CodeMixBench
收藏Hugging Face2025-09-04 更新2025-09-05 收录
下载链接:
https://huggingface.co/datasets/CodeMixBench/CodeMixBench
下载链接
链接失效反馈官方服务:
资源简介:
CodeMixBench是一个多语种混合文本理解能力的评估基准,包含18种语言的8个任务。这些任务包括知识推理、数学推理、真实性评估以及语言识别、词性标注、命名实体识别、情感分析和机器翻译。数据集是合成的,涵盖了12种语言,来自六大语系:日耳曼语系、罗曼语系、汉藏语系、闪米特语系、印欧语系和达罗毗荼语系。
创建时间:
2025-09-01
原始信息汇总
CodeMixBench 数据集概述
数据集简介
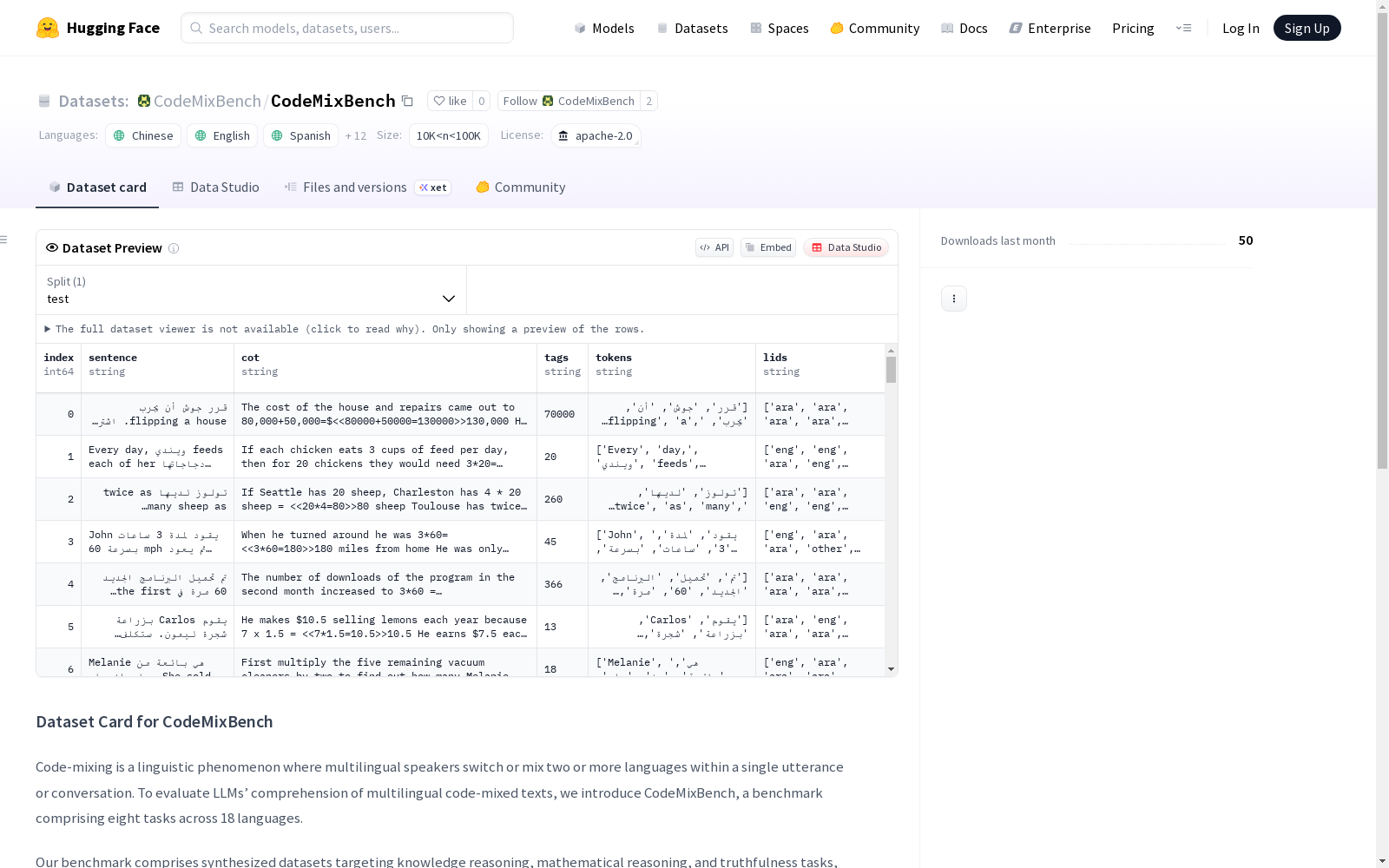
CodeMixBench 是一个评估大型语言模型(LLMs)对多语言代码混合文本理解能力的基准测试。该基准包含八个任务,涵盖 18 种语言,针对知识推理、数学推理和真实性任务,以及语言识别(LID)、词性标注(POS)、命名实体识别(NER)、情感分析(SA)和机器翻译(MT)任务。
数据集组成
任务类型
- 知识推理:基于 MMLU 测试集开发的代码混合 MMLU(CM-MMLU),包含 57 个主题的多项选择题。
- 数学推理:基于 GSM8K 测试集创建的代码混合 GSM8K(CM-GSM8K),每个问题包含逐步解决方案。
- 真实性评估:基于 TruthfulQA 测试集构建的代码混合 TruthfulQA(CM-TruthfulQA),包含 817 个多项选择题。
- 其他任务:LID、POS、NER、SA 和 MT 任务。
语言覆盖
涵盖 12 种语言,来自六个语系:
- 日耳曼语系:英语(en)、德语(de)、荷兰语(nl)
- 罗曼语系:西班牙语(es)、法语(fr)
- 汉藏语系:中文(zh)
- 亚非语系:阿拉伯语(ar)
- 印度-雅利安语系:印地语(hi)、孟加拉语(bn)、马拉地语(mr)、尼泊尔语(ne)
- 达罗毗荼语系:泰米尔语(ta)
数据规模
- CM-MMLU:11 个代码混合语言对,12,156 个问题-选项-答案组合
- CM-TruthfulQA:4 个代码混合语言对,3,122 个多项选择题实例
- CM-GSM8K:4 个代码混合语言对,4,367 个数学问题
- MT:3 个代码混合语言对,2,711 个代码混合句子
技术信息
- 许可证:Apache-2.0
- 语言:中文、英语、西班牙语、印地语、德语、荷兰语、西弗里西亚语、法语、阿拉伯语、孟加拉语、马拉地语、尼泊尔语、泰米尔语、马拉雅拉姆语、瓜拉尼语
- 数据规模:10K-100K 样本
- 数据格式:CSV 文件
文件结构
数据集包含以下子目录的文件:
- gsm8k/
- lid/
- mmlu/
- mt/
- ner/
- pos/
- sa/
- truthfulqa/
引用信息
- 论文:CodeMixBench: Evaluating Code-Mixing Capabilities of Language Models
- BibTeX:[待补充]
搜集汇总
数据集介绍
构建方式
在多语言代码混合研究领域,CodeMixBench通过系统整合与创新合成构建而成。该数据集基于多个开源测试集进行改造,包括从MMLU测试集衍生出的代码混合版本CM-MMLU,涵盖57个学科的多选题以评估知识推理能力;从GSM8K测试集构建的CM-GSM8K,保留逐步解答的数学问题以测试数学推理;以及基于TruthfulQA的CM-TruthfulQA,采用817道多选题衡量真实性。此外还融合了LID、POS、NER等传统NLP任务,通过自动化与人工校验相结合的方式确保语言混合的自然性与准确性。
