shangzhu/ChemQA
收藏Hugging Face2024-05-26 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/shangzhu/ChemQA
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- en
dataset_info:
features:
- name: image
dtype: image
- name: question
dtype: string
- name: choices
dtype: string
- name: label
dtype: int64
- name: description
dtype: string
- name: id
dtype: string
splits:
- name: train
num_bytes: 705885259.25
num_examples: 66166
- name: valid
num_bytes: 100589192.25
num_examples: 9486
- name: test
num_bytes: 100021131.0
num_examples: 9480
download_size: 866619578
dataset_size: 906495582.5
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: valid
path: data/valid-*
- split: test
path: data/test-*
---
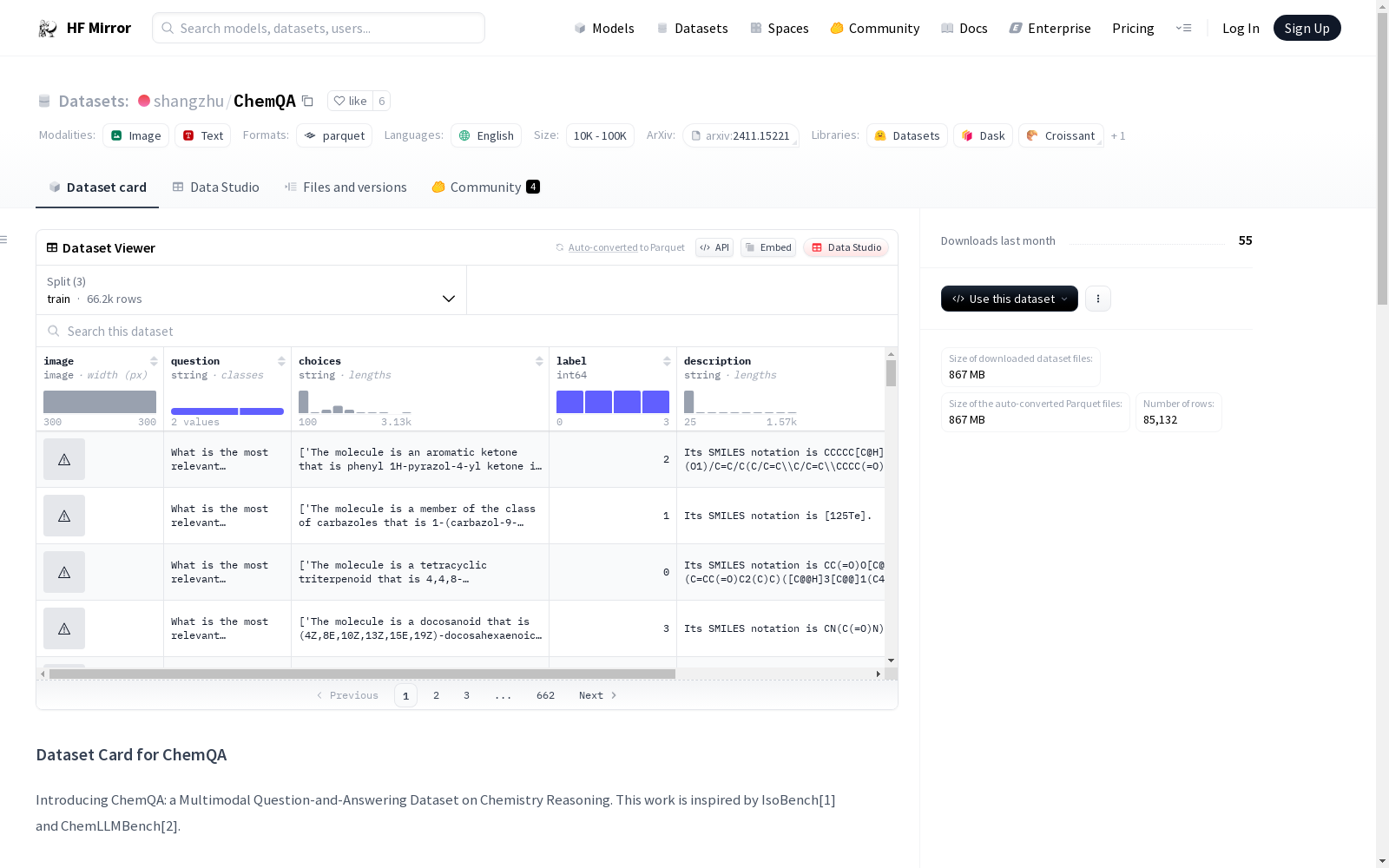
# Dataset Card for ChemQA
Introducing ChemQA: a Multimodal Question-and-Answering Dataset on Chemistry Reasoning. This work is inspired by IsoBench[1] and ChemLLMBench[2].
