markdown-table-qa
收藏Hugging Face2026-04-02 更新2026-04-03 收录
下载链接:
https://huggingface.co/datasets/cetusian/markdown-table-qa
下载链接
链接失效反馈官方服务:
资源简介:
Markdown Table QA 数据集是一个包含 11,000 个(指令、输入、响应)三元组的合成数据集(10,000 训练 + 1,000 验证),旨在训练和评估语言模型在结构化表格理解和计算推理方面的能力。每个样本包含一个 Markdown 表格、一个自然语言问题和一个包含推理过程的对话式回答。数据集涵盖 15 个真实世界领域和 12 种问题类型,包括比较、复合、过滤计数、过滤求和、查找、最大行、均值、最小行、百分比、前 3 排名、求和和摘要等。计算类型的问题(如求和、均值等)具有通过 pandas 计算的数学验证答案。数据集通过 vLLM 和 OpenAI gpt-oss-120b 构建的管道生成,经过去重、答案基础检查和类型平衡等质量控制。该数据集是为探索监督微调(SFT)与强化学习(RL)在表格理解中的应用而创建的,适用于自然语言处理和机器学习研究。
创建时间:
2026-03-31
原始信息汇总
Markdown Table QA 数据集概述
数据集基本信息
- 数据集名称: Markdown Table QA Dataset
- 托管地址: https://huggingface.co/datasets/cetusian/markdown-table-qa
- 数据规模: 11,000 个样本
- 数据分割:
- 训练集: 10,000 个样本
- 验证集: 1,000 个样本
- 总大小: 20,646,922 字节
- 下载大小: 7,825,977 字节
数据结构与特征
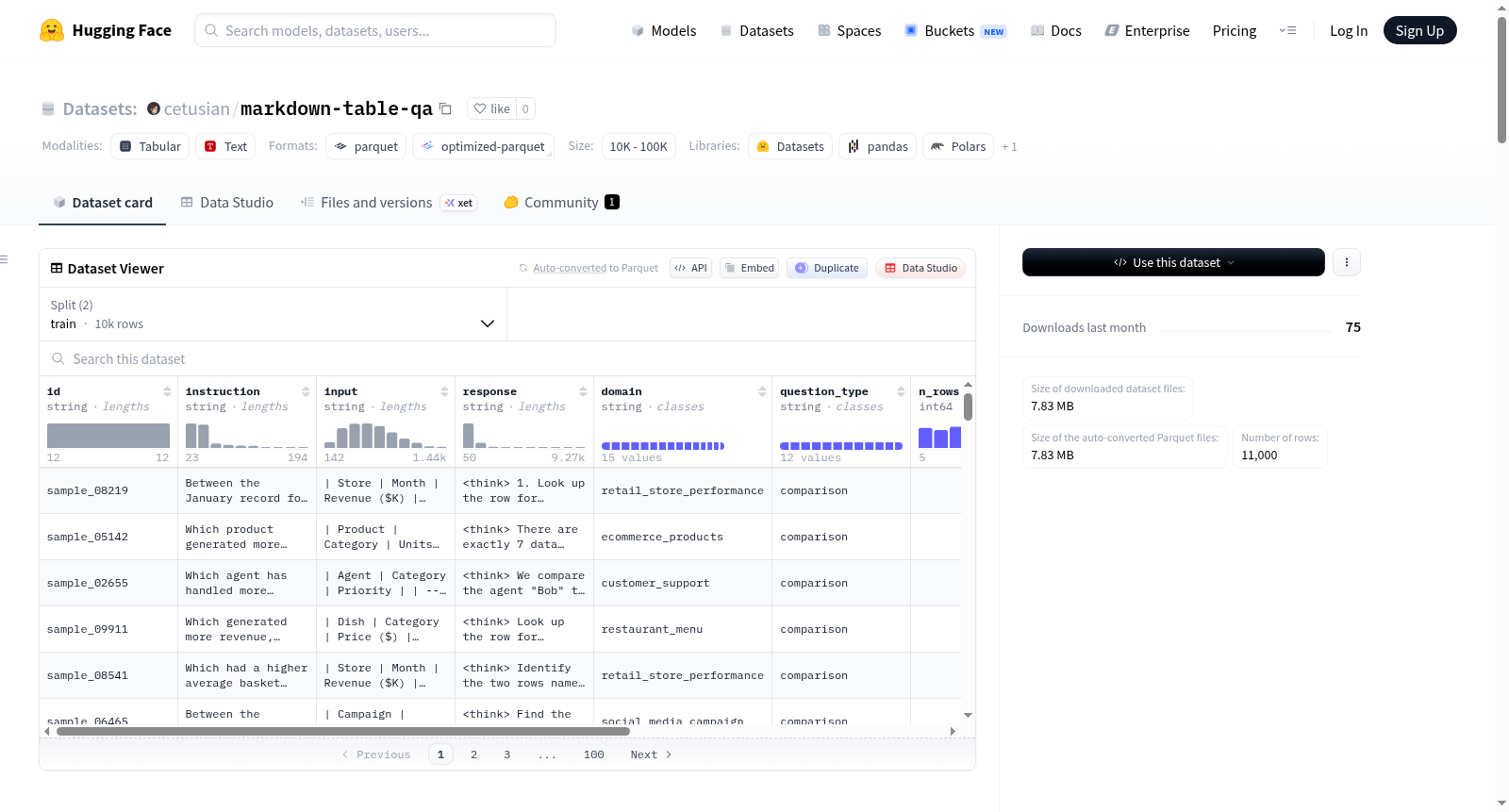
数据集包含以下字段:
id: 样本标识符(字符串类型)instruction: 关于表格的自然语言问题(字符串类型)input: Markdown 格式的表格(字符串类型)response: 包含<think>...</think>推理链的对话式答案(字符串类型)domain: 表格所属领域(字符串类型)question_type: 问题类型(字符串类型)n_rows: 表格行数(整数类型)n_cols: 表格列数(整数类型)numeric_cols: 数值列列表(字符串列表)categorical_cols: 分类列列表(字符串列表)
数据内容与示例
每个样本包含一个 Markdown 表格、一个自然语言问题和一个对话式答案。答案中包含显式的推理步骤。
示例:
- instruction: How many appointments were on Wednesday and how many were no-shows?
- input: 一个包含 Patient, Doctor, Day, Status, Duration (min) 列的 Markdown 表格。
- response:
<think> Looking at rows where Day = Wednesday: Alice Martin (Attended) and Bob Chen (No-show). That is 2 appointments, 1 no-show. </think> There were 2 appointments on Wednesday. One was attended and one was a no-show — Bob Chen with Dr. Patel.
领域覆盖
数据集涵盖 15 个现实世界领域:
- Healthcare appointments
- Social media campaigns
- Employee HR & performance
- E-commerce products
- Student grades
- Project tracking
- Retail store performance
- Financial transactions
- Sports team stats
