pchristm/CompMix
收藏Hugging Face2023-06-19 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/pchristm/CompMix
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-4.0
task_categories:
- question-answering
- conversational
language:
- en
tags:
- complex
- question answering
- complexQA
- QA
- heterogeneous sources
pretty_name: CompMix
size_categories:
- 1K<n<10K
splits:
- name: train
num_examples: 4966
- name: validation
num_examples: 1680
- name: test
num_examples: 2764
---
# Dataset Card for ConvMix
## Dataset Description
- **Homepage:** [CompMix Website](https://qa.mpi-inf.mpg.de/compmix)
- **Point of Contact:** [Philipp Christmann](mailto:pchristm@mpi-inf.mpg.de)
### Dataset Summary
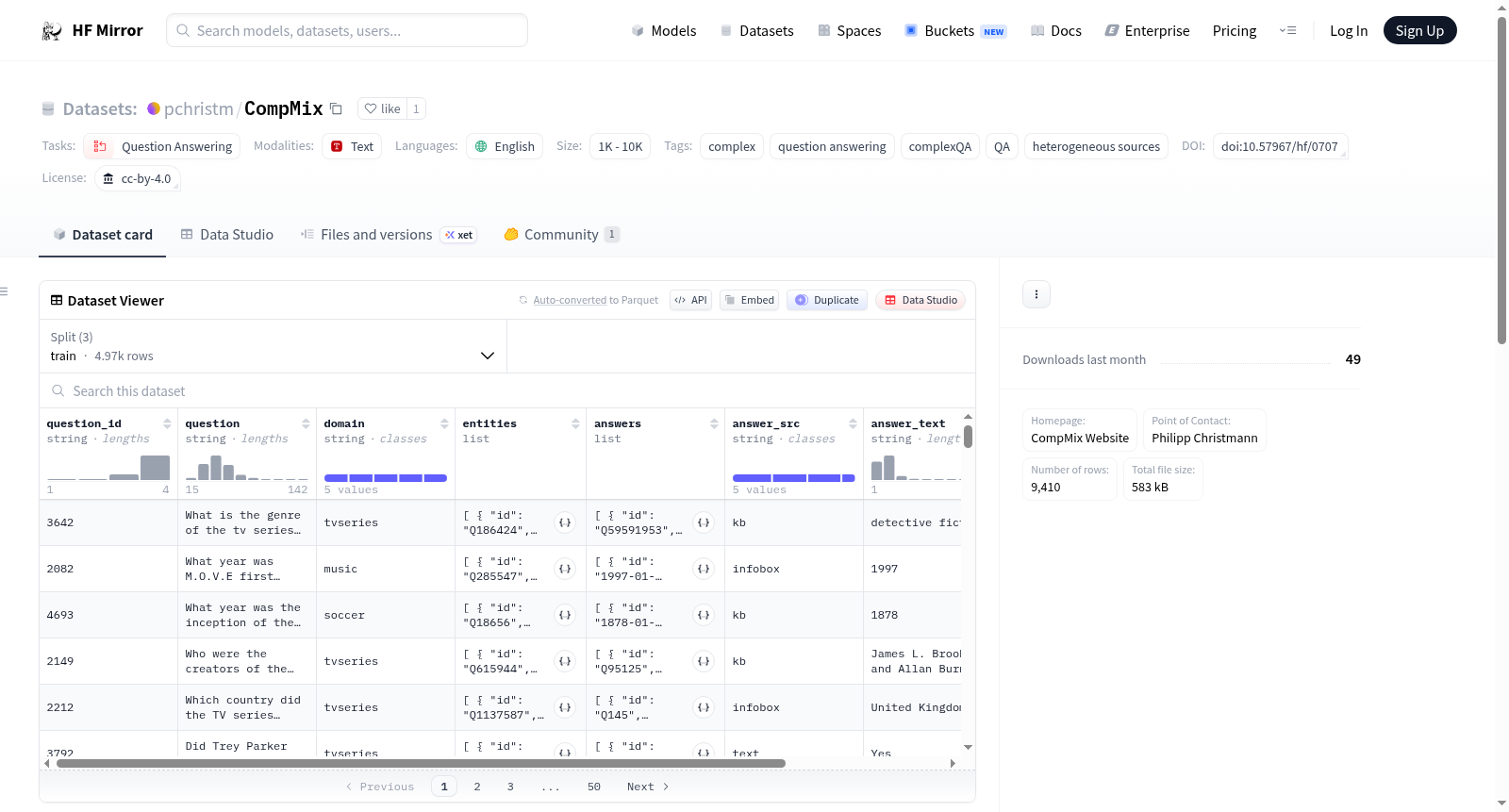
CompMix collates the completed versions of the conversational questions in the [ConvMix dataset](https://convinse.mpi-inf.mpg.de), that are provided directly by crowdworkers from Amazon Mechanical Turk (AMT). Questions in CompMix exhibit complex phenomena like the presence of multiple entities, relations, temporal conditions, comparisons, aggregations, and more. It is aimed at evaluating QA methods that operate over a mixture of heterogeneous input sources (KB, text, tables, infoboxes). The dataset has 9,410 questions, split into train (4,966 questions), dev (1,680), and test (2,764) sets. All answers provided in the CompMix dataset are grounded to the KB (except for dates which are normalized, and other literals like names).