特点
CodeMixBench显著特点体现在其广泛的语言覆盖与任务多样性上。数据集包含18种语言,涉及日耳曼、罗曼、汉藏等六大语系12种代表性语言,并生成11种代码混合语言对。总计包含12,156个知识推理问题、3,122个真实性选择题、4,367个数学问题及2,711个机器翻译句子,形成多维度评估体系。其独特价值在于同时包含合成任务(如推理评估)与适应任务(如序列标注),为全面测评语言模型的代码混合理解能力提供了丰富场景。
使用方法
使用本数据集时,研究者可针对特定任务加载相应子集进行模型评估。每个任务数据文件均采用标准化CSV格式存储,包含原始文本、混合语言版本及标注信息。以CM-MMLU为例,用户可通过加载mmlu子目录下的文件获取多选题及其代码混合变体,通过对比模型在原始文本与混合文本上的表现差异评估抗干扰能力。对于序列标注任务如NER,则需同时处理混合语言中的实体边界识别与语言切换现象。所有子集均保留原始数据分割,确保测试结果的可靠性与可比性。
背景与挑战
背景概述
代码混合作为多语言交流中的常见现象,指说话者在单一话语中交替使用两种或多种语言。为系统评估大语言模型对此类复杂语言模式的理解能力,研究团队开发了CodeMixBench基准数据集,涵盖知识推理、数学推理及真实性判断等八大任务,涉及18种语言。该数据集基于MMLU、GSM8K和TruthfulQA等权威测试集构建,包含来自六大意语系的12种核心语言,通过合成跨语言对数据推动多语言自然语言处理研究的发展。
当前挑战
该数据集首要解决代码混合文本的语义理解挑战,包括语言边界模糊、语法结构冲突及跨文化语境解读等核心难题。构建过程中需克服多语言对齐的技术障碍,确保不同语系语言在词汇、句法和语义层面的准确映射,同时需保持原始任务难度与评估有效性。数据合成阶段还面临低资源语言语料稀缺、机器翻译质量不稳定,以及文化特定表达转换等实际困难。
常用场景
经典使用场景
在多语言自然语言处理研究中,CodeMixBench作为评估基准,广泛应用于测试大语言模型对混合语言文本的理解能力。该数据集通过整合知识推理、数学推理及真实性判断等八类任务,覆盖18种语言,为模型在复杂语言环境下的综合性能提供标准化测评框架。研究人员利用其多样化的语言对和任务类型,系统检验模型在代码混合场景中的泛化能力和鲁棒性。
衍生相关工作
该数据集催生了系列创新研究,包括基于CM-MMLU的多语言知识推理模型优化、结合CM-GSM8K的数学推理跨语言迁移方法,以及针对CM-TruthfulQA的混合语言真实性验证框架。这些衍生工作不仅深化了对代码混合机制的理论认知,更推动了如CodeSwitchBERT和MixLM等专用架构的发展,为多语言NLP领域开辟了新的研究方向。
数据集最近研究
最新研究方向
在多语言混合文本处理领域,CodeMixBench作为评估大语言模型理解能力的重要基准,正推动着跨语言自然语言处理的前沿探索。当前研究聚焦于提升模型对混合语言结构的语义解析能力,特别是在知识推理、数学问题求解及真实性评估等复杂任务上的表现。随着全球化交流日益频繁,代码混合现象在社交媒体、客服系统等场景中愈发普遍,该数据集为开发更鲁棒的多语言模型提供了关键支撑。相关研究不仅涉及传统的语言识别、词性标注和命名实体识别,还扩展到机器翻译和情感分析等应用层面,显著促进了跨语言人工智能系统的发展。
以上内容由遇见数据集搜集并总结生成


