaid_data_all.zip
- **Paper:** https://ojs.aaai.org/index.php/ICWSM/article/view/18116/17919
<!-- - **Leaderboard:** [Needs More Information] -->
<!-- - **Point of Contact:** [Needs More Information] -->
### Dataset Summary
The HumAID Twitter dataset consists of several thousands of manually annotated tweets that has been collected during 19 major natural disaster events including earthquakes, hurricanes, wildfires, and floods, which happened from 2016 to 2019 across different parts of the World. The annotations in the provided datasets consists of following humanitarian categories. The dataset consists only english tweets and it is the largest dataset for crisis informatics so far.
** Humanitarian categories **
- Caution and advice
- Displaced people and evacuations
- Dont know cant judge
- Infrastructure and utility damage
- Injured or dead people
- Missing or found people
- Not humanitarian
- Other relevant information
- Requests or urgent needs
- Rescue volunteering or donation effort
- Sympathy and support
The resulting annotated dataset consists of 11 labels.
### Supported Tasks and Benchmark
The dataset can be used to train a model for multiclass tweet classification for disaster response. The benchmark results can be found in https://ojs.aaai.org/index.php/ICWSM/article/view/18116/17919.
Dataset is also released with event-wise and JSON objects for further research.
Full set of the dataset can be found in https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/A7NVF7
### Languages
English
## Dataset Structure
### Data Instances
```
{
"tweet_text": "@RT_com: URGENT: Death toll in #Ecuador #quake rises to 233 \u2013 President #Correa #1 in #Pakistan",
"class_label": "injured_or_dead_people"
}
```
### Data Fields
* tweet_text: corresponds to the tweet text.
* class_label: corresponds to a label assigned to a given tweet text
### Data Splits
* Train
* Development
* Test
## Dataset Creation
<!-- ### Curation Rationale -->
### Source Data
#### Initial Data Collection and Normalization
Tweets has been collected during several disaster events.