## Content
There are 5 QA Tasks in total:
* Counting Numbers of Carbons and Hydrogens in Organic Molecules: adapted from the 600 PubChem molecules created from [2], evenly divided into validation and evaluation datasets.
* Calculating Molecular Weights in Organic Molecules: adapted from the 600 PubChem molecules created from [2], evenly divided into validation and evaluation datasets.
* Name Conversion: From SMILES to IUPAC: adapted from the 600 PubChem molecules created from [2], evenly divided into validation and evaluation datasets.
* Molecule Captioning and Editing: inspired by [2], adapted from dataset provided in [3], following the same training, validation and evaluation splits.
* Retro-synthesis Planning: inspired by [2], adapted from dataset provided in [4], following the same training, validation and evaluation splits.
## Load the Dataset
```python
from datasets import load_dataset
dataset_train = load_dataset('shangzhu/ChemQA', split='train')
dataset_valid = load_dataset('shangzhu/ChemQA', split='valid')
dataset_test = load_dataset('shangzhu/ChemQA', split='test')
```
## Reference
[1] Fu, D., Khalighinejad, G., Liu, O., Dhingra, B., Yogatama, D., Jia, R., & Neiswanger, W. (2024). IsoBench: Benchmarking Multimodal Foundation Models on Isomorphic Representations.
[2] Guo, T., Guo, kehan, Nan, B., Liang, Z., Guo, Z., Chawla, N., Wiest, O., & Zhang, X. (2023). What can Large Language Models do in chemistry? A comprehensive benchmark on eight tasks. Advances in Neural Information Processing Systems (Vol. 36, pp. 59662–59688).
[3] Edwards, C., Lai, T., Ros, K., Honke, G., Cho, K., & Ji, H. (2022). Translation between Molecules and Natural Language. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 375–413.
[4] Irwin, R., Dimitriadis, S., He, J., & Bjerrum, E. J. (2022). Chemformer: a pre-trained transformer for computational chemistry. Machine Learning: Science and Technology, 3(1), 15022.
