bigbio/sciq
收藏Hugging Face2022-12-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/bigbio/sciq
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- en
bigbio_language:
- English
license: cc-by-nc-3.0
multilinguality: monolingual
bigbio_license_shortname: CC_BY_NC_3p0
pretty_name: SciQ
homepage: https://allenai.org/data/sciq
bigbio_pubmed: False
bigbio_public: True
bigbio_tasks:
- QUESTION_ANSWERING
---
# Dataset Card for SciQ
## Dataset Description
- **Homepage:** https://allenai.org/data/sciq
- **Pubmed:** False
- **Public:** True
- **Tasks:** QA
The SciQ dataset contains 13,679 crowdsourced science exam questions about Physics, Chemistry and Biology, among others. The questions are in multiple-choice format with 4 answer options each. For most questions, an additional paragraph with supporting evidence for the correct answer is provided.
## Citation Information
```
@inproceedings{welbl-etal-2017-crowdsourcing,
title = "Crowdsourcing Multiple Choice Science Questions",
author = "Welbl, Johannes and
Liu, Nelson F. and
Gardner, Matt",
booktitle = "Proceedings of the 3rd Workshop on Noisy User-generated Text",
month = sep,
year = "2017",
address = "Copenhagen, Denmark",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/W17-4413",
doi = "10.18653/v1/W17-4413",
pages = "94--106",
}
```
---
语言:
- 英语
bigbio_language:
- 英语
许可证: CC BY-NC 3.0
多语言属性: 单语言
bigbio_license_shortname: CC_BY_NC_3p0
pretty_name: SciQ
homepage: https://allenai.org/data/sciq