### Annotations
#### Annotation process
AMT has been used to annotate the dataset. Please check the paper for a more detail.
#### Who are the annotators?
- crowdsourced
<!-- ## Considerations for Using the Data -->
<!-- ### Social Impact of Dataset -->
<!-- ### Discussion of Biases -->
<!-- [Needs More Information] -->
<!-- ### Other Known Limitations -->
<!-- [Needs More Information] -->
## Additional Information
### Dataset Curators
Authors of the paper.
### Licensing Information
- cc-by-nc-4.0
### Citation Information
```
@inproceedings{humaid2020,
Author = {Firoj Alam, Umair Qazi, Muhammad Imran, Ferda Ofli},
booktitle={Proceedings of the Fifteenth International AAAI Conference on Web and Social Media},
series={ICWSM~'21},
Keywords = {Social Media, Crisis Computing, Tweet Text Classification, Disaster Response},
Title = {HumAID: Human-Annotated Disaster Incidents Data from Twitter},
Year = {2021},
publisher={AAAI},
address={Online},
}
```
# HumAID 数据集卡片
## 目录
- [数据集描述](#dataset-description)
- [数据集概述](#dataset-summary)
- [支持任务与评测基准](#supported-tasks-and-leaderboards)
- [语言](#languages)
- [数据集结构](#dataset-structure)
- [数据实例](#data-instances)
- [数据字段](#data-fields)
- [数据划分](#data-splits)
- [数据集构建](#dataset-creation)
- [构建初衷](#curation-rationale)
- [源数据](#source-data)
- [标注信息](#annotations)
- [个人与敏感信息](#personal-and-sensitive-information)
- [数据集使用注意事项](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏见讨论](#discussion-of-biases)
- [其他已知局限性](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集维护者](#dataset-curators)
- [授权信息](#licensing-information)
- [引用信息](#citation-information)
## 数据集描述
- **主页**:https://crisisnlp.qcri.org/humaid_dataset
- **代码仓库**:https://crisisnlp.qcri.org/data/humaid/humaid_data_all.zip
- **相关论文**:https://ojs.aaai.org/index.php/ICWSM/article/view/18116/17919
<!-- - **评测基准**:[需补充更多信息] -->
<!-- - **联系方式**:[需补充更多信息] -->
### 数据集概述
HumAID 推特(Twitter)数据集包含数千条人工标注的推文,这些推文采集自2016年至2019年间全球19起重大自然灾害事件,涵盖地震、飓风、山火与洪水等灾害类型。本数据集的标注涵盖以下人道主义相关类别。本数据集仅包含英文推文,是目前危机信息学领域规模最大的公开数据集。
**人道主义类别**
- 警示与建议
