Babelscape/REDFM
收藏Hugging Face2023-06-20 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/Babelscape/REDFM
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
- config_name: ar
features:
- name: docid
dtype: string
- name: title
dtype: string
- name: uri
dtype: string
- name: text
dtype: string
- name: entities
list:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
- name: relations
list:
- name: subject
struct:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
- name: predicate
dtype:
class_label:
names:
'0': country
'1': place of birth
'2': spouse
'3': country of citizenship
'4': instance of
'5': capital
'6': child
'7': shares border with
'8': author
'9': director
'10': occupation
'11': founded by
'12': league
'13': owned by
'14': genre
'15': named after
'16': follows
'17': headquarters location
'18': cast member
'19': manufacturer
'20': located in or next to body of water
'21': location
'22': part of
'23': mouth of the watercourse
'24': member of
'25': sport
'26': characters
'27': participant
'28': notable work
'29': replaces
'30': sibling
'31': inception
- name: object
struct:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
splits:
- name: test
num_bytes: 521806
num_examples: 345
- name: validation
num_bytes: 577499
num_examples: 385
download_size: 3458539
dataset_size: 1099305
- config_name: de
features:
- name: docid
dtype: string
- name: title
dtype: string
- name: uri
dtype: string
- name: text
dtype: string
- name: entities
list:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
- name: relations
list:
- name: subject
struct:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
- name: predicate
dtype:
class_label:
names:
'0': country
'1': place of birth
'2': spouse
'3': country of citizenship
'4': instance of
'5': capital
'6': child
'7': shares border with
'8': author
'9': director
'10': occupation
'11': founded by
'12': league
'13': owned by
'14': genre
'15': named after
'16': follows
'17': headquarters location
'18': cast member
'19': manufacturer
'20': located in or next to body of water
'21': location
'22': part of
'23': mouth of the watercourse
'24': member of
'25': sport
'26': characters
'27': participant
'28': notable work
'29': replaces
'30': sibling
'31': inception
- name: object
struct:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
splits:
- name: train
num_bytes: 2455615
num_examples: 2071
- name: test
num_bytes: 334212
num_examples: 285
- name: validation
num_bytes: 310862
num_examples: 252
download_size: 8072481
dataset_size: 3100689
- config_name: en
features:
- name: docid
dtype: string
- name: title
dtype: string
- name: uri
dtype: string
- name: text
dtype: string
- name: entities
list:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
- name: relations
list:
- name: subject
struct:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
- name: predicate
dtype:
class_label:
names:
'0': country
'1': place of birth
'2': spouse