- Inventory management
- Customer support tickets
- Marketing leads
- Event registrations
- Restaurant menus
- Flight operations
问题类型分布
数据集包含 12 种问题类型,具体分布如下:
| 类型 | 训练集样本数 | 验证集样本数 | 示例 |
|---|---|---|---|
comparison |
859 | 84 | "Which team had the better win rate, Lions or Eagles?" |
compound |
858 | 84 | "How many no-shows on Wednesday and which doctor had the most?" |
filtered_count |
859 | 83 | "How many campaigns ran on Instagram?" |
filtered_sum |
859 | 83 | "What is the total sales for the North region?" |
lookup |
858 | 84 | "What was Alices performance score?" |
max_row |
835 | 83 | "Which product had the highest unit price?" |
mean |
848 | 83 | "What is the average delivery time?" |
min_row |
770 | 83 | "Which employee had the fewest absences?" |
percentage |
851 | 83 | "What percentage of orders were returned?" |
rank_top3 |
800 | 83 | "What are the top 3 agents by CSAT score?" |
sum |
745 | 83 | "What is the total prep time across all menu items?" |
summarization |
858 | 84 | "Summarize the data in this table." |
| 总计 | 10,000 | 1,000 |
计算类型问题(sum, mean, filtered_sum, filtered_count, max_row, min_row, percentage, rank_top3)的答案在生成推理链前已使用 pandas 进行数学验证。
生成方法
- 表格生成: 使用随机模式、行数(5–20)和列数(3–6)合成生成。
- 描述性问答生成: 使用 120B 模型生成问题及对话式答案(涵盖 comparison, lookup, compound, summarization, filtered_count 类型)。
- 计算性问答生成: 使用 pandas 计算已验证答案;120B 模型仅生成
<think>推理链(涵盖 sum, mean, max_row, min_row, percentage, rank_top3, filtered_sum 类型)。 - 质量保证: 应用了去重、答案基础检查及类型平衡。
使用方式
python from datasets import load_dataset ds = load_dataset("cetusian/markdown-table-qa")
背景与目的
该数据集创建于 Open Source Hack Day: Surogate / Invergent AI 黑客松(2025年4月4日),旨在比较监督微调(SFT)与强化学习(GRPO)在微调小型模型(如 Qwen3-0.6B / Qwen2.5-0.8B)处理 Markdown 表格理解任务上的效果,并衡量强化学习相较于监督基线的提升程度。