- 流离失所者与疏散行动
- 无法判断
- 基础设施与公共设施损毁
- 人员伤亡
- 人员失踪/获救
- 非人道主义相关内容
- 其他相关信息
- 请求或紧急需求
- 救援、志愿或捐赠行动
- 同情与支持
最终的标注数据集共包含11个分类标签。
### 支持任务与评测基准
本数据集可用于训练面向灾害响应的多分类推文分类模型。相关评测基准结果可参见https://ojs.aaai.org/index.php/ICWSM/article/view/18116/17919。
本数据集同时提供按事件划分的JSON格式数据,以供后续研究使用。
数据集完整版本可通过以下链接获取:https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/A7NVF7
### 语言
英语
## 数据集结构
### 数据实例
{
"tweet_text": "@RT_com: URGENT: Death toll in #Ecuador #quake rises to 233 u2013 President #Correa #1 in #Pakistan",
"class_label": "injured_or_dead_people"
}
### 数据字段
* tweet_text:对应推文文本内容
* class_label:对应为给定推文分配的分类标签
### 数据划分
* 训练集
* 开发集
* 测试集
## 数据集构建
<!-- ### 构建初衷 -->
### 源数据
#### 初始数据采集与标准化
推文采集自多起灾害事件。
### 标注信息
#### 标注流程
本数据集采用AMT(Amazon Mechanical Turk,亚马逊机械 Turk)进行标注,详细信息请参见相关论文。
#### 标注人员来源
- 众包标注人员
<!-- ## 数据集使用注意事项 -->
<!-- ### 数据集的社会影响 -->
<!-- ### 偏见讨论 -->
<!-- [需补充更多信息] -->
<!-- ### 其他已知局限性 -->
<!-- [需补充更多信息] -->
## 附加信息
### 数据集维护者
论文作者。
### 授权信息
- cc-by-nc-4.0
### 引用信息
@inproceedings{humaid2020,
Author = {Firoj Alam, Umair Qazi, Muhammad Imran, Ferda Ofli},
booktitle={Proceedings of the Fifteenth International AAAI Conference on Web and Social Media},
series={ICWSM~'21},
Keywords = {Social Media, Crisis Computing, Tweet Text Classification, Disaster Response},
Title = {HumAID: Human-Annotated Disaster Incidents Data from Twitter},
Year = {2021},
publisher={AAAI},
address={Online},
}
提供机构:
Firoj
原始信息汇总
数据集概述
数据集名称
HumAID
数据集总结
HumAID Twitter数据集包含数千条手动标注的推文,这些推文收集自2016年至2019年间发生的19次重大自然灾害事件,包括地震、飓风、野火和洪水等。该数据集仅包含英文推文,是目前为止最大的危机信息学数据集。数据集中的标注包括以下人道主义类别:
- 警告和建议
- 流离失所者和疏散
- 不知道无法判断
- 基础设施和公用设施损坏
- 受伤或死亡人员
- 失踪或找到人员
- 非人道主义
- 其他相关信息
- 请求或紧急需求
- 救援志愿或捐赠努力
- 同情和支持
数据集包含11个标签。
支持的任务和基准
该数据集可用于训练多类别推文分类模型,用于灾害响应。基准测试结果可在以下链接找到:HumAID Paper。
语言
英语
数据集结构
数据实例
每个数据实例包含以下字段:
tweet_text: 推文文本class_label: 分配给推文文本的标签
数据字段
tweet_text: 推文内容class_label: 推文的类别标签
数据分割
- 训练集
- 开发集
- 测试集
数据集创建
源数据
推文在多个灾害事件期间收集。
标注
- 标注过程:使用AMT进行数据集标注。
- 标注者:众包
附加信息
数据集管理者
论文作者
许可信息
- cc-by-nc-4.0
引用信息
