clembench2024
收藏arXiv2024-05-31 更新2024-06-21 收录
下载链接:
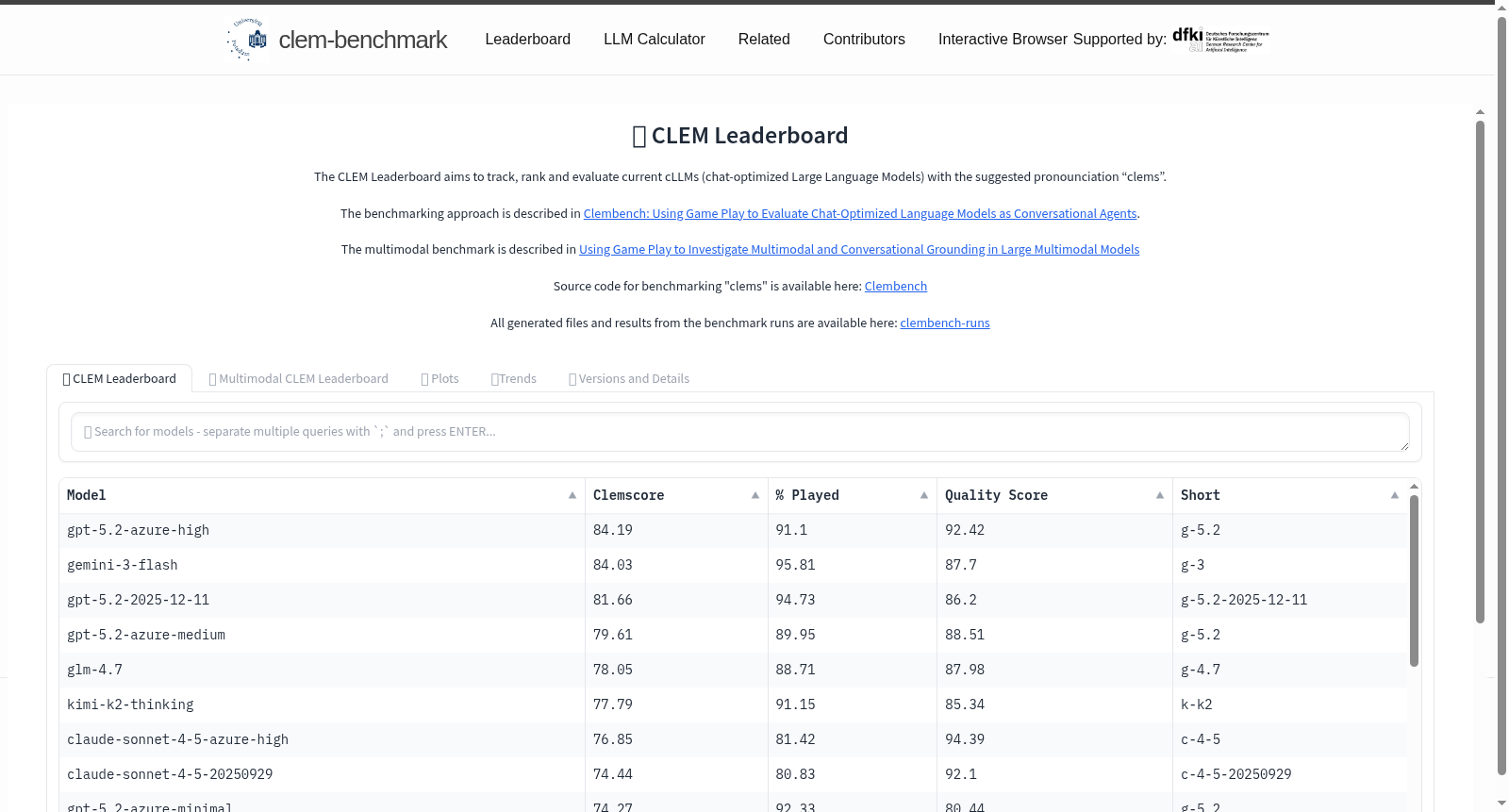
https://clembench.github.io/leaderboard.html
下载链接
链接失效反馈官方服务:
资源简介:
clembench2024是由德国波茨坦大学语言学系计算语言学部创建的多语言基准测试数据集,旨在评估大型语言模型(LLMs)作为多动作代理的能力。该数据集包含53个模型,通过动态和挑战性的对话游戏来测试模型的指令遵循、战略目标导向和语言理解能力。数据集的创建过程涉及使用模板和解析规则来定义游戏,并通过程序化的GameMaster实现游戏玩法。clembench2024的应用领域包括模型选择决策、交互系统的详细研究以及作为闭环开发环境的一部分,用于设计和改进代理。
ClemBench2024 is a multilingual benchmark dataset developed by the Department of Computational Linguistics, Faculty of Linguistics, University of Potsdam, Germany, which aims to evaluate the capabilities of large language models (LLMs) as multi-action agents. This dataset includes 53 models, and uses dynamic and challenging dialogue games to test the models' abilities in instruction following, strategic goal-directed behavior and language comprehension. The dataset creation process involves using templates and parsing rules to define the games, and implementing the game mechanics via a programmatic GameMaster. The application domains of ClemBench2024 include model selection decision-making, in-depth research on interactive systems, and serving as part of a closed-loop development environment for designing and improving AI agents.