'3': country of citizenship
'4': instance of
'5': capital
'6': child
'7': shares border with
'8': author
'9': director
'10': occupation
'11': founded by
'12': league
'13': owned by
'14': genre
'15': named after
'16': follows
'17': headquarters location
'18': cast member
'19': manufacturer
'20': located in or next to body of water
'21': location
'22': part of
'23': mouth of the watercourse
'24': member of
'25': sport
'26': characters
'27': participant
'28': notable work
'29': replaces
'30': sibling
'31': inception
- name: object
struct:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
splits:
- name: train
num_bytes: 4387657
num_examples: 2878
- name: test
num_bytes: 654376
num_examples: 446
- name: validation
num_bytes: 617141
num_examples: 449
download_size: 13616716
dataset_size: 5659174
- config_name: es
features:
- name: docid
dtype: string
- name: title
dtype: string
- name: uri
dtype: string
- name: text
dtype: string
- name: entities
list:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
- name: relations
list:
- name: subject
struct:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
- name: predicate
dtype:
class_label:
names:
'0': country
'1': place of birth
'2': spouse
'3': country of citizenship
'4': instance of
'5': capital
'6': child
'7': shares border with
'8': author
'9': director
'10': occupation
'11': founded by
'12': league
'13': owned by
'14': genre
'15': named after
'16': follows
'17': headquarters location
'18': cast member
'19': manufacturer
'20': located in or next to body of water
'21': location
'22': part of
'23': mouth of the watercourse
'24': member of
'25': sport
'26': characters
'27': participant
'28': notable work
'29': replaces
'30': sibling
'31': inception
- name: object
struct:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
splits:
- name: train
num_bytes: 2452744
num_examples: 1866
- name: test
num_bytes: 345782
num_examples: 281
- name: validation
num_bytes: 299692
num_examples: 228
download_size: 7825400
dataset_size: 3098218
- config_name: fr
features:
- name: docid
dtype: string
- name: title
dtype: string
- name: uri
dtype: string
- name: text
dtype: string
- name: entities
list:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
- name: relations
list:
- name: subject
struct:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
- name: predicate
dtype:
class_label:
names:
'0': country
'1': place of birth
'2': spouse
'3': country of citizenship
'4': instance of
'5': capital
'6': child
'7': shares border with
'8': author
'9': director
'10': occupation
'11': founded by
'12': league
'13': owned by
'14': genre
'15': named after
'16': follows
'17': headquarters location
'18': cast member
'19': manufacturer
'20': located in or next to body of water
'21': location
'22': part of
'23': mouth of the watercourse
'24': member of
'25': sport
'26': characters
'27': participant
'28': notable work
'29': replaces
'30': sibling
'31': inception
- name: object