@inproceedings{humaid2020, Author = {Firoj Alam, Umair Qazi, Muhammad Imran, Ferda Ofli}, booktitle={Proceedings of the Fifteenth International AAAI Conference on Web and Social Media}, series={ICWSM~21}, Keywords = {Social Media, Crisis Computing, Tweet Text Classification, Disaster Response}, Title = {HumAID: Human-Annotated Disaster Incidents Data from Twitter}, Year = {2021}, publisher={AAAI}, address={Online}, }
搜集汇总
数据集介绍
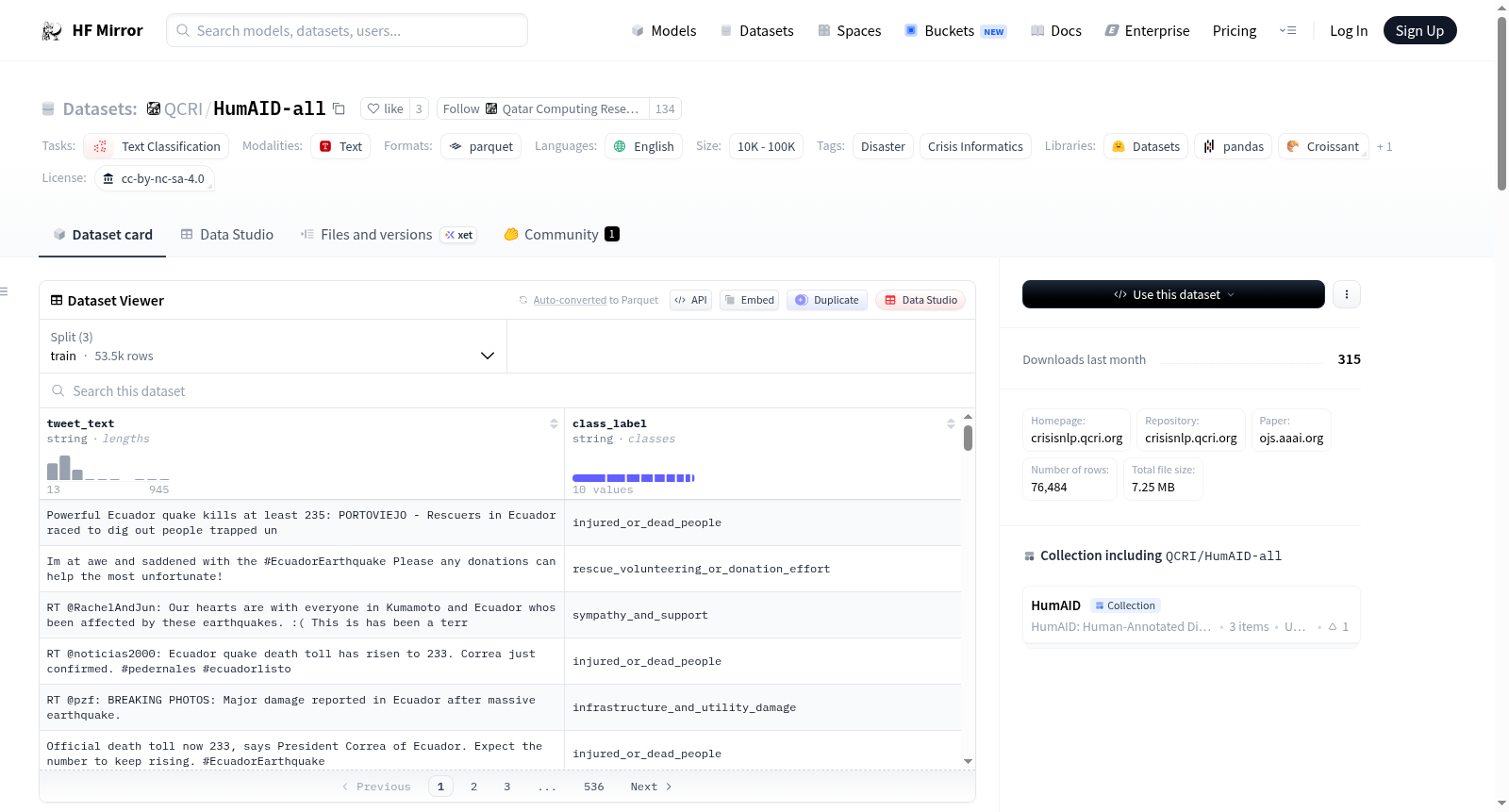
构建方式
在灾害信息学领域,数据集的构建需兼顾时效性与准确性。HumAID数据集的构建过程始于从Twitter平台收集2016年至2019年间全球19起重大自然灾害事件的相关推文,涵盖地震、飓风、野火和洪水等多种灾害类型。随后,研究团队通过亚马逊众包平台(AMT)进行人工标注,依据预先定义的人道主义类别对每条推文进行分类,确保标注过程具有可靠的人类判断参与。最终形成的标注数据集包含11个类别,总计超过7.6万条英文推文,分为训练集、开发集和测试集,为后续模型训练与评估提供了结构化基础。
特点
作为当前灾害信息学领域规模最大的英文推文数据集,HumAID的显著特点在于其广泛覆盖了多种灾害类型与地理区域,增强了数据集的代表性与泛化能力。该数据集精心定义了11个人道主义类别,包括伤亡报告、基础设施损坏、救援需求等,这些类别紧密贴合灾害响应实际需求,有助于模型深入理解灾害语境下的语义信息。此外,数据集以事件为单位进行组织,并提供了JSON格式的数据对象,为研究者开展跨事件分析或细粒度研究提供了便利,进一步拓展了其在灾害管理与社会计算中的应用潜力。
使用方法
该数据集主要用于多类别推文分类任务,旨在支持灾害响应中的信息自动分类系统。使用者可首先加载数据集的训练、开发和测试分割,利用推文文本与对应的人道主义标签进行监督学习模型训练,例如基于Transformer的预训练语言模型。在模型评估阶段,可参考原论文中报告的基准性能,对比不同方法在灾害语境下的分类效果。此外,数据集的事件级结构允许研究者进行跨灾害事件的分析,或结合其他时空数据探索灾害信息的传播模式,从而为应急决策提供数据驱动的见解。
背景与挑战
背景概述
在危机信息学领域,社交媒体数据已成为灾害响应与管理的关键信息来源。HumAID数据集由卡塔尔计算研究所等机构的研究团队于2021年构建,聚焦于2016年至2019年间全球19起重大自然灾害事件中的推特文本。该数据集通过人工标注,将推文归类为11种人道主义类别,旨在为灾害期间的实时信息分类提供标准化语料。作为目前规模最大的危机信息学英文数据集,HumAID不仅推动了灾害情境下自然语言处理模型的发展,还为跨学科研究提供了重要的数据基础,促进了计算社会科学与应急管理的深度融合。
当前挑战
HumAID数据集面临的挑战主要体现在两个方面:在领域问题层面,灾害推文的分类需处理文本的模糊性、多义性以及噪声干扰,例如讽刺表达或非正式语言可能影响模型对‘同情与支持’与‘非人道主义’类别的区分精度;同时,数据的不平衡分布使得少数类别如‘失踪或找到人员’的识别成为难点。在构建过程中,挑战源于灾害事件的动态性与多语言混杂环境,标注者需在时间压力下保持类别判断的一致性,而众包标注机制可能引入主观偏差,且推文的地理位置信息缺失限制了时空分析的应用潜力。
常用场景
经典使用场景
在危机信息学领域,HumAID数据集为研究者提供了一个基于Twitter文本的多类别分类基准。该数据集涵盖了地震、飓风、野火和洪水等19种重大自然灾害事件,通过人工标注将推文划分为11类人道主义相关类别。这一资源使得学者能够构建和评估模型,以自动识别灾害期间社交媒体中的关键信息,从而优化应急响应策略。
实际应用
在实际灾害响应中,HumAID数据集训练的模型能够实时扫描社交媒体内容,自动归类出涉及伤亡报告、基础设施损坏、救援需求等关键信息。这种能力帮助应急管理机构快速识别灾区迫切需求,优先处理紧急情况,提升救援效率,并为公众提供准确的警示和建议,从而增强整体社会的抗灾韧性。
衍生相关工作
基于HumAID数据集,多项经典研究工作得以展开,包括开发先进的深度学习分类架构、探索跨灾害事件的迁移学习策略,以及构建多模态危机分析系统。这些衍生成果不仅推动了危机信息学领域的技术前沿,还为后续数据集如CrisisBench等的构建提供了方法论借鉴,形成了持续演进的研究脉络。
以上内容由遇见数据集搜集并总结生成