## Citation
```BibTeX
@misc{chemQA2024,
title={ChemQA: a Multimodal Question-and-Answering Dataset on Chemistry Reasoning},
author={Shang Zhu and Xuefeng Liu and Ghazal Khalighinejad},
year={2024},
publisher={Hugging Face},
howpublished={\url{https://huggingface.co/datasets/shangzhu/ChemQA}},
}
```
## Contact
shangzhu@umich.edu
---
language:
- 英语
dataset_info:
特征:
- 名称: 图像(image)
数据类型: 图像
- 名称: 问题
数据类型: 字符串
- 名称: 选项
数据类型: 字符串
- 名称: 标签
数据类型: 64位整数
- 名称: 描述
数据类型: 字符串
- 名称: 编号
数据类型: 字符串
划分集:
- 名称: 训练集
字节数: 705885259.25
样本数: 66166
- 名称: 验证集
字节数: 100589192.25
样本数: 9486
- 名称: 测试集
字节数: 100021131.0
样本数: 9480
下载大小: 866619578
数据集总大小: 906495582.5
configs:
- 配置名称: default
数据文件:
- 划分集: 训练集
路径: data/train-*
- 划分集: 验证集
路径: data/valid-*
- 划分集: 测试集
路径: data/test-*
---
# ChemQA数据集卡片
本数据集为ChemQA:一款面向化学推理的多模态问答数据集。本研究的设计灵感来源于IsoBench[1]与ChemLLMBench[2]。
## 数据集内容
本数据集共包含5项问答任务:
* 有机分子碳氢原子计数任务:改编自文献[2]构建的600个PubChem分子,样本被均分为验证集与测试集。
* 有机分子分子量计算任务:改编自文献[2]构建的600个PubChem分子,样本被均分为验证集与测试集。
* 名称转换任务:从简化分子线性输入规范(SMILES,Simplified Molecular-Input Line-Entry System)到国际纯粹与应用化学联合会(IUPAC,International Union of Pure and Applied Chemistry)命名转换:改编自文献[2]构建的600个PubChem分子,样本被均分为验证集与测试集。
* 分子描述与编辑任务:受文献[2]启发,改编自文献[3]提供的数据集,沿用其训练、验证与测试集划分方式。
* 逆合成规划任务:受文献[2]启发,改编自文献[4]提供的数据集,沿用其训练、验证与测试集划分方式。
## 数据集加载
可通过以下Python代码加载该数据集:
python
from datasets import load_dataset
dataset_train = load_dataset('shangzhu/ChemQA', split='train')
dataset_valid = load_dataset('shangzhu/ChemQA', split='valid')
dataset_test = load_dataset('shangzhu/ChemQA', split='test')
## 参考文献
[1] Fu, D., Khalighinejad, G., Liu, O., Dhingra, B., Yogatama, D., Jia, R., & Neiswanger, W. (2024). IsoBench:面向同构表征的多模态基础模型基准测试。
[2] Guo, T., Guo, Kehan, Nan, B., Liang, Z., Guo, Z., Chawla, N., Wiest, O., & Zhang, X. (2023). 大语言模型(Large Language Model,LLM)在化学领域能做什么?八项任务的全面基准测试. 《神经信息处理系统进展》(第36卷,第59662–59688页)。
[3] Edwards, C., Lai, T., Ros, K., Honke, G., Cho, K., & Ji, H. (2022). 分子与自然语言间的转换. 《2022年经验方法自然语言处理会议论文集》, 第375–413页。
[4] Irwin, R., Dimitriadis, S., He, J., & Bjerrum, E. J. (2022). Chemformer:一款面向计算化学的预训练Transformer模型. 《机器学习:科学与技术》, 第3卷第1期, 第15022页。
## 引用格式
BibTeX
@misc{chemQA2024,
title={ChemQA: a Multimodal Question-and-Answering Dataset on Chemistry Reasoning},
author={Shang Zhu and Xuefeng Liu and Ghazal Khalighinejad},
year={2024},
publisher={Hugging Face},