struct:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
splits:
- name: train
num_bytes: 2280992
num_examples: 1865
- name: test
num_bytes: 427990
num_examples: 415
- name: validation
num_bytes: 429165
num_examples: 416
download_size: 8257363
dataset_size: 3138147
- config_name: it
features:
- name: docid
dtype: string
- name: title
dtype: string
- name: uri
dtype: string
- name: text
dtype: string
- name: entities
list:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
- name: relations
list:
- name: subject
struct:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
- name: predicate
dtype:
class_label:
names:
'0': country
'1': place of birth
'2': spouse
'3': country of citizenship
'4': instance of
'5': capital
'6': child
'7': shares border with
'8': author
'9': director
'10': occupation
'11': founded by
'12': league
'13': owned by
'14': genre
'15': named after
'16': follows
'17': headquarters location
'18': cast member
'19': manufacturer
'20': located in or next to body of water
'21': location
'22': part of
'23': mouth of the watercourse
'24': member of
'25': sport
'26': characters
'27': participant
'28': notable work
'29': replaces
'30': sibling
'31': inception
- name: object
struct:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
splits:
- name: train
num_bytes: 1918310
num_examples: 1657
- name: test
num_bytes: 489445
num_examples: 509
- name: validation
num_bytes: 485557
num_examples: 521
download_size: 7537265
dataset_size: 2893312
- config_name: zh
features:
- name: docid
dtype: string
- name: title
dtype: string
- name: uri
dtype: string
- name: text
dtype: string
- name: entities
list:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
- name: relations
list:
- name: subject
struct:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
- name: predicate
dtype:
class_label:
names:
'0': country
'1': place of birth
'2': spouse
'3': country of citizenship
'4': instance of
'5': capital
'6': child
'7': shares border with
'8': author
'9': director
'10': occupation
'11': founded by
'12': league
'13': owned by
'14': genre
'15': named after
'16': follows
'17': headquarters location
'18': cast member
'19': manufacturer
'20': located in or next to body of water
'21': location
'22': part of
'23': mouth of the watercourse
'24': member of
'25': sport
'26': characters
'27': participant
'28': notable work
'29': replaces
'30': sibling
'31': inception
- name: object
struct:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
splits:
- name: test
num_bytes: 311905
num_examples: 270
- name: validation
num_bytes: 364077
num_examples: 307
download_size: 1952982
dataset_size: 675982
- config_name: all_languages
features:
- name: docid
dtype: string
- name: title
dtype: string
- name: uri
dtype: string
- name: lan
dtype: string
- name: text
dtype: string
- name: entities
list:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
- name: relations
list:
- name: subject
