CodeDocsNER
收藏Hugging Face2026-04-10 更新2026-04-11 收录
下载链接:
https://huggingface.co/datasets/exa-ai/CodeDocsNER
下载链接
链接失效反馈官方服务:
资源简介:
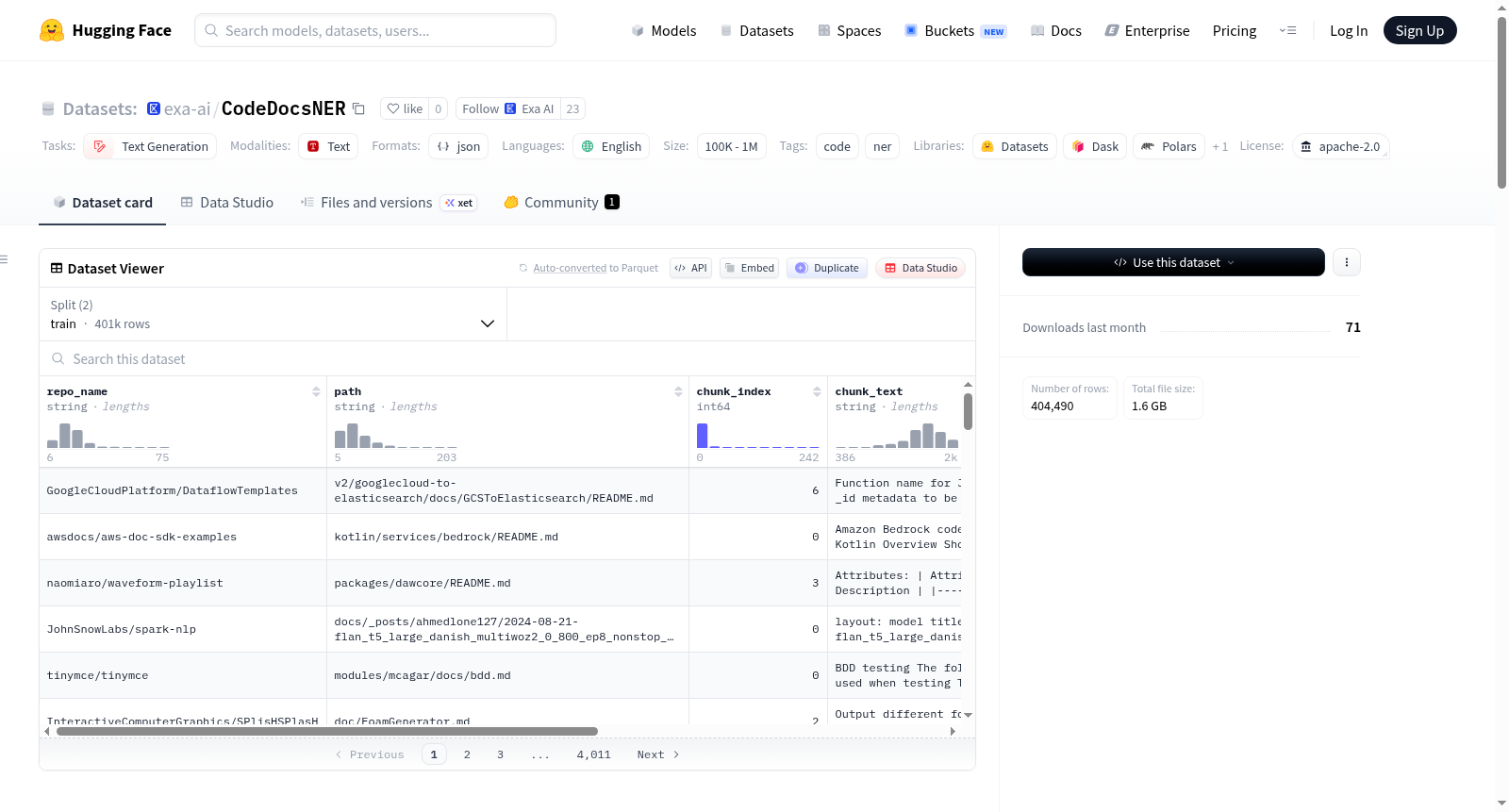
CodeDocsNER 是一个大规模代码文档命名实体识别(NER)数据集,包含来自 4,534 个采用 MIT 和 Apache-2.0 许可的 GitHub 仓库的 206,408 个 Markdown 文件。数据集中的每个文档被分割为 256 个 token 的片段,并通过两阶段标注流程进行标注:第一阶段(OpenNER)使用 DeepSeek v3.2 自由提取实体,第二阶段(Candidate fill)使用 spaCy 提取名词短语和命名实体,并将第一阶段遗漏的候选实体送回 DeepSeek 进行分类。数据集包含 102,153 种独特的实体类型,适合训练如 GLiNER 等能够泛化到未见实体类型的模型。数据集结构包括 NER 标注的片段(annotations/)、原始 Markdown 文件(docs/)和许可元数据(attribution/)。标注统计显示,数据集包含 502,069 个标注片段、1,730 万个实体提及和 540 万个独特实体文本。数据处理流程包括源选择、内容获取、Markdown 剥离、分块、过滤、标注和规范化。数据集仅包含 MIT 和 Apache-2.0 许可的仓库,且排除了特定路径和文件类型。
创建时间:
2026-04-09
原始信息汇总
CodeDocsNER 数据集概述
数据集基本信息
- 名称: CodeDocsNER
- 许可证: Apache-2.0
- 任务类别: 文本生成
- 主要语言: 英语
- 标签: 代码、命名实体识别
- 数据规模: 10万到100万条之间
数据集描述
CodeDocsNER 是一个大规模命名实体识别数据集,其构建基于 4,835 个采用宽松许可证的 GitHub 仓库 中的 206,382 个 Markdown 文档文件,包含约 1,700 万个命名实体,涵盖 25,547 个实体类型。
- 数据来源: 仓库通过 GH Archive 的 star 数据识别,筛选出在 2026 年获得至少 5 颗星的仓库。文件内容直接从 GitHub API 获取。
- 标注方法: 采用 DeepSeek v3.2 和 spaCy 的两阶段方法进行实体标注。
- 构建工具: 使用 github-markdown-exporter 构建。
- 数据新鲜度: 此快照于 2026-04-07 直接从 GitHub 获取。
数据集结构
数据集包含三个主要部分:
1. annotations/ (训练/测试集)
JSONL 格式文件,包含经过筛选和标准化的标注文本块。
- 训练集: 401,020 个文本块。
- 测试集: 3,470 个文本块。
- 字段说明:
repo_name: 源仓库名称 (所有者/仓库名)。path: 文件在仓库内的路径。chunk_index: 文件内文本块的索引 (从0开始)。chunk_text: 处理后的纯文本块内容。entities: 命名实体列表,格式为[{"text": "...", "label": "..."}, ...]。
2. docs/ (原始 Markdown 内容)
Parquet 格式文件,包含原始文档内容。
- 字段说明:
repo_name: 仓库名称,格式为所有者/仓库名。path: 文件在仓库内的路径 (例如docs/guide.md)。license: 许可证类型 (mit或apache-2.0)。size: 文件大小 (字节)。content: 完整的 Markdown 文本。
3. attribution/ (许可证元数据)
Parquet 格式文件,包含许可和版权信息。
- 覆盖范围: 在 4,835 个仓库中,包含 4,431 个已发现 LICENSE 文件的仓库的元数据。
- 字段说明:
repo_name: 仓库名称,格式为所有者/仓库名。license_type: 许可证类型 (MIT或Apache-2.0)。copyright_line: 提取的版权声明。has_notice_file: 仓库是否包含 NOTICE 文件。license_text: 完整的 LICENSE 文件内容。notice_text: 完整的 NOTICE 文件内容 (如果有)。
数据筛选标准
源数据筛选
- 许可证: 仅限 MIT 和 Apache-2.0 许可证的仓库。
- 星标: 在 2026 年至少获得 5 颗星 (使用 GH Archive 事件数据)。
- 文件类型: 仅限 Markdown 文件 (
.md)。 - 文件大小: 介于 200 字节到 500 KB 之间 (排除空模板和生成的文件)。
- 排除路径: 排除
vendor/、node_modules/、.github/目录以及符号链接。
文本块筛选
- 最大长度: 丢弃长度超过 2,000 个字符的文本块 (标注前)。
- 最大实体数: 丢弃实体总数超过 100 个的文本块 (标注后)。
关键统计信息
| 指标 | 数值 |
|---|---|
| 仓库数量 | 4,835 |
| 文档数量 | 206,382 |
| 标注文本块 (训练集) | 401,020 |
| 标注文本块 (测试集) | 3,470 |
| 实体类型 (标准化后) | 25,547 |
| 实体总数 (筛选前) | 约 1,700 万 |
| 标注成本 | 590 美元 (通过 OpenRouter 使用 DeepSeek v3.2) |
许可与归属
- 数据集许可证: 本数据集基于 Apache-2.0 许可证发布。
- 源文档许可证: 源文档保留其原始许可证 (MIT 或 Apache-2.0),具体信息见每份文档的元数据。
- 归属信息: 每个源文档的原始许可证、版权声明和 NOTICE 文件内容在
attribution/文件中提供。Apache 2.0 声明的汇总信息见NOTICES文件。
搜集汇总
数据集介绍
构建方式
在软件工程与自然语言处理交叉领域,CodeDocsNER数据集的构建体现了大规模自动化标注的前沿实践。该数据集源自4835个采用MIT或Apache-2.0许可的GitHub仓库,通过GH Archive的星标数据筛选出2026年至少获得5颗星的项目,并从中提取了206,382个Markdown文档文件。实体标注采用两阶段流程:首先利用DeepSeek v3.2模型进行初步标注,再通过spaCy工具进行精细化处理与标准化,最终生成包含约1700万个命名实体、覆盖25,547种实体类型的标注结果。数据采集过程严格遵循文件大小与路径过滤规则,确保原始文档的质量与合规性。
使用方法
研究者可通过HuggingFace平台直接加载该数据集,其标准化的JSONL格式便于集成至主流自然语言处理框架。训练集包含401,020个标注块,测试集含3,470个标注块,适用于监督学习模型的训练与评估。使用时应优先查阅attribution目录中的许可元数据,确保具体文档的合规使用。对于模型开发,建议结合原始Markdown文档的上下文信息,以提升对技术实体语境的理解。该数据集特别适合用于训练代码文档领域的专用命名实体识别模型,或作为预训练语料增强模型对技术文本的语义表征能力。