howpublished={url{https://huggingface.co/datasets/shangzhu/ChemQA}},
}
## 联系方式
shangzhu@umich.edu
提供机构:
shangzhu
原始信息汇总
数据集概述
数据集名称
ChemQA
数据集内容
- 任务类型:Multimodal Question-and-Answering on Chemistry Reasoning
- 具体任务:
- Counting Numbers of Carbons and Hydrogens in Organic Molecules
- Calculating Molecular Weights in Organic Molecules
- Name Conversion: From SMILES to IUPAC
- Molecule Captioning and Editing
- Retro-synthesis Planning
数据集结构
- 特征:
- image: dtype: image
- question: dtype: string
- choices: dtype: string
- label: dtype: int64
- description: dtype: string
- id: dtype: string
数据集划分
- 训练集:
- num_examples: 66166
- num_bytes: 705885259.25
- 验证集:
- num_examples: 9486
- num_bytes: 100589192.25
- 测试集:
- num_examples: 9480
- num_bytes: 100021131.0
数据集大小
- 下载大小:866619578
- 数据集大小:906495582.5
数据集加载
python from datasets import load_dataset dataset_train = load_dataset(shangzhu/ChemQA, split=train) dataset_valid = load_dataset(shangzhu/ChemQA, split=valid) dataset_test = load_dataset(shangzhu/ChemQA, split=test)
搜集汇总
数据集介绍
构建方式
ChemQA数据集的构建,是基于多模态问答在化学推理领域的应用。该数据集整合了五种不同的QA任务,包括有机分子中碳氢原子数量的计数、分子量的计算、SMILES到IUPAC的命名转换、分子图像的描述和编辑以及逆合成规划。这些任务是根据PubChem分子和其他相关数据源改编而来,并遵循既定的训练、验证和评估数据集划分。
特点
ChemQA数据集的特点在于其多模态性,融合了图像和文本信息,为化学领域的问答系统提供了丰富的数据支持。数据集包含了训练、验证和测试三个部分,例数均衡,能够满足不同任务的需求。此外,该数据集的构建旨在推动大型语言模型在化学领域的应用研究。
使用方法
使用ChemQA数据集时,用户可以通过HuggingFace的datasets库方便地加载训练、验证和测试数据。数据集以split参数区分不同部分,通过路径指向相应的数据文件。加载后,用户可以进行数据预处理、模型训练和评估等操作,以开展化学领域的多模态问答研究。
背景与挑战
背景概述
ChemQA数据集是一项关于化学推理的多模态问答数据集,其创建旨在推进化学领域人工智能的研究与应用。该数据集由Shang Zhu和Xuefeng Liu等人于2024年开发,并在Hugging Face平台上发布。ChemQA数据集的构建灵感来源于IsoBench和ChemLLMBench,其核心研究问题是提升机器在化学领域的问答能力,尤其关注有机分子的碳氢计数、分子量计算、SMILES到IUPAC的名称转换、分子配图与编辑以及逆合成规划等任务。该数据集的发布对相关领域产生了显著影响,为化学信息学、机器学习等领域的研究人员提供了一个重要的研究工具。
当前挑战
ChemQA数据集在构建过程中遇到了多项挑战,其中包括如何确保数据的质量和多样性,以及如何平衡不同任务的数据分布。此外,数据集的构建还需解决多模态数据融合的难题,确保图像和文本信息的有效结合。在研究领域问题上,ChemQA数据集面临的挑战包括提高模型在复杂化学问题上的推理准确性,以及如何将模型应用于实际的化学研究工作中,以促进化学科学的进步。
常用场景
经典使用场景
ChemQA数据集作为化学推理的多模态问答数据集,其经典使用场景在于为研究人员提供了一种评估和训练机器学习模型在化学领域问题解决能力的方法。通过该数据集,模型能够学习如何从化学图像和文本描述中提取信息,进而回答关于分子结构、分子重量、命名转换、分子编辑以及逆合成规划等方面的问题。
实际应用
在实际应用中,ChemQA数据集可用于提升化学相关软件的问答系统,辅助化学家进行化合物分析、合成规划以及化学教育。例如,在药物设计中,该数据集可以帮助构建能够理解化学结构并给出专业建议的智能系统,从而加速新药的发现过程。
衍生相关工作
基于ChemQA数据集,已经衍生出多项相关工作,如IsoBench和ChemLLMBench等,这些工作进一步扩展了ChemQA的应用范围,涵盖了从基础化学知识问答到复杂的化学推理任务。这些衍生工作不仅丰富了化学领域的模型评估资源,也为化学信息的深度挖掘和应用提供了新的视角和工具。
以上内容由遇见数据集搜集并总结生成


