cliniq-dataset
收藏Hugging Face2026-03-28 更新2026-03-29 收录
下载链接:
https://huggingface.co/datasets/Zolisa/cliniq-dataset
下载链接
链接失效反馈官方服务:
资源简介:
ClinIQ 是一个面向资源有限诊所的社区健康工作者和护士的离线优先AI临床分诊助手。该项目通过三阶段的知识蒸馏流程,将1.5B参数的教师模型压缩为0.5B的学生模型,以便在普通硬件上运行。数据集用于支持临床分诊任务,包括紧急/紧急/常规分类,涵盖结核病、HIV、疟疾、孕产妇健康和儿科疾病等领域,并遵循WHO IMAI/IMCI指南。输出为结构化的JSON格式,包含鉴别诊断、行动建议和免责声明。需要注意的是,ClinIQ是一个决策支持工具,所有输出都需要由合格的医疗专业人员进行临床验证。
创建时间:
2026-03-27
搜集汇总
数据集介绍
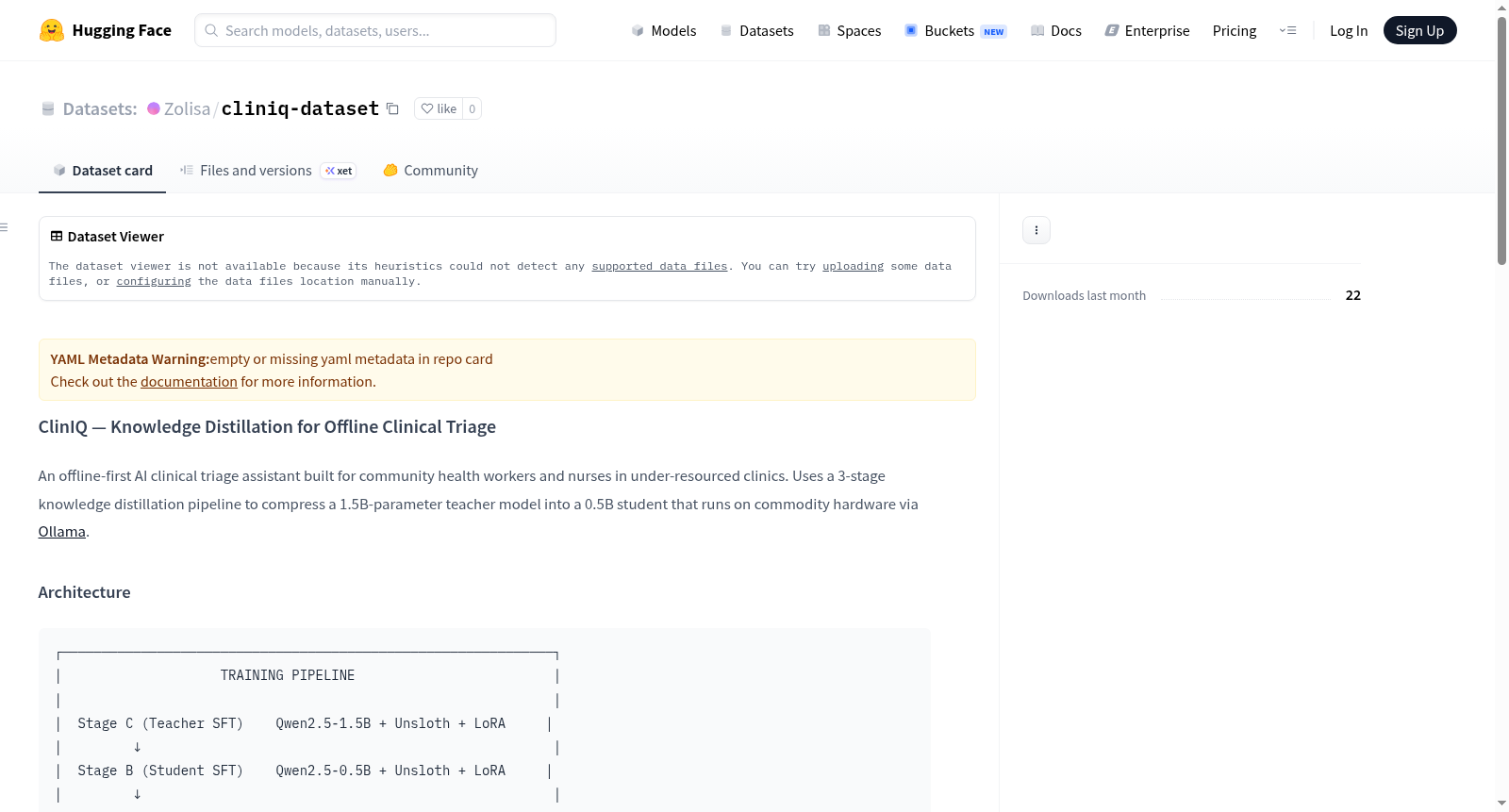
构建方式
在临床决策支持系统的构建过程中,数据集的精心设计是实现高效知识蒸馏的基础。ClinIQ数据集采用三阶段知识蒸馏流程构建:首先通过教师模型微调阶段,利用Qwen2.5-1.5B参数模型结合Unsloth与LoRA技术进行监督式微调;随后进入学生模型微调阶段,采用Qwen2.5-0.5B参数模型进行轻量化适配;最终通过KL散度蒸馏阶段,在原始PyTorch框架下实现对数概率分布的迁移学习,形成完整的模型压缩管道。
特点
该数据集的核心特征体现在其专业领域覆盖与结构化输出设计上。数据集严格遵循世界卫生组织IMAI/IMCI临床指南,涵盖结核病、艾滋病、疟疾、孕产妇保健及儿科疾病等多个关键公共卫生领域。其输出采用标准化JSON格式,包含紧急程度分级、鉴别诊断、临床处置建议及免责声明等结构化字段,确保临床决策支持的规范性与可解释性。数据集特别注重资源受限场景的适配性,最终模型可在4GB内存设备离线运行。
使用方法
基于该数据集的临床分诊系统部署遵循模块化实施路径。研究人员需通过Git克隆代码库并配置环境变量,依次执行数据准备脚本与三阶段训练流程。模型部署采用Ollama框架进行Q4量化处理,配合FastAPI构建临床服务端点,形成完整的本地化部署方案。使用过程中需注意系统严格遵循临床辅助工具定位,所有输出必须经专业医疗人员审核确认,确保符合医疗伦理规范与患者安全要求。