bigbio_pubmed: 否
bigbio_public: 是
bigbio_tasks:
- 问答(QUESTION_ANSWERING)
---
# SciQ 数据集卡片
## 数据集概况
- **数据集主页:** https://allenai.org/data/sciq
- **PubMed关联:** 否
- **公开状态:** 是
- **任务类型:** 问答(QA)
SciQ数据集共包含13679条众包生成的理科考试题目,涵盖物理学、化学、生物学等多个学科。所有题目均采用四选项单项选择题格式,绝大多数题目附带了指向正确答案的佐证段落。
## 引用信息
@inproceedings{welbl-etal-2017-crowdsourcing,
title = "众包多项选择理科试题",
author = "Welbl, Johannes and
Liu, Nelson F. and
Gardner, Matt",
booktitle = "第三届噪声用户生成文本研讨会论文集",
month = "9月",
year = "2017",
address = "丹麦哥本哈根",
publisher = "计算语言学协会",
url = "https://aclanthology.org/W17-4413",
doi = "10.18653/v1/W17-4413",
pages = "94--106",
}
提供机构:
bigbio
原始信息汇总
数据集概述:SciQ
基本信息
- 名称: SciQ
- 语言: 英语
- 许可证: CC BY NC 3.0
- 多语言性: 单语种
- 是否公开: 是
- 任务类型: 问答(QA)
数据集描述
- 包含内容: 13,679个关于物理、化学和生物等科学考试的多项选择题。
- 问题格式: 每个问题包含4个答案选项,大多数问题附带一段支持正确答案的证据段落。
引用信息
@inproceedings{welbl-etal-2017-crowdsourcing, title = "Crowdsourcing Multiple Choice Science Questions", author = "Welbl, Johannes and Liu, Nelson F. and Gardner, Matt", booktitle = "Proceedings of the 3rd Workshop on Noisy User-generated Text", month = sep, year = "2017", address = "Copenhagen, Denmark", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/W17-4413", doi = "10.18653/v1/W17-4413", pages = "94--106", }
搜集汇总
数据集介绍
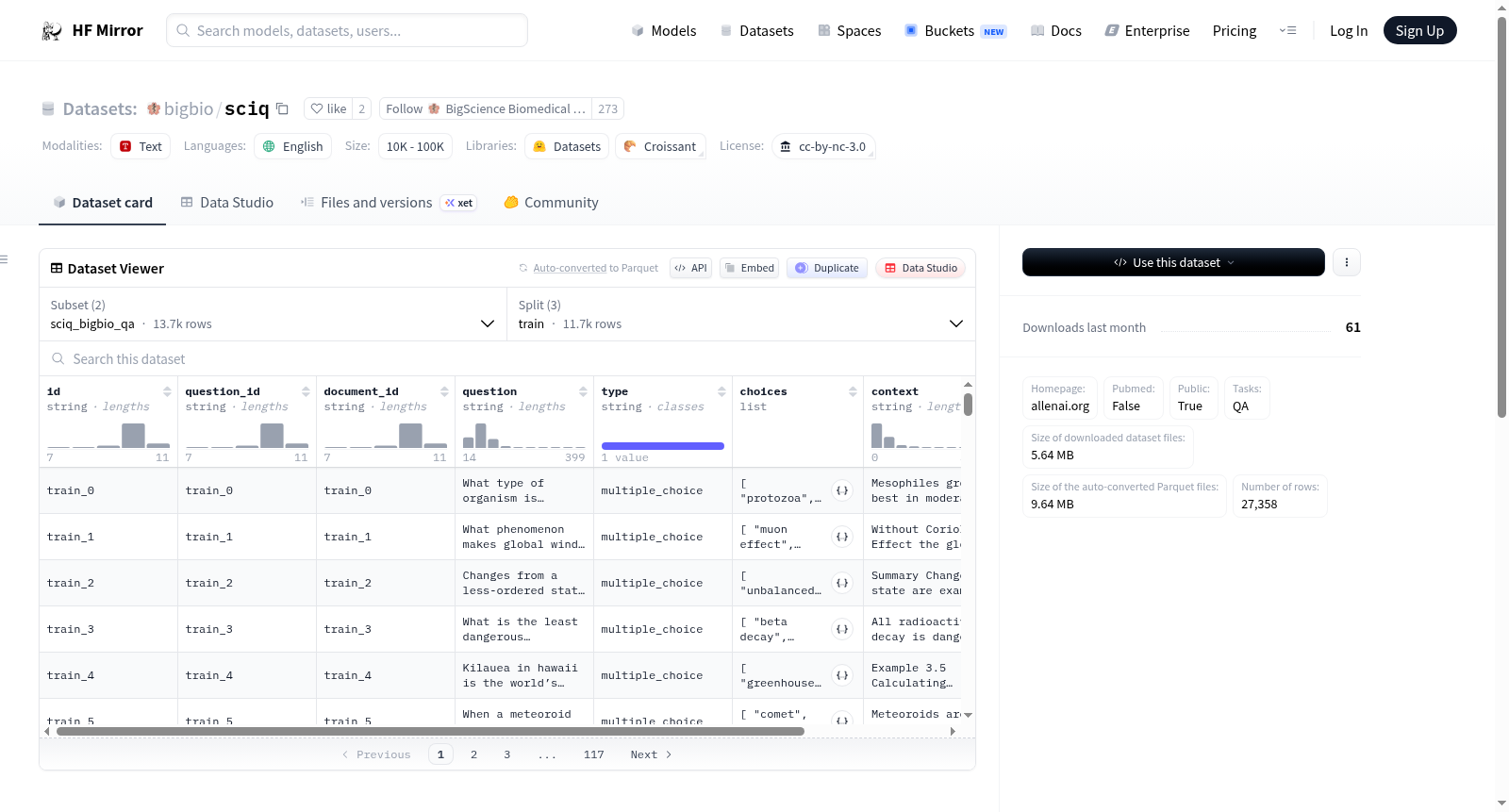
构建方式
在科学教育评估领域,SciQ数据集的构建体现了众包策略的巧妙应用。该数据集通过精心设计的众包流程,收集了涵盖物理学、化学及生物学等核心科学学科的13,679道考试题目。每道题目均以四选一的多项选择题形式呈现,确保了评估结构的标准化。尤为重要的是,大部分题目还附带了提供正确答案支持证据的补充段落,这为模型理解科学推理过程提供了宝贵的上下文信息。
