matejklemen/vuamc
收藏Hugging Face2022-10-26 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/matejklemen/vuamc
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- expert-generated
language:
- en
language_creators:
- found
license:
- other
multilinguality:
- monolingual
pretty_name: VUA Metaphor Corpus
size_categories:
- 10K<n<100K
- 100K<n<1M
source_datasets: []
tags:
- metaphor-classification
- multiword-expression-detection
- vua20
- vua18
- mipvu
task_categories:
- text-classification
- token-classification
task_ids:
- multi-class-classification
---
# Dataset Card for VUA Metaphor Corpus
**Important note#1**: This is a slightly simplified but mostly complete parse of the corpus. What is missing are lemmas and some metadata that was not important at the time of writing the parser. See the section `Simplifications` for more information on this.
**Important note#2**: The dataset contains metadata - to ignore it and correctly remap the annotations, see the section `Discarding metadata`.
### Dataset Summary
VUA Metaphor Corpus (VUAMC) contains a selection of excerpts from BNC-Baby files that have been annotated for metaphor. There are four registers, each comprising about 50 000 words: academic texts, news texts, fiction, and conversations.
Words have been separately labelled as participating in multi-word expressions (about 1.5%) or as discarded for metaphor analysis (0.02%). Main categories include words that are related to metaphor (MRW), words that signal metaphor (MFlag), and words that are not related to metaphor. For metaphor-related words, subdivisions have been made between clear cases of metaphor versus borderline cases (WIDLII, When In Doubt, Leave It In). Another parameter of metaphor-related words makes a distinction between direct metaphor, indirect metaphor, and implicit metaphor.
### Supported Tasks and Leaderboards
Metaphor detection, metaphor type classification.
### Languages
English.
## Dataset Structure
### Data Instances
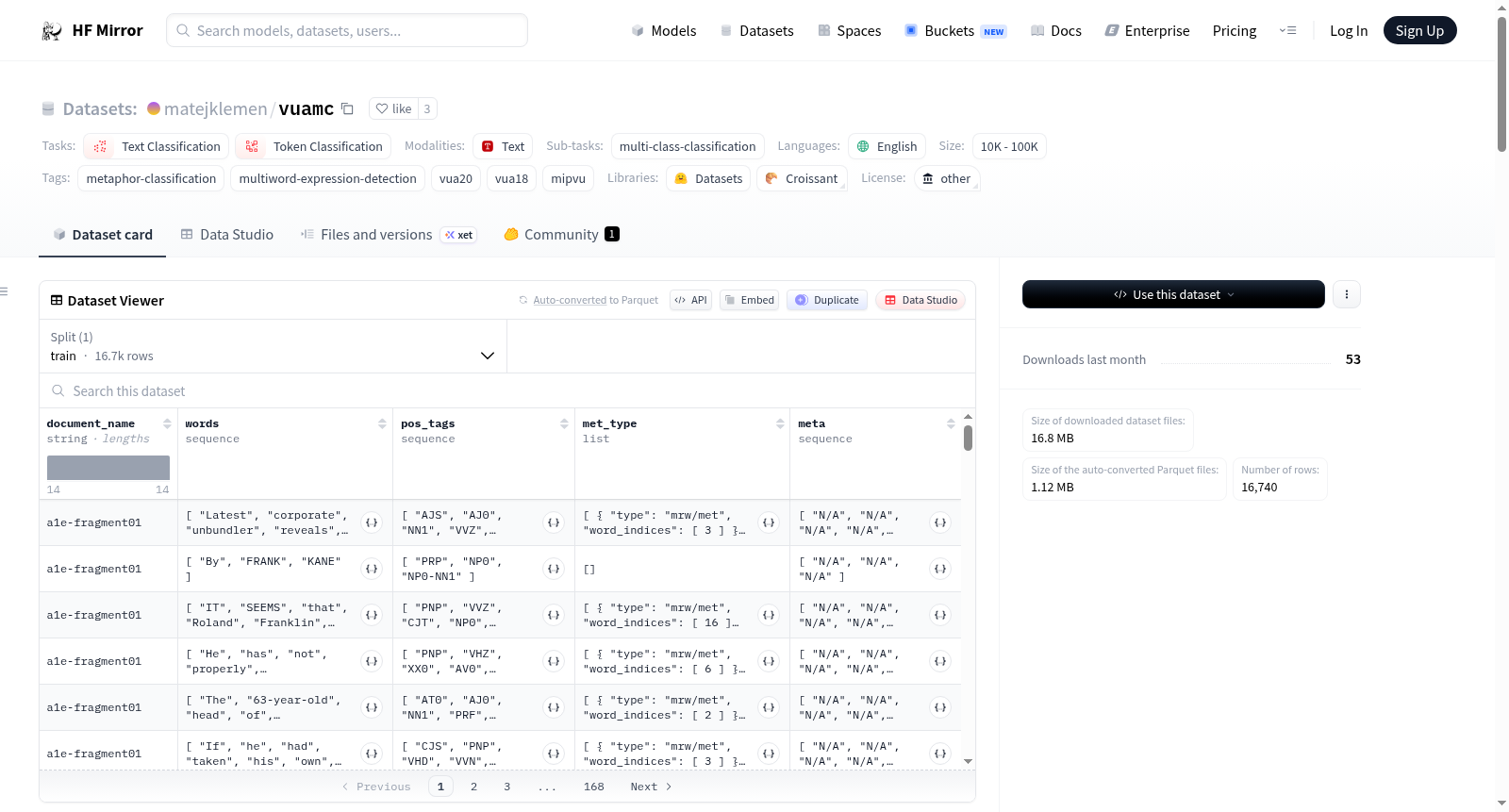
A sample instance from the dataset:
```
{
'document_name': 'kcv-fragment42',
'words': ['', 'I', 'think', 'we', 'should', 'have', 'different', 'holidays', '.'],
'pos_tags': ['N/A', 'PNP', 'VVB', 'PNP', 'VM0', 'VHI', 'AJ0', 'NN2', 'PUN'],
'met_type': [
{'type': 'mrw/met', 'word_indices': [5]}
],
'meta': ['vocal/laugh', 'N/A', 'N/A', 'N/A', 'N/A', 'N/A', 'N/A', 'N/A', 'N/A']
}
```
### Data Fields
The instances are ordered as they appear in the corpus.
- `document_name`: a string containing the name of the document in which the sentence appears;
- `words`: words in the sentence (`""` when the word represents metadata);
