MVRL/GeoSound
收藏Hugging Face2026-05-06 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/MVRL/GeoSound
下载链接
链接失效反馈官方服务:
资源简介:
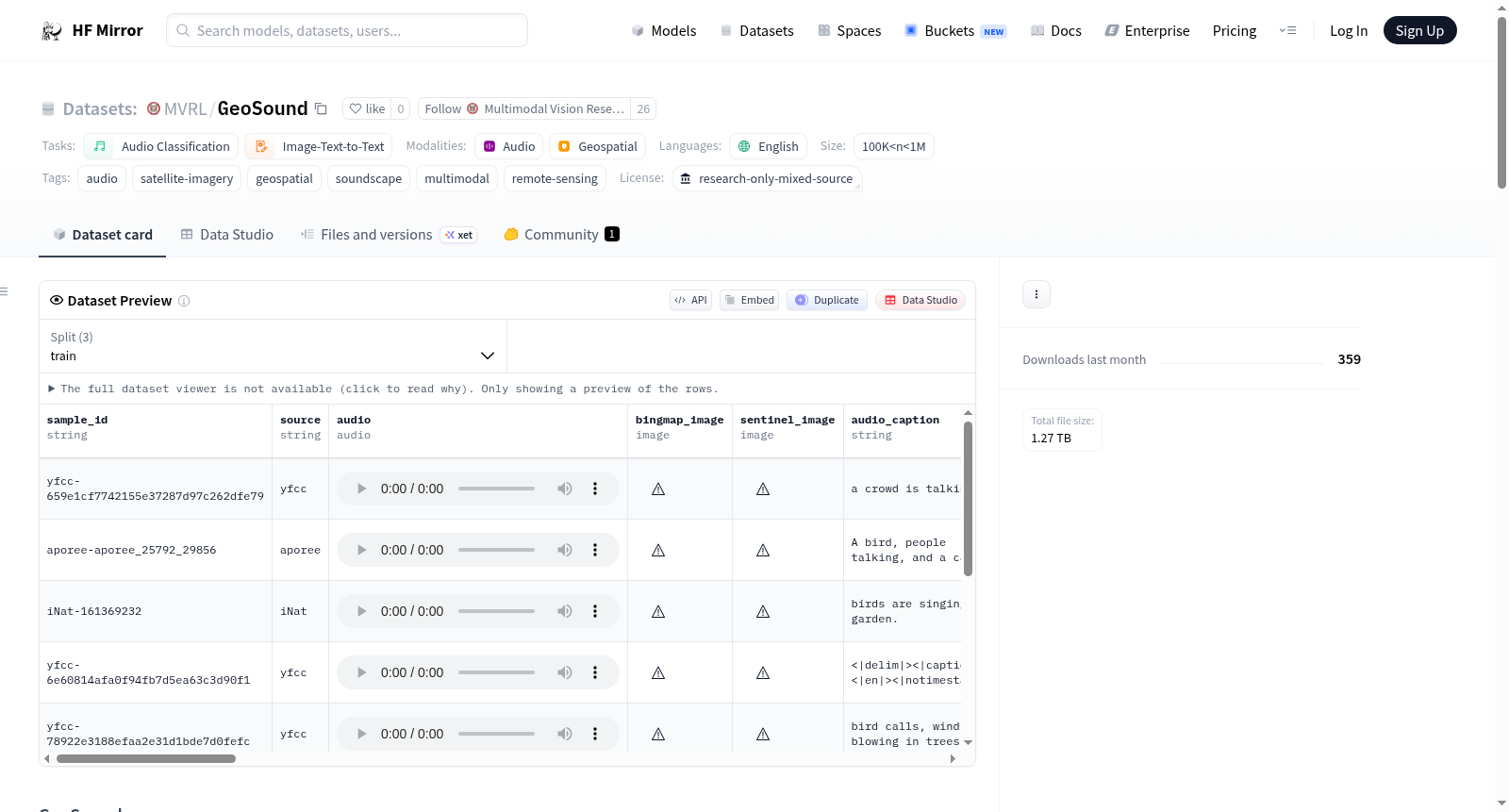
GeoSound是一个地理参考的声音景观数据集,它将卫星/航空图像与环境音频记录配对。数据集汇集了来自四个众包平台(Freesound、Aporee、iNaturalist和Flickr/YFCC100M集合)的记录,覆盖了广泛的地理区域。数据集采用基于单元格的地理分区策略进行训练/验证/测试分割,以防止分割之间的地理泄漏。数据集包含音频、卫星图像、音频描述、地理位置信息等多种字段,适用于音频分类和图像文本到文本的任务。数据集严格限制用于非商业学术研究用途。
GeoSound is a geo-referenced soundscape dataset that pairs satellite/aerial imagery with environmental audio recordings. It aggregates recordings from four crowdsourcing platforms (Freesound, Aporee, iNaturalist, and Flickr/YFCC100M collection) and covers a wide geographic footprint. The dataset uses a cell-based geographic partitioning strategy for train/val/test splits to prevent geographic leakage between splits. It includes various fields such as audio, satellite images, audio captions, and geographic location information, suitable for tasks like audio classification and image-text-to-text. The dataset is strictly for non-commercial academic research use only.
