insurance-charge-mlops-logs
收藏Hugging Face2026-02-08 更新2026-02-09 收录
下载链接:
https://huggingface.co/datasets/salmadrigal/insurance-charge-mlops-logs
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含由已部署的机器学习模型生成的推理日志,该模型根据客户属性预测保险费用。数据由运行在Hugging Face Spaces上的Gradio应用程序生成,作为MLOps学习项目的一部分。数据集包含以下字段:`age`(个体年龄)、`bmi`(身体质量指数)、`children`(家属数量)、`sex`(性别,`male`或`female`)、`smoker`(吸烟状态,`yes`或`no`)、`region`(居住地区)和`prediction`(预测的保险费用,美元)。数据生成使用线性回归模型(scikit-learn)进行在线推理,每次用户交互时记录。该数据集适用于演示推理日志记录、监控模型输出以及MLOps实验和学习。需要注意的是,数据来自用户输入,可能不反映真实世界分布,且如果应用程序重新部署,日志可能会重置。
创建时间:
2026-02-08
原始信息汇总
数据集概述
基本描述
- 数据集名称:Insurance Charge MLOps Logs
- 数据集用途:包含一个用于预测保险费用的已部署机器学习模型在推理阶段生成的日志。
- 数据来源:数据由一个运行在Hugging Face Spaces上的Gradio应用程序生成,属于MLOps学习项目的一部分。
技术细节
- 任务类别:回归
- 模型类型:线性回归(scikit-learn)
- 推理类型:在线推理
- 日志记录方式:按用户交互记录
数据列说明
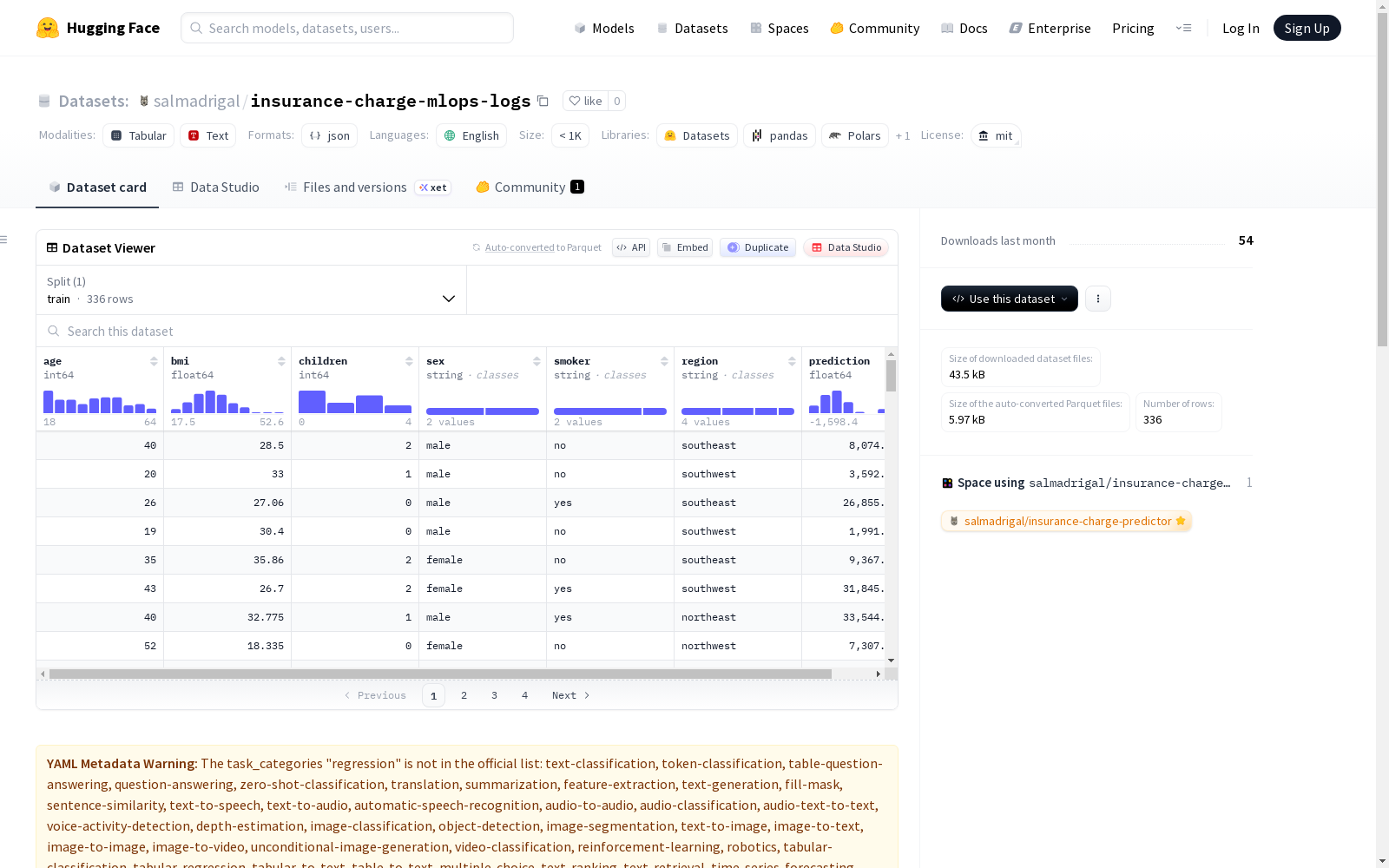
age:个人年龄bmi:身体质量指数children:受抚养人数sex:性别(male,female)smoker:吸烟状况(yes,no)region:居住地区prediction:预测的保险费用(美元)
预期用途
- 用于演示推理日志记录
- 用于监控模型输出
- 用于MLOps实验与学习
局限性
- 数据来源于用户输入,可能无法反映真实世界的数据分布
- 如果应用程序重新部署,日志可能会重置
作者信息
- 作者:Salvador Madrigal
许可信息
- 许可证:MIT
搜集汇总
数据集介绍
构建方式
在机器学习运维(MLOps)的实践框架下,该数据集通过一个部署于Hugging Face Spaces的Gradio应用程序动态生成。该应用集成了一个基于scikit-learn构建的线性回归模型,专门用于预测保险费用。每当用户通过交互界面输入个人属性时,模型便执行在线推理,系统随即自动记录包括年龄、身体质量指数、吸烟状况等特征及对应的预测费用,形成一条条实时的推理日志。这种构建方式模拟了生产环境中模型服务的监控流程,为MLOps学习提供了贴近实际的日志数据源。
特点