- `pos_tags`: POS tags of the words, encoded using the BNC basic tagset (`"N/A"` when the word does not have an associated POS tag);
- `met_type`: metaphors in the sentence, marked by their type and word indices;
- `meta`: selected metadata tags providing additional context to the sentence. Metadata may not correspond to a specific word. In this case, the metadata is represented with an empty string (`""`) in `words` and a `"N/A"` tag in `pos_tags`.
## Dataset Creation
For detailed information on the corpus, please check out the references in the `Citation Information` section or contact the dataset authors.
## Simplifications
The raw corpus is equipped with rich metadata and encoded in the TEI XML format. The textual part is fully parsed except for the lemmas, i.e. all the sentences in the raw corpus are present in the dataset.
However, parsing the metadata fully is unnecessarily tedious, so certain simplifications were made:
- paragraph information is not preserved as the dataset is parsed at sentence level;
- manual corrections (`<corr>`) of incorrectly written words are ignored, and the original, incorrect form of the words is used instead;
- `<ptr>` and `<anchor>` tags are ignored as I cannot figure out what they represent;
- the attributes `rendition` (in `<hi>` tags) and `new` (in `<shift>` tags) are not exposed.
## Discarding metadata
The dataset contains rich metadata, which is stored in the `meta` attribute. To keep data aligned, empty words or `"N/A"`s are inserted into the other attributes. If you want to ignore the metadata and correct the metaphor type annotations, you can use code similar to the following snippet:
```python3
data = datasets.load_dataset("matejklemen/vuamc")["train"]
data = data.to_pandas()
for idx_ex in range(data.shape[0]):
curr_ex = data.iloc[idx_ex]
idx_remap = {}
for idx_word, word in enumerate(curr_ex["words"]):
if len(word) != 0:
idx_remap[idx_word] = len(idx_remap)
# Note that lists are stored as np arrays by datasets, while we are storing new data in a list!
# (unhandled for simplicity)
words, pos_tags, met_type = curr_ex[["words", "pos_tags", "met_type"]].tolist()
if len(idx_remap) != len(curr_ex["words"]):
words = list(filter(lambda _word: len(_word) > 0, curr_ex["words"]))
pos_tags = list(filter(lambda _pos: _pos != "N/A", curr_ex["pos_tags"]))
met_type = []
for met_info in curr_ex["met_type"]:
met_type.append({
"type": met_info["type"],
"word_indices": list(map(lambda _i: idx_remap[_i], met_info["word_indices"]))
})
```
## Additional Information
### Dataset Curators
Gerard Steen; et al. (please see http://hdl.handle.net/20.500.12024/2541 for the full list).