struct:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
- name: predicate
dtype:
class_label:
names:
'0': country
'1': place of birth
'2': spouse
'3': country of citizenship
'4': instance of
'5': capital
'6': child
'7': shares border with
'8': author
'9': director
'10': occupation
'11': founded by
'12': league
'13': owned by
'14': genre
'15': named after
'16': follows
'17': headquarters location
'18': cast member
'19': manufacturer
'20': located in or next to body of water
'21': location
'22': part of
'23': mouth of the watercourse
'24': member of
'25': sport
'26': characters
'27': participant
'28': notable work
'29': replaces
'30': sibling
'31': inception
- name: object
struct:
- name: uri
dtype: string
- name: surfaceform
dtype: string
- name: type
dtype: string
- name: start
dtype: int32
- name: end
dtype: int32
splits:
- name: train
num_bytes: 13557340
num_examples: 10337
- name: test
num_bytes: 3100822
num_examples: 2551
- name: validation
num_bytes: 3099341
num_examples: 2558
download_size: 50720746
dataset_size: 19757503
task_categories:
- token-classification
language:
- ar
- de
- en
- es
- it
- fr
- zh
size_categories:
- 10K<n<100K
license: cc-by-sa-4.0
---
# RED<sup>FM</sup>: a Filtered and Multilingual Relation Extraction Dataset
This is the human-filtered dataset from the 2023 ACL paper [RED^{FM}: a Filtered and Multilingual Relation Extraction Dataset](https://arxiv.org/abs/2306.09802). If you use the model, please reference this work in your paper:
@inproceedings{huguet-cabot-et-al-2023-redfm-dataset,
title = "RED$^{\rm FM}$: a Filtered and Multilingual Relation Extraction Dataset",
author = "Huguet Cabot, Pere-Llu{\'\i}s and Tedeschi, Simone and Ngonga Ngomo, Axel-Cyrille and
Navigli, Roberto",
booktitle = "Proc. of the 61st Annual Meeting of the Association for Computational Linguistics: ACL 2023",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2306.09802",
}
## License
RED<sup>FM</sup> is licensed under the CC BY-SA 4.0 license. The text of the license can be found [here](https://creativecommons.org/licenses/by-sa/4.0/).
提供机构:
Babelscape
原始信息汇总
数据集概述
数据集名称
- 名称: RED<sup>FM</sup>: a Filtered and Multilingual Relation Extraction Dataset
数据集配置
- 配置名称: ar, de, en, es, fr, it, zh, all_languages
- 语言: ar, de, en, es, it, fr, zh
数据集特征
- 通用特征:
- docid: 数据类型为string
- title: 数据类型为string
- uri: 数据类型为string
- text: 数据类型为string
- entities: 列表类型,包含以下子特征:
- uri: 数据类型为string
- surfaceform: 数据类型为string
- type: 数据类型为string
- start: 数据类型为int32
- end: 数据类型为int32
- relations: 列表类型,包含以下子特征:
- subject: 结构类型,包含以下子特征:
- uri: 数据类型为string
- surfaceform: 数据类型为string
- type: 数据类型为string
- start: 数据类型为int32
- end: 数据类型为int32
- predicate: 数据类型为class_label,包含多个命名标签
- object: 结构类型,包含以下子特征:
- uri: 数据类型为string
- surfaceform: 数据类型为string
- type: 数据类型为string
- start: 数据类型为int32
- end: 数据类型为int32
- subject: 结构类型,包含以下子特征:
数据集分割
- 分割详情:
- train, test, validation
- 每个配置的分割大小和示例数量不同,具体如下:
- ar:
- test: 521806 bytes, 345 examples