作为MLOps教学与实验的专用数据集,其核心特点在于完全由模拟用户交互的在线推理过程产生,涵盖了预测任务中典型的结构化特征。数据字段明确,包括年龄、性别、吸烟状况等人口统计学与健康指标,以及模型输出的保险费用预测值。然而,由于数据生成依赖于临时用户输入,其分布可能无法精确反映真实世界的人口统计规律,且应用重新部署可能导致日志重置,这要求使用者在分析时注意其固有的仿真性质与潜在的不稳定性。
使用方法
该数据集主要服务于机器学习运维的教育与研究场景。使用者可将其用于演示和构建推理日志管道,实践如何收集与存储模型服务过程中的输入输出记录。进一步,通过对日志中预测结果的持续监控与分析,可以探索模型在生产环境中的表现稳定性与潜在偏差。它也为实验模型监控、警报机制设计等MLOps核心环节提供了可直接操作的数据基础,助力学习者掌握从模型部署到运维监控的完整工作流。
背景与挑战
背景概述
在机器学习运维(MLOps)领域,模型部署后的监控与日志记录是确保系统可靠性与持续改进的关键环节。Insurance Charge MLOps Logs数据集由Salvador Madrigal于近期创建,作为一项MLOps学习项目的一部分,旨在通过一个基于Gradio应用部署的线性回归模型,记录用户交互过程中产生的保险费用预测推理日志。该数据集聚焦于在线推理场景,通过捕获年龄、身体质量指数、吸烟状况等用户属性及其对应的预测费用,为研究人员和从业者提供了研究模型行为、输出监控及运维实验的实证基础,推动了MLOps教育与实践的紧密结合。
当前挑战
该数据集所解决的领域问题在于保险费用预测模型的在线推理监控,其核心挑战包括模型输出漂移的检测与解释,以及如何在非稳态用户输入分布下维持预测一致性。构建过程中,数据生成依赖于模拟用户交互,可能无法完全反映真实世界的人口统计与行为模式,导致数据分布偏差;同时,应用重新部署可能导致日志重置,影响长期监控的连续性,这些因素共同对数据集的代表性与稳定性提出了考验。
常用场景
经典使用场景
在机器学习运维(MLOps)领域,该数据集作为在线推理日志的典型范例,常用于模型部署后的性能监控与分析。研究人员和工程师借助这些日志数据,能够追踪模型在真实交互环境中的预测行为,从而评估其稳定性和可靠性。通过分析年龄、BMI、吸烟状况等特征与预测保险费用之间的关系,该数据集为模型输出的一致性检验提供了实证基础,助力于构建可解释的机器学习流水线。
解决学术问题
该数据集主要解决了机器学习模型在部署后缺乏实时监控数据的学术挑战,为模型漂移检测和性能退化研究提供了关键素材。通过记录用户交互产生的预测日志,它使得研究者能够深入探究输入特征分布变化对模型输出的影响,进而推动自适应学习与在线评估方法的发展。其意义在于弥合了理论模型与生产环境之间的鸿沟,促进了MLOps领域的实证研究与标准化实践。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在MLOps工具链的开发与优化上,例如基于推理日志的自动化警报系统和模型版本控制框架。研究人员利用其结构化的日志格式,构建了用于检测数据漂移的实时监控平台,并探索了结合线性回归模型与日志分析的可解释性方法。这些工作不仅丰富了机器学习生命周期管理的技术栈,也为跨行业部署可扩展的预测系统提供了参考范式。
以上内容由遇见数据集搜集并总结生成