特点
SciQ数据集的核心特点在于其专注于科学领域的问答任务,并提供了丰富的辅助信息。数据集内容严格限定于科学学科,题目设计模拟了真实的教育评估场景。其提供的支持性证据段落构成了显著特色,超越了单纯的答案选择,为探究模型如何依据文本证据进行推理开辟了路径。这种结构使得该数据集不仅适用于答案预测,更适用于可解释性科学问答的研究。
使用方法
对于研究人员而言,SciQ数据集主要用于训练和评估科学问答模型。典型的使用方法涉及将问题及其对应的选项作为模型输入,目标是预测正确选项。更深入的用法则整合支持证据段落,用以探究模型在检索或理解相关科学知识后的推理能力。该数据集适用于监督学习框架,常作为基准测试的一部分,用以衡量模型在特定领域知识理解和应用方面的性能。
背景与挑战
背景概述
在自然语言处理领域,科学问答任务对于评估模型理解复杂科学概念的能力至关重要。SciQ数据集由Allen人工智能研究所的研究人员Johannes Welbl、Nelson F. Liu和Matt Gardner于2017年创建,旨在通过众包方式收集涵盖物理、化学和生物学等多学科的科学考试题目。该数据集包含13,679道多项选择题,每道题配有四个选项,且多数题目附有支持正确答案的证据段落,其核心研究问题聚焦于提升机器在科学知识推理与问答方面的性能,对推动教育技术、智能辅导系统及相关自然语言处理应用的发展产生了显著影响。
当前挑战
SciQ数据集所针对的科学问答领域面临多重挑战:模型需准确理解跨学科的专业术语和复杂概念,并基于有限上下文进行逻辑推理,这要求处理语义歧义和知识整合问题。在构建过程中,挑战主要源于众包质量控制,确保题目的科学准确性和难度一致性,同时平衡不同学科领域的覆盖范围,以及为每道题提供可靠证据段落的数据标注工作,这些因素共同增加了数据集构建的复杂性和资源需求。
常用场景
经典使用场景
在自然语言处理领域,SciQ数据集以其涵盖物理、化学和生物等多学科的科学考试问题,成为评估和训练问答系统的经典资源。该数据集包含超过一万三千道多项选择题,每道题均配有四个选项,并附有支持正确答案的辅助证据段落,为模型提供了丰富的上下文信息。研究者通常利用SciQ来测试机器在科学知识理解方面的能力,尤其是在需要推理和证据支持的复杂场景中,它帮助验证模型能否从文本中提取关键信息并做出准确判断。
实际应用
在实际应用中,SciQ数据集被广泛用于构建智能教育工具和在线学习平台。例如,它可以集成到自适应学习系统中,根据学生的答题表现提供个性化的科学问题练习,增强学习效果。此外,该数据集还支持开发虚拟助教或聊天机器人,帮助用户快速获取科学解释,降低知识获取门槛。在教育资源不均的地区,这类技术能辅助教师进行教学,提升科学教育的普及性和质量,体现了人工智能技术在社会公益领域的潜力。
衍生相关工作
基于SciQ数据集,学术界衍生了一系列经典研究工作,主要集中在改进问答模型和知识图谱构建方面。例如,研究者利用SciQ训练了基于Transformer的预训练模型,如BERT和T5的变体,以提升科学问题回答的准确性。这些工作不仅推动了模型在多项选择题任务上的性能突破,还促进了证据检索和推理机制的发展。后续研究进一步将SciQ与其他科学数据集结合,扩展了跨领域知识表示的学习,为更复杂的科学推理任务奠定了基础。
以上内容由遇见数据集搜集并总结生成