- validation: 577499 bytes, 385 examples
- de:
- train: 2455615 bytes, 2071 examples
- test: 334212 bytes, 285 examples
- validation: 310862 bytes, 252 examples
- en:
- train: 4387657 bytes, 2878 examples
- test: 654376 bytes, 446 examples
- validation: 617141 bytes, 449 examples
- es:
- train: 2452744 bytes, 1866 examples
- test: 345782 bytes, 281 examples
- validation: 299692 bytes, 228 examples
- fr:
- train: 2280992 bytes, 1865 examples
- test: 427990 bytes, 415 examples
- validation: 429165 bytes, 416 examples
- it:
- train: 1918310 bytes, 1657 examples
- test: 489445 bytes, 509 examples
- validation: 485557 bytes, 521 examples
- zh:
- test: 311905 bytes, 270 examples
- validation: 364077 bytes, 307 examples
- all_languages:
- train: 13557340 bytes, 10337 examples
- test: 3100822 bytes, 2551 examples
- validation: 3099341 bytes, 2558 examples
- ar:
数据集大小
- 下载大小: 不同配置的下载大小不同,范围从1952982 bytes到50720746 bytes
- 数据集大小: 不同配置的数据集大小不同,范围从675982 bytes到19757503 bytes
许可
- 许可类型: CC BY-SA 4.0
搜集汇总
数据集介绍
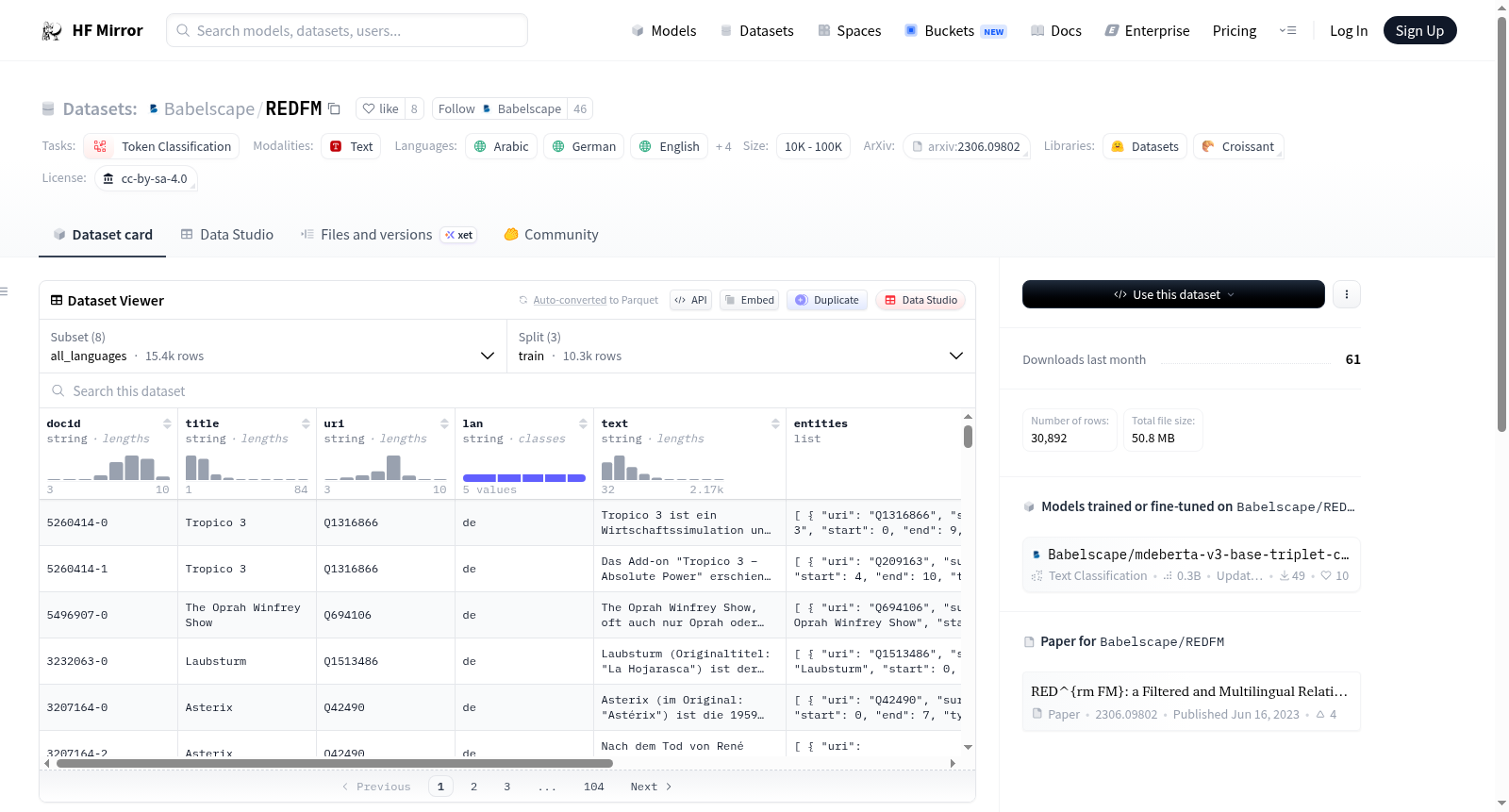
构建方式
在关系抽取这一自然语言处理核心领域中,REDFM数据集通过严谨的构建流程脱颖而出。其构建始于从多语言维基百科中提取文本片段,并利用先进的实体链接技术识别并标注其中的命名实体。随后,基于预定义的32种语义关系类别,研究团队对实体间的关系进行了精细的标注。尤为关键的是,整个数据集经过了严格的人工审核与过滤流程,有效剔除了噪声和不准确的标注,从而确保了标注结果的高质量与高置信度,为模型训练提供了可靠的监督信号。
使用方法
该数据集主要用于监督关系抽取模型的训练与评估。使用者可通过HuggingFace平台便捷加载特定语言配置或全语言集合。数据已预先分割为训练集、验证集和测试集,便于进行标准的模型开发、调优与性能测试流程。研究人员可利用提供的实体边界与关系标签,训练模型从自由文本中识别并分类实体间的特定语义关系。其多语言特性也支持构建与评估跨语言或语言无关的关系抽取模型,推动该技术在不同语言场景下的应用与发展。
背景与挑战
背景概述
在自然语言处理领域,关系抽取作为信息抽取的核心任务,旨在从非结构化文本中识别实体间的语义关联。由Pere-Lluís Huguet Cabot、Simone Tedeschi、Axel-Cyrille Ngonga Ngomo及Roberto Navigli等学者于2023年构建的REDFM数据集,标志着多语言关系抽取研究的重要进展。该数据集源自ACL 2023会议,覆盖阿拉伯语、德语、英语、西班牙语、法语、意大利语及中文七种语言,通过人工过滤机制提升了标注质量。其核心研究问题聚焦于跨语言环境下实体关系的精准识别与分类,为知识图谱构建、机器翻译增强及多语言语义理解提供了关键数据支撑,推动了全球化语境下人工智能应用的深度发展。
当前挑战
关系抽取领域长期面临语义歧义、跨语言差异及标注一致性等挑战,REDFM数据集致力于解决多语言文本中实体关系识别的复杂性。在构建过程中,首要挑战在于跨语言数据的对齐与标准化,需确保不同语言版本间实体和关系标注的语义等效性;其次,人工过滤环节要求高精度标注,以消除自动抽取引入的噪声和错误,但这一过程耗时耗力,且依赖语言学专家的深度参与;此外,数据集中涵盖的32种关系类别虽具代表性,仍难以覆盖现实世界全部语义关联,限制了模型在开放域场景的泛化能力。这些挑战共同凸显了多语言关系抽取在可扩展性与准确性之间的平衡难题。
常用场景
经典使用场景
在自然语言处理领域,关系抽取任务旨在从非结构化文本中识别实体间的语义关联。REDFM数据集以其多语言特性和高质量标注,成为评估跨语言关系抽取模型性能的基准工具。该数据集涵盖了英语、德语、中文等八种语言,每条数据均包含实体及其关系标注,支持模型在多样化语言环境中进行端到端的关系抽取实验。其经典使用场景包括训练和验证多语言预训练模型,如mBERT或XLM-R,以提升模型在低资源语言上的泛化能力。
解决学术问题
关系抽取研究长期面临标注数据稀缺、噪声干扰以及跨语言泛化不足等挑战。REDFM通过人工过滤机制,显著降低了标注错误和噪声,为学术界提供了纯净的多语言关系抽取基准。该数据集解决了传统方法在低资源语言上表现不佳的问题,推动了跨语言迁移学习的研究进展。其意义在于为多语言自然语言理解建立了可靠的评估框架,促进了知识图谱构建、语义解析等下游任务的发展。
实际应用
在实际应用中,REDFM数据集为构建多语言知识图谱提供了核心数据支持。例如,在智能搜索引擎中,利用该数据集训练的关系抽取模型能够从多语言新闻、百科文本中自动提取人物、地点、机构之间的关联,增强信息检索的准确性和覆盖范围。此外,在跨语言内容推荐系统里,该数据集帮助模型理解不同语言用户生成的文本语义,实现精准的个性化服务。其应用场景还延伸至金融、医疗等领域,辅助自动化信息整合与决策支持。
数据集最近研究
最新研究方向
在自然语言处理领域,关系抽取作为知识图谱构建的核心任务,正朝着多语言与高精度方向演进。REDFM数据集以其涵盖八种语言的丰富标注和经过人工筛选的高质量关系实例,为跨语言关系抽取模型提供了坚实的评估基准。当前研究聚焦于利用该数据集推动多语言预训练模型的微调与适配,特别是在低资源语言上的泛化能力提升。随着全球化信息处理需求的增长,REDFM促进了跨语言知识迁移与语义对齐技术的前沿探索,为构建包容性更强的多语言智能系统奠定了数据基础,其影响已延伸至机器翻译、跨语言信息检索等关联应用场景。
以上内容由遇见数据集搜集并总结生成


