资源简介:
---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: text
dtype: string
- name: speaker_id
dtype: int64
- name: age
dtype: int64
- name: sex
dtype: string
- name: dialect
dtype: string
- name: recording_datetime
dtype: string
splits:
- name: train
num_bytes: 55199435558.0
num_examples: 182605
- name: test
num_bytes: 8894080220.0
num_examples: 54747
download_size: 5358057252
dataset_size: 64093515778.0
size_categories:
- 100K<n<1M
license: cc0-1.0
task_categories:
- automatic-speech-recognition
- text-to-speech
language:
- da
pretty_name: NST-da
---
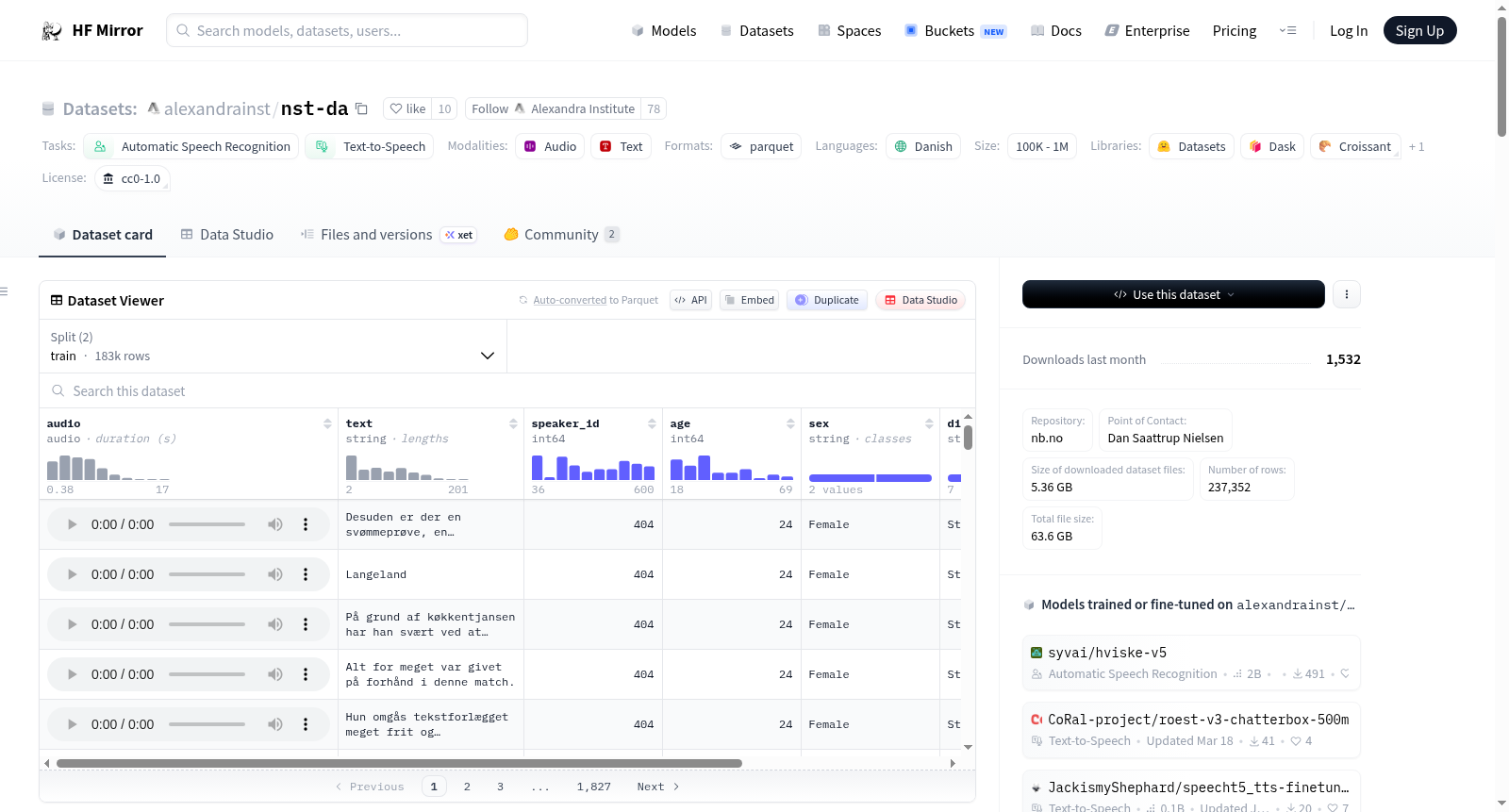
# Dataset Card for NST-da
## Dataset Description
- **Repository:** <https://www.nb.no/sprakbanken/en/resource-catalogue/oai-nb-no-sbr-55/>
- **Point of Contact:** [Dan Saattrup Nielsen](mailto:dan.nielsen@alexandra.dk)
- **Size of downloaded dataset files:** 5.36 GB
- **Size of the generated dataset:** 64.09 GB
- **Total amount of disk used:** 69.45 GB
### Dataset Summary
This dataset is an upload of the [NST Danish ASR Database (16 kHz) – reorganized](https://www.nb.no/sprakbanken/en/resource-catalogue/oai-nb-no-sbr-55/).
The training and test splits are the original ones.
### Supported Tasks and Leaderboards
Training automatic speech recognition is the intended task for this dataset. No leaderboard is active at this point.
### Languages
The dataset is available in Danish (`da`).
## Dataset Structure
### Data Instances
- **Size of downloaded dataset files:** 5.36 GB
- **Size of the generated dataset:** 64.09 GB
- **Total amount of disk used:** 69.45 GB
An example from the dataset looks as follows.
```
{
'audio': {
'path': 'dk14x404-05072000-1531_u0008121.wav',
'array': array([ 0.00265503, 0.00248718, 0.00253296, ..., -0.00030518,
-0.00035095, -0.00064087]),
'sampling_rate': 16000
},
'text': 'Desuden er der en svømmeprøve, en fremmedsprogstest samt en afsluttende samtale.',
'speaker_id': 404,
'age': 24,
'sex': 'Female',
'dialect': 'Storkøbenhavn',
'recording_datetime': '2000-07-05T15:31:14'
}
```
### Data Fields
The data fields are the same among all splits.
- `audio`: an `Audio` feature.
- `text`: a `string` feature.
- `speaker_id`: an `int64` feature.
- `age`: an `int64` feature.
- `sex`: a `string` feature.
- `dialect`: a `string` feature.
- `recording_datetime`: a `string` feature.
### Dataset Statistics
There are 183,205 samples in the training split, and 54,747 samples in the test split.
#### Speakers
There are 539 unique speakers in the training dataset and 56 unique speakers in the test dataset, where 54 of them are also present in the training set.
#### Age Distribution

#### Dialect Distribution

#### Sex Distribution

#### Transcription Length Distribution

## Dataset Creation
### Curation Rationale
There are not many large-scale ASR datasets in Danish.
### Source Data
The data originates from the now bankrupt company Nordisk språkteknologi (NST), whose data was transferred to the National Library of Norway, who subsequently released it into the public domain.
## Additional Information
### Dataset Curators
[Dan Saattrup Nielsen](https://saattrupdan.github.io/) from the [The Alexandra
Institute](https://alexandra.dk/) reorganised the dataset and uploaded it to the Hugging Face Hub.
### Licensing Information
The dataset is licensed under the [CC0
license](https://creativecommons.org/share-your-work/public-domain/cc0/).