### Licensing Information
Available for non-commercial use on condition that the terms of the [BNC Licence](http://www.natcorp.ox.ac.uk/docs/licence.html) are observed and that this header is included in its entirety with any copy distributed.
### Citation Information
```
@book{steen2010method,
title={A method for linguistic metaphor identification: From MIP to MIPVU},
author={Steen, Gerard and Dorst, Lettie and Herrmann, J. and Kaal, Anna and Krennmayr, Tina and Pasma, Trijntje},
volume={14},
year={2010},
publisher={John Benjamins Publishing}
}
```
```
@inproceedings{leong-etal-2020-report,
title = "A Report on the 2020 {VUA} and {TOEFL} Metaphor Detection Shared Task",
author = "Leong, Chee Wee (Ben) and
Beigman Klebanov, Beata and
Hamill, Chris and
Stemle, Egon and
Ubale, Rutuja and
Chen, Xianyang",
booktitle = "Proceedings of the Second Workshop on Figurative Language Processing",
year = "2020",
url = "https://aclanthology.org/2020.figlang-1.3",
doi = "10.18653/v1/2020.figlang-1.3",
pages = "18--29"
}
```
### Contributions
Thanks to [@matejklemen](https://github.com/matejklemen) for adding this dataset.
提供机构:
matejklemen
原始信息汇总
数据集概述
数据集名称: VUA Metaphor Corpus (VUAMC)
语言: 英语
数据集大小: 包含四个注册表,每个约50,000字,总计约200,000字。
数据集内容: 包含从BNC-Baby文件中选取的摘录,已标注比喻。分为学术文本、新闻文本、小说和对话四个领域。
标注信息:
- 单词被单独标记为参与多词表达(约1.5%)或被丢弃用于比喻分析(0.02%)。
- 主要类别包括与比喻相关的词(MRW)、表示比喻的词(MFlag)和不与比喻相关的词。
- 对于与比喻相关的词,区分了明确的比喻案例与边缘案例(WIDLII,When In Doubt, Leave It In)。
- 另一个比喻相关词的参数区分了直接比喻、间接比喻和隐含比喻。
任务支持:
- 比喻检测
- 比喻类型分类
数据集结构:
- 数据实例: 包含文档名称、单词、词性标签、比喻类型和元数据。
- 数据字段:
document_name: 文档名称words: 句子中的单词pos_tags: 词性标签met_type: 句子中的比喻类型及其词索引meta: 附加的元数据标签
创建信息:
- 原始语料库包含丰富的元数据,以TEI XML格式编码。
- 文本部分完全解析,除了词形变化,所有原始语料库中的句子都存在于数据集中。
- 简化了元数据的解析,忽略了某些复杂的标签和属性。
使用许可:
- 非商业用途,需遵守BNC许可证并包含此标题。
引用信息:
- 参考文献和联系信息可在
Citation Information部分找到。
搜集汇总
数据集介绍
构建方式