Further details will be provided in a dedicated write-up soon.
### Dataset Creation
CompMix collates the completed versions of the conversational questions in ConvMix, that are provided directly by the crowdworkers.
The ConvMix benchmark, on which CompMix is based, was created by real humans. We tried to ensure that the collected data is as natural as possible. Master crowdworkers on Amazon Mechanical Turk (AMT) selected an entity of interest in a specific domain, and then started issuing conversational questions on this entity, potentially drifting to other topics of interest throughout the course of the conversation. By letting users choose the entities themselves, we aimed to ensure that they are more interested into the topics the conversations are based on. After writing a question, users were asked to find the answer in eithers Wikidata, Wikipedia text, a Wikipedia table or a Wikipedia infobox, whatever they find more natural for the specific question at hand. Since Wikidata requires some basic understanding of knowledge bases, we provided video guidelines that illustrated how Wikidata can be used for detecting answers, following an example conversation. For each conversational question, that might be incomplete, the crowdworker provides a completed question that is intent-explicit, and can be answered without the conversational context. These questions constitute the CompMix dataset. We provide also the answer source the user found the answer in and question entities.
---
license: CC BY 4.0
task_categories:
- 问答(question-answering)
- 会话式(conversational)
language:
- 英语(en)
tags:
- 复杂(complex)
- 问答(question answering)
- 复杂问答(complexQA)
- QA(QA)
- 异构数据源(heterogeneous sources)
pretty_name: CompMix
size_categories:
- 1000 < 样本数 < 10000
splits:
- name: train
num_examples: 4966
- name: validation
num_examples: 1680
- name: test
num_examples: 2764
---
# 《CompMix数据集卡片》
## 数据集说明
- **主页**:[CompMix官方网站](https://qa.mpi-inf.mpg.de/compmix)
- **联系人**:[Philipp Christmann](mailto:pchristm@mpi-inf.mpg.de)
### 数据集概述
CompMix整合了[ConvMix数据集](https://convinse.mpi-inf.mpg.de)中会话式问题的完整版本,这些完整问题由亚马逊机械Turk(Amazon Mechanical Turk,简称AMT)平台的众包工作者直接提供。CompMix中的问题包含多种复杂现象,例如多实体、多关系、时序条件、比较、聚合等。该数据集旨在评估可处理混合异构输入源(知识库(KB)、文本、表格、信息框)的问答方法。数据集共包含9410个问题,划分为训练集(4966个问题)、验证集(1680个问题)与测试集(2764个问题)。CompMix数据集中的所有答案均锚定至知识库(KB)(日期已做归一化处理,姓名等其他字面量除外)。
更多细节将在后续的专门研究论文中公布。