背景与挑战
背景概述
ClinIQ数据集作为离线临床分诊辅助系统的核心组成部分,其构建源于对资源匮乏地区医疗支持需求的深刻洞察。该数据集由研究团队于近年开发,旨在通过知识蒸馏技术,将大规模语言模型压缩为可在低配置硬件上运行的轻量级模型,以服务于社区卫生工作者和护士。其核心研究问题聚焦于如何在有限计算资源下,实现基于世界卫生组织IMAI/IMCI指南的紧急、急症和常规分类,覆盖结核病、艾滋病、疟疾、孕产妇健康和儿科疾病等多个临床领域。这一工作不仅推动了边缘计算在医疗人工智能中的应用,也为全球健康公平性提供了技术解决方案。
当前挑战
ClinIQ数据集所应对的领域挑战在于,临床分诊任务需在高度不确定性和时间敏感性环境下,实现准确且可解释的决策支持,同时严格遵循医学指南并规避误诊风险。构建过程中的挑战则体现为多阶段知识蒸馏管道的设计复杂性,包括从1.5B参数教师模型到0.5B学生模型的有效知识迁移,确保模型在仅4GB内存的商用硬件上离线运行,以及保持对多样化疾病领域和结构化JSON输出的高保真度。此外,数据需与临床实践紧密对齐,并在模型压缩过程中平衡性能损耗与推理效率。
常用场景
经典使用场景
在医疗资源匮乏的临床环境中,CliniQ数据集为构建离线优先的临床分诊助手提供了核心支持。该数据集通过知识蒸馏技术,将大型教师模型压缩为轻量级学生模型,使其能够在低配置硬件上运行。经典使用场景包括社区健康工作者和护士利用本地部署的AI系统,对结核病、艾滋病、疟疾等常见疾病进行紧急、紧急或常规分类,辅助快速评估患者优先级,优化临床工作流程。
解决学术问题
CliniQ数据集致力于解决资源受限场景下大型医疗AI模型部署的学术挑战。它通过三阶段知识蒸馏管道,将1.5B参数的教师模型压缩至0.5B学生模型,显著降低了计算和存储需求。这一方法有效应对了模型效率与性能平衡、离线临床决策支持系统开发,以及遵循WHO IMAI/IMCI指南的标准化医疗分类等关键研究问题,推动了边缘计算在医疗领域的应用。
衍生相关工作
围绕CliniQ数据集,衍生出多项经典研究工作,主要集中在高效知识蒸馏框架与轻量化医疗AI部署领域。例如,基于Unsloth与LoRA的教师-学生模型微调方法,以及使用原始PyTorch实现KL散度蒸馏的技术方案。这些工作进一步探索了事件驱动的AWS云架构集成、低资源环境下的模型量化策略,并为开发符合临床指南的可扩展分诊系统提供了重要参考。
以上内容由遇见数据集搜集并总结生成