在隐喻识别研究领域,VUA隐喻语料库(VUAMC)的构建体现了严谨的学术规范。该数据集源自BNC-Baby语料库,专家从学术文本、新闻、小说及对话四种文体中各精选约五万词进行人工标注。标注过程严格遵循MIPVU方法论,对每个词汇进行多维度分类,包括是否属于隐喻相关词、多词表达或需排除的分析对象,并对隐喻类型进一步区分为直接、间接与隐性隐喻。原始语料以TEI XML格式存储,本版本通过解析保留了全部文本句子及核心标注,但简化了部分元数据以提升易用性。
使用方法
使用VUA隐喻语料库时,研究者可通过Hugging Face平台直接加载数据集进行隐喻检测或分类任务。数据以句子为单位组织,每个实例包含词汇、词性标签及隐喻类型标注。由于数据集保留了原始元数据,用户在处理前需注意对齐问题,可通过提供的代码片段过滤元数据条目并重新映射隐喻标注的词汇索引,以确保分析对象的准确性。该数据集适用于训练或评估自然语言处理模型在隐喻识别与分类方面的性能,其多文体构成也支持文体差异对隐喻使用影响的相关研究。
背景与挑战
背景概述
隐喻作为认知语言学与自然语言处理交叉领域的关键议题,其自动识别一直是计算语言学的核心难题。VUA隐喻语料库(VUAMC)由阿姆斯特丹自由大学Gerard Steen教授领衔的研究团队于2010年构建,基于英国国家语料库(BNC-Baby)精选学术、新闻、小说与会话四类文本,采用MIPVU方法论对隐喻表达进行系统标注。该语料库不仅区分隐喻相关词、隐喻标记词及非隐喻词,更细致划分直接隐喻、间接隐喻与隐式隐喻等类别,为隐喻计算研究提供了首个大规模、多体裁的标注资源,显著推动了隐喻检测、分类及多词表达识别等任务的发展。
当前挑战
隐喻识别任务面临多重挑战:在领域层面,隐喻的歧义性与语境依赖性使得自动区分字面义与隐喻义极为困难,尤其需处理边界案例(如WIDLII类别)及跨体裁的隐喻变异;隐喻类型(如直接、间接、隐式)的细粒度分类更依赖深层语义推理。在构建过程中,语料库源自复杂TEI XML格式,需解析丰富元数据并保持标注对齐,而原始数据中的手动修正、指针标签及段落信息丢失等问题增加了数据清洗与结构化的难度;同时,多词表达(约1.5%)与元数据(如语音特征)的整合要求设计特殊处理机制,以确保标注映射的准确性。
常用场景
经典使用场景
在计算语言学领域,隐喻识别作为自然语言理解的核心挑战之一,VUA隐喻语料库(VUAMC)为研究者提供了系统性的标注资源。该数据集精选自英国国家语料库婴儿版(BNC-Baby),涵盖学术、新闻、小说和对话四种文体,每个文体约五万词,并细致标注了隐喻相关词、多词表达及隐喻类型。其经典使用场景在于训练和评估隐喻检测模型,尤其在区分直接隐喻、间接隐喻和隐式隐喻方面,为算法提供了丰富的语言学特征和上下文实例,推动了隐喻计算模型的精细化发展。
解决学术问题
VUA隐喻语料库有效解决了隐喻计算研究中长期存在的标注标准不统一和数据稀缺问题。通过引入MIPVU方法论,该数据集提供了清晰的隐喻界定框架,包括隐喻相关词、隐喻标志及边界案例的标注,使得研究者能够系统探究隐喻在跨文体中的分布规律。这不仅促进了隐喻自动检测精度的提升,还为隐喻类型学、认知语言学与计算模型的交叉研究奠定了数据基础,深化了对人类隐喻认知机制的理解。
实际应用
在实际应用中,VUA隐喻语料库为自然语言处理系统赋予了更深刻的语义解析能力。基于该数据集训练的模型可应用于教育技术领域,如辅助第二语言学习者理解英语文本中的隐喻表达;在内容分析中,帮助自动识别新闻或学术文献中的修辞手法,提升信息检索的准确性;此外,在对话系统开发中,隐喻检测能增强机器对用户隐含意图的捕捉,推动人机交互的自然化与智能化发展。
数据集最近研究
最新研究方向
在隐喻计算语言学领域,VUA隐喻语料库(VUAMC)作为关键资源,正推动着隐喻识别与分类的前沿探索。当前研究聚焦于利用深度学习模型,如Transformer架构,提升隐喻检测的精确度与泛化能力,尤其在多词表达检测和隐喻类型细分(如直接隐喻与间接隐喻)方面取得进展。近年来,相关共享任务(如2020年VUA和TOEFL隐喻检测任务)促进了跨模型比较,热点事件包括将隐喻分析整合入自然语言理解系统,以增强机器对复杂语义的解析。这一趋势不仅深化了语言认知计算的理论基础,也为教育技术、情感分析等应用场景提供了语义层面的支持,凸显了隐喻研究在人工智能理解人类语言深层含义中的核心意义。
以上内容由遇见数据集搜集并总结生成