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,结构化数据理解是提升模型推理能力的关键环节。Markdown Table QA数据集通过合成生成的方式构建,其核心流程依托于vLLM框架与OpenAI gpt-oss-120b模型,在四块GPU上并行生成。表格部分采用随机化模式,涵盖5至20行、3至6列的不同规模,确保结构多样性。问题与答案的生成分为描述性与计算性两类:描述性问题由大模型直接生成自然语言问答对;计算性问题则先通过pandas库进行数学验证,再由模型编写包含<think>标签的推理轨迹,最后经过去重、答案对齐与类型平衡等质量控制步骤,形成包含一万一千个样本的高质量数据集。
特点
该数据集在表格问答任务中展现出鲜明的专业特性。其覆盖十五个现实世界领域,从医疗预约到金融交易,表格结构丰富多变,有效模拟了实际应用场景。数据集精心定义了十二种问题类型,包括比较、复合查询、过滤统计及汇总等,全面考察模型的理解与计算能力。尤为突出的是,计算类问题均附有经过pandas验证的精确答案,并配有逐步推理痕迹,为模型训练提供了可解释的学习范例。这种设计不仅增强了数据的可靠性,也为评估模型的逻辑推理与数值计算性能提供了扎实基础。
使用方法
对于致力于提升表格理解能力的研究者与开发者,该数据集提供了便捷的应用途径。用户可通过Hugging Face的datasets库直接加载,并按照指令微调的格式进行配置,指定instruction、input和response对应字段即可投入训练。数据集明确区分训练集与验证集,支持监督式微调流程,旨在比较不同训练策略(如SFT与强化学习)在小型模型上的效果。使用者可依据具体的研究目标,利用其丰富的领域与问题类型,系统性地评估和优化模型在结构化数据上的问答与推理性能。
背景与挑战
背景概述
在自然语言处理领域,表格数据理解与问答任务长期面临结构化信息解析与自然语言交互融合的挑战。Markdown Table QA数据集于2025年4月由Invergent AI团队在ROSEdu组织的开源黑客松活动中创建,旨在为语言模型提供高质量的监督微调与强化学习对比基准。该数据集聚焦于表格的结构化语义理解与计算推理能力评估,覆盖医疗、金融、电商等15个现实领域,通过合成生成与数学验证相结合的方式,构建了包含11,000个指令-响应对的语料库,推动了面向复杂表格的自动化问答系统的研究进展。
当前挑战
该数据集致力于解决表格问答任务中结构化数据解析与自然语言推理深度融合的核心挑战,具体包括模型需同时处理离散的分类查询与连续的数值计算,并生成可解释的推理轨迹。在构建过程中,挑战主要体现在确保合成表格的语义多样性与结构真实性,以及平衡12种问题类型的分布。此外,生成流程需协调大规模语言模型与精确的pandas计算引擎,以保障数学类问题的答案正确性,并通过去重与质量检查机制维持数据集的整体一致性。
常用场景
经典使用场景
在自然语言处理领域,表格理解与问答任务对模型的结构化推理能力提出挑战。Markdown Table QA数据集通过合成方式构建了涵盖15个现实领域、12种问题类型的指令-响应对,为训练和评估语言模型提供了标准化基准。该数据集最经典的使用场景是监督式微调,研究人员利用其丰富的表格结构和多样化问题,训练模型从Markdown格式表格中提取信息、执行计算并生成自然语言答案,从而提升模型在结构化数据上的理解和推理性能。
解决学术问题
该数据集有效解决了表格问答研究中数据稀缺与多样性不足的学术难题。通过提供大规模、高质量且数学验证的合成数据,它支持模型学习跨领域的表格语义解析、复杂查询处理及数值计算。其意义在于推动了语言模型在结构化数据理解方面的进展,为比较不同训练方法(如监督微调与强化学习)提供了实验基础,促进了表格推理任务的标准化评估,对提升模型在实际应用中的可靠性和准确性具有重要影响。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作。例如,在Surogate平台举办的研讨会上,研究人员利用它系统比较了监督微调与基于GRPO的强化学习方法在小型模型上的性能差异。这些工作探索了如何优化模型对表格的理解和推理能力,并推动了AgentOps平台中可靠AI代理的开发。相关实验不仅验证了数据集的实用性,也为表格问答领域的模型训练策略提供了新的见解和基准。
以上内容由遇见数据集搜集并总结生成