提供机构:
MVRL
搜集汇总
数据集介绍
构建方式
GeoSound数据集是一个地理参考声景数据集,通过整合来自Freesound、Aporee、iNaturalist和Flickr(通过YFCC100M集合)四个众包平台的音频记录与卫星或航空影像构建而成。其数据划分采用基于空间单元的差异化地理分区策略,将地球表面划分为独立的地理单元,并确保每个完整单元仅归属于训练集、验证集或测试集之一,从而有效避免了数据在地理维度上的信息泄露。数据集涵盖超过三十万个样本,每个样本均包含32kHz的原始音频、Bing Maps航空影像图块、Sentinel-2卫星影像图块以及丰富的元数据字段,例如录音坐标、日期、物种信息等。
使用方法
用户可通过HuggingFace的datasets库便捷加载GeoSound数据集,推荐采用流式加载模式以应对其庞大的数据量。加载后可获取每个样本的音频波形(32kHz)、PIL格式的遥感影像、音频文本描述以及经纬度信息。预计算的mel特征以浮点型四维数组形式提供,形状为(5,1,1001,64),用户可选取其中一个切片作为模型输入。由于数据集各维度数据已结构化,研究者可直接基于其预设的划分进行训练、验证与测试,无需额外处理数据泄露问题。需注意,该数据集仅限非商业学术研究使用,音频版权归原始上传者所有,影像使用须遵循相关服务商条款。
背景与挑战
背景概述
GeoSound是一个面向地理声景分析的多模态数据集,由Subash Khanal等研究人员于2024年创建,隶属于ACM Multimedia会议中提出的PSM项目。该数据集的核心目标是将卫星与航拍影像同环境音频记录相匹配,旨在推动地理空间感知与声景映射领域的交叉研究。通过整合Freesound、Aporee、iNaturalist及Flickr(YFCC100M)四大众包平台的音频资源,GeoSound覆盖了广泛的地理区域,为音频分类与图像-文本-语音任务提供了丰富的数据基础,在遥感与声学生态学中具有重要影响力。
当前挑战
该数据集面临的挑战包括:1) 领域问题层面,需解决地理声景中音频与视觉模态间的异质性对齐问题,例如不同地区环境噪声与地物特征的复杂关联,以及零样本声景映射中的泛化难题;2) 构建过程中,从四个异构众包平台聚合数据时面临元数据不一致、音频采样率差异(如mp3与wav格式混存)及地理坐标精度不一等障碍,且需通过基于空间分区的细胞划分策略避免数据泄漏,确保训练、验证与测试集的地理独立性。
常用场景
经典使用场景
GeoSound数据集为跨模态地理感知研究提供了独特的桥梁,将卫星或航空影像与实地环境录音进行配对,构建了覆盖全球的声景地图。其最经典的使用场景在于训练和评估能够同时理解视觉与听觉信息的模型,例如基于对比学习的多模态预训练任务,模型需从图像和音频对中学习语义对齐,从而实现对任意地理位置的声景进行零样本预测。这种设置摆脱了对单一传感器的依赖,为地理环境理解开辟了全新的技术路径。
解决学术问题
该数据集有效解决了地理声景大规模映射中的核心难题——缺乏带有空间标签的配对多模态数据。学术研究中,它使得零样本声景分类成为可能,模型可在未见过的区域根据卫星图像推断其声音生态特征,突破了传统声学监测依赖实地部署的限制。进一步地,GeoSound推动了对地理环境多模态表征学习的探索,研究者得以量化视觉与听觉信号之间的统计关联,为理解人类感知与环境之间的复杂耦合关系提供了数据驱动的实验平台。
实际应用
在实际应用中,GeoSound为城市规划与生态监测提供了非侵入式的快速评估工具。例如,城市规划者可通过卫星图像结合模型预测结果,评估不同区域的潜在噪音水平或环境声学舒适度,替代耗时的人工采样。生物多样性监测方面,该数据助力科研人员远程追踪特定物种的声学活动范围,为自然保护区管理决策提供低成本的初步筛查依据。此外,基于视觉-听觉关联的旅游导览、数字孪生城市构建等商业场景也展现出广阔前景。
数据集最近研究
最新研究方向
GeoSound数据集的最新研究方向聚焦于多模态地理声景映射,利用配对卫星影像与音频记录,结合大规模众包数据,推动零样本声景分类与空间声音感知建模。该数据集通过地理基元的细胞划分策略有效防止空间泄漏,为跨尺度的声景生态监测与环境声学理解提供了标准化基准。当前热点包括基于概率嵌入的声景映射技术,以及将遥感影像与音频特征对齐的多模态学习方法,其应用延伸至生物多样性监测、城市噪音评估与生态系统动态感知。这一资源对地理空间人工智能与计算声学交叉领域具有里程碑意义,促进了地球观测与环境听觉数据的深度融合。
以上内容由遇见数据集搜集并总结生成