### 数据集构建
CompMix整合了ConvMix数据集中会话式问题的完整版本,这些版本由众包工作者直接提供。
CompMix所基于的ConvMix基准数据集由真实人类参与者构建。我们力求确保所收集的数据尽可能自然。亚马逊机械Turk(AMT)平台的资深众包工作者会在特定领域中选取一个感兴趣的实体,随后围绕该实体发起会话式问题,在对话过程中也可能转向其他感兴趣的话题。通过让用户自主选择实体,我们旨在确保参与者对对话所围绕的话题拥有更高的兴趣度。编写完问题后,参与者需要从维基数据(Wikidata)、维基百科文本、维基百科表格或维基百科信息框中寻找对应问题的答案,选择他们认为对当前问题最自然的来源即可。由于使用维基数据需要具备一定的知识库基础知识,我们提供了视频指南,通过示例对话演示如何利用维基数据查找问题答案。针对每个可能不完整的会话式问题,众包工作者需要提供一个意图明确、无需依赖会话上下文即可回答的完整问题,这些完整问题便构成了CompMix数据集。我们同时提供了参与者查找答案所用的来源以及问题所涉及的实体。
提供机构:
pchristm
原始信息汇总
数据集概述
基本信息
- 许可证: cc-by-4.0
- 任务类别:
- 问答
- 对话
- 语言: 英语
- 标签:
- 复杂
- 问答
- complexQA
- QA
- 异构来源
- 美观名称: CompMix
- 数据集大小: 1K<n<10K
数据集结构
- 训练集: 4,966个问题
- 验证集: 1,680个问题
- 测试集: 2,764个问题
数据集内容
- 数据来源: 由Amazon Mechanical Turk的众包工作者直接提供
- 问题特点: 包含多实体、关系、时间条件、比较、聚合等复杂现象
- 答案基础: 所有答案均基于知识库(KB),日期和其他文字(如名称)除外
数据集创建
- 创建方式: 基于ConvMix基准,由众包工作者选择感兴趣的实体,并围绕该实体发起对话式问题
- 答案查找: 用户根据问题在Wikidata、Wikipedia文本、表格或信息框中查找答案
- 额外提供: 提供用户找到答案的来源和问题实体
搜集汇总
数据集介绍
构建方式
在对话式问答领域,CompMix数据集的构建体现了对自然语言复杂性的深度捕捉。该数据集源自ConvMix基准,通过亚马逊众包平台招募经验丰富的工作人员,围绕特定领域实体自主发起多轮对话,并允许话题自然迁移。工作人员在提出问题后,需从异构知识源(如知识库、文本、表格或信息框)中寻找答案,确保回答过程贴合人类自然查询习惯。每道对话式问题均被转化为意图明确的完整问句,从而形成可直接脱离上下文理解的独立问答对,最终构建出包含9,410个问题的数据集。
特点
CompMix数据集的核心特征在于其问题蕴含丰富的复杂语义结构。该数据集涵盖了多实体关联、关系推理、时间条件、比较与聚合等多种复杂现象,充分模拟了真实场景下的问答挑战。所有答案均基于知识库进行标注(日期与专有名词等字面值已规范化),确保了答案的可靠性与可验证性。数据划分清晰,包含训练集、验证集与测试集,适用于评估跨异构信息源的问答系统性能,为复杂问答研究提供了高质量的基准资源。
使用方法
该数据集适用于训练与评估面向异构知识源的复杂问答模型。研究人员可将数据集按既定划分用于模型训练、验证与测试,重点关注模型在理解复杂问题、融合多源信息及生成准确答案方面的能力。使用时应遵循数据提供的答案来源与实体标注,结合知识库、文本、表格等信息进行多模态推理。数据集以标准化格式发布,便于集成至现有机器学习流程,推动对话式问答与知识融合技术的进一步发展。
背景与挑战
背景概述
在知识推理与问答系统领域,复杂对话式问题的处理一直是研究的前沿课题。CompMix数据集由马克斯·普朗克信息学研究所的Philipp Christmann等人于近年创建,旨在评估基于异构信息源(如知识库、文本、表格和信息框)的问答方法。该数据集源自ConvMix基准,通过亚马逊众包平台收集了9,410个自然对话问题,聚焦于多实体、关系、时间条件和聚合等复杂现象,推动了开放域问答系统向更真实、多源交互场景的演进。
当前挑战
CompMix数据集面临的挑战主要体现在两个方面:其一,在领域问题层面,它旨在解决复杂对话式问答中多源异构信息的融合与推理难题,要求模型同时处理知识库的结构化数据与非结构化文本,并应对实体链接、时序逻辑和比较查询等复杂语义;其二,在构建过程中,众包设计需确保问题的自然性与多样性,同时引导工作者跨越不同信息源寻找答案,这涉及对知识库使用的培训与质量控制,以维持数据的一致性与可靠性。
常用场景
经典使用场景
在复杂问答系统研究领域,CompMix数据集以其涵盖多实体、关系、时间条件及聚合等复杂现象的特点,成为评估异构信息源整合能力的基准工具。该数据集通过收集来自知识库、文本、表格和信息框的多样化数据,为模型提供了模拟真实对话场景的测试环境,尤其适用于检验系统在上下文缺失情况下处理意图明确问题的性能。
解决学术问题
CompMix有效应对了传统问答系统难以处理复杂语义结构和多源信息融合的学术挑战。它通过提供人工标注的完整问题版本,解决了对话语境依赖性问题,促进了模型在实体链接、关系推理及跨模态理解方面的研究进展,为构建更鲁棒、可解释的智能问答框架奠定了数据基础。
衍生相关工作
基于CompMix的异构源特性,衍生出多篇聚焦于知识图谱增强、跨源推理及对话状态跟踪的经典研究。这些工作不仅优化了BERT、T5等预训练模型在复杂QA任务上的微调策略,还推动了如UniKQA等统一框架的发展,进一步拓展了多模态学习与可解释人工智能的研究边界。
以上内容由遇见数据集搜集并总结生成