背景与挑战
背景概述
在自然语言处理领域,命名实体识别(NER)作为信息抽取的核心任务,长期以来依赖于新闻、生物医学等传统文本领域的数据集。随着开源软件生态的蓬勃发展,代码文档中蕴含的丰富技术实体(如API名称、编程语言术语、库函数等)为NER研究开辟了新的疆域。CodeDocsNER数据集应运而生,由研究团队于2026年构建,其基于GH Archive的星标数据,从4,835个采用MIT或Apache-2.0许可的GitHub仓库中,系统采集了206,382份Markdown文档文件。该数据集的核心研究问题在于,如何从大规模、非结构化的技术文档中,精准识别并分类海量的、领域特定的命名实体,从而为代码智能、文档自动化等应用提供高质量的标注数据。它的创建标志着NER研究从通用领域向高度专业化技术文本的深度迁移,对提升编程辅助工具的理解能力具有显著影响力。
当前挑战
CodeDocsNER数据集旨在解决技术文档命名实体识别这一特定领域问题,其首要挑战在于技术实体的极端多样性与动态演化性。代码文档中的实体类型远超传统NER任务,涵盖数以万计的项目特定术语、版本号及API标识符,且随技术迭代不断涌现新词汇,这对模型的泛化与更新能力构成严峻考验。在数据集构建过程中,研究者面临多重工程挑战:需从海量GitHub仓库中依据许可协议与活跃度进行高效筛选与合规性处理;针对Markdown文档的半结构化特性,设计合理的文本分块策略以平衡上下文信息与处理效率;此外,采用DeepSeek模型与spaCy工具进行两阶段自动化标注,虽控制了成本,但如何确保跨大量项目与实体类型标注的一致性与准确性,并有效过滤噪声数据,是构建高质量大规模数据集的核心难题。
常用场景
经典使用场景
在软件工程与自然语言处理交叉领域,CodeDocsNER数据集为命名实体识别任务提供了丰富的标注资源。其经典使用场景聚焦于从大规模开源项目的文档中自动抽取技术实体,如API名称、编程语言术语、库函数或框架组件。研究者利用该数据集训练和评估模型,以识别和分类代码文档中频繁出现的专业术语,从而支持自动化文档分析工具的开发。
解决学术问题
该数据集有效解决了代码文档中实体识别缺乏高质量标注数据的学术难题。通过提供超过25,000个实体类型的标注,它支持细粒度实体分类研究,促进了领域自适应NER模型的发展。其大规模标注数据有助于探索实体分布的稀疏性问题,并为跨项目、跨语言的实体统一识别提供了基准,推动了软件知识图谱构建与智能文档处理技术的进步。
实际应用
在实际应用中,CodeDocsNER数据集被广泛用于增强代码搜索与推荐系统的准确性。例如,集成该数据集的工具能够自动解析技术文档,提取关键实体以生成智能索引,从而提升开发者查找API文档或示例代码的效率。此外,它支持自动化文档生成与维护,帮助识别过时或缺失的实体引用,优化软件开发流程中的知识管理。
数据集最近研究
最新研究方向
在软件工程与自然语言处理交叉领域,CodeDocsNER数据集凭借其从大规模开源文档中提取的丰富命名实体,正推动代码文档智能理解的前沿探索。当前研究聚焦于利用其涵盖的25,547种实体类型,开发细粒度实体识别模型,以提升自动化文档生成、代码检索及知识图谱构建的精度。随着大语言模型在编程辅助工具中的广泛应用,该数据集为训练领域自适应NER系统提供了关键资源,助力实现更准确的API推荐与文档摘要。其基于实际GitHub项目的标注数据,亦促进了开源生态中知识挖掘与合规性分析的研究,为软件维护与智能开发环境注入新的活力。
以上内容由遇见数据集搜集并总结生成