提供机构:
德国波茨坦大学语言学系计算语言学部
创建时间:
2024-05-31
搜集汇总
数据集介绍
构建方式
在对话智能评估领域,clembench2024采用了一种基于游戏自演的动态构建方法。该框架通过定义游戏模板、响应解析规则和游戏流程,将大型语言模型置于多轮对话游戏中,由程序化的GameMaster实例化具体游戏场景并驱动交互过程。游戏模板以自然语言描述目标,解析规则确保响应的形式合规性,而游戏流程则界定终止状态,从而实现对模型交互能力的结构化测评。这种分离游戏规范与实例的设计,使得基准能够动态生成新实例,有效规避数据污染问题,同时保持评估的一致性与可扩展性。
特点
clembench2024展现出多重显著特征,其动态性体现在通过模板与实例分离实现持续更新,确保基准长期有效且抗污染。挑战性方面,即使最优模型的表现仍显著低于人类专家水平,表明评估任务具备充分的难度空间。互补性上,该基准与基于参考的HELM及基于偏好的Chatbot Arena形成有效补充,尤其与交互式评估结果高度相关。灵活性则通过通用化接口支持多样模型集成,涵盖开源与闭源模型,便于追踪领域进展。此外,多语言扩展能力允许通过翻译模板轻松实现跨语言评估,为探究模型的多语言交互指令遵循能力提供了有力工具。
使用方法
使用clembench2024时,研究者可通过其开源框架配置特定游戏与模型,进行自动化交互评估。框架支持通过Hugging Face Transformers等本地方式或各类API接入语言模型,由GameMaster依据游戏模板驱动多轮对话,并自动记录交互过程。评估结果依据游戏特定评分规则计算,主要指标涵盖游戏完成率与游戏质量得分,两者乘积构成综合分数。该基准适用于模型能力比较、发展趋势追踪及特定行为研究,例如通过多语言案例考察模型的跨语言指令遵循能力,为构建目标导向的交互系统提供实证依据。
背景与挑战
背景概述
clembench2024是由波茨坦大学计算语言学团队与德国人工智能研究中心合作开发的一个动态、多语言基准测试框架,旨在评估大型语言模型作为多行动智能体的交互能力。该框架基于2023年提出的clemgame理念,通过设计对话游戏的自博弈环境,深入探究模型在通用指令遵循、战略目标导向及语言理解等方面的核心性能。其创新之处在于将游戏规范与具体实例分离,不仅有效避免了数据污染问题,还为追踪模型演进提供了灵活工具,对推动交互式人工智能系统的开发与评估具有重要影响力。
当前挑战
clembench2024致力于解决交互式语言模型评估中的关键挑战,其核心在于如何精准衡量模型在复杂、目标导向的对话场景中的战略推理与多轮次协作能力。构建过程中的主要挑战包括设计具有高构念效度的游戏任务,确保评估聚焦于模型的内在能力而非特定实例的记忆;同时,框架需保持高度动态性以适配快速迭代的新模型,并实现多语言扩展,这要求对游戏模板与解析规则进行细致翻译与跨语言验证,以保障评估的一致性与可靠性。
常用场景
经典使用场景
在大型语言模型评估领域,clembench2024作为一种动态、多语言的基准测试框架,其经典使用场景在于通过对话游戏的自博弈机制,系统性地评估模型在交互式任务中的表现。该框架将游戏逻辑与具体实例分离,允许研究者利用自然语言提示模板定义游戏目标,进而考察模型在遵循格式规则、执行策略性游戏玩法等方面的能力。例如,在猜词游戏或图像描述任务中,模型需理解复杂指令并生成符合规范的响应,从而揭示其在多轮对话环境下的综合性能。
解决学术问题
clembench2024主要解决了大型语言模型评估中静态数据集易受数据污染、难以反映动态交互能力的学术难题。该框架通过自博弈设计,实现了对模型指令遵循、目标导向策略及多语言理解等核心构造效度的量化测量。其动态生成游戏实例的特性有效避免了训练数据泄露问题,同时与人类专家表现的高差距表明模型在交互任务上仍有显著提升空间,为模型能力边界研究提供了可靠工具。
衍生相关工作
该数据集衍生了一系列围绕交互式评估范式的经典研究工作。例如,GameEval框架通过设计二十问等社交推理游戏探索模型对话能力;SmartPlay基准将评估扩展到更广泛的智能体游戏场景;SOTOPIA则专注于语言模型社会智能的交互评估。这些工作与clembench共同推动了从静态文本理解到动态交互评估的范式转变,并为后续研究如GTBench的游戏理论分析提供了方法论基础。
以上内容由遇见数据集搜集并总结生成


