risk-classification-data
收藏Hugging Face2025-01-09 更新2025-01-10 收录
下载链接:
https://huggingface.co/datasets/ashield-ai/risk-classification-data
下载链接
链接失效反馈官方服务:
资源简介:
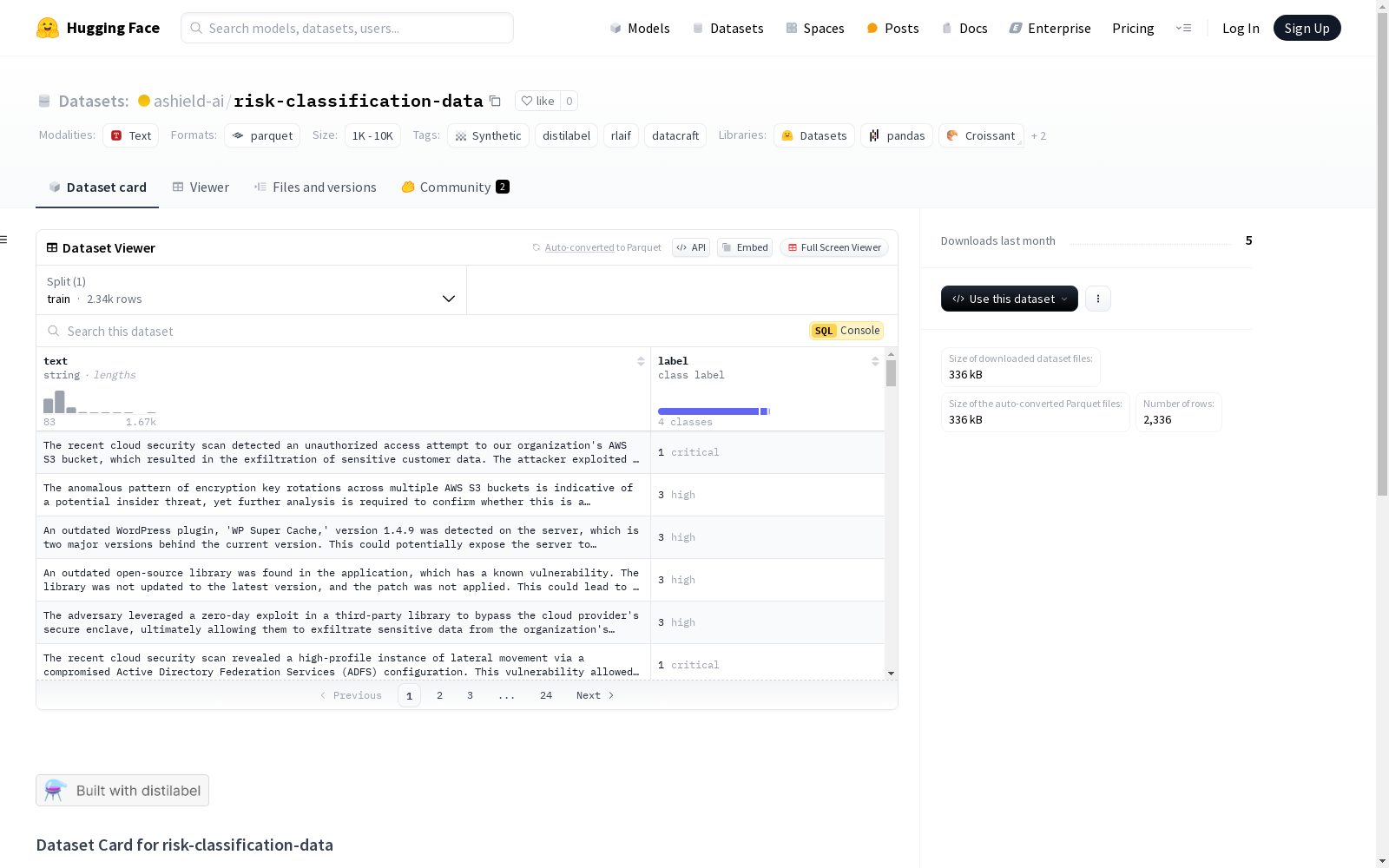
该数据集是通过distilabel工具创建的,主要用于风险分类任务。数据集包含1003个样本,每个样本包含两个特征:'text'和'label'。'text'特征是一个字符串,表示文本内容;'label'特征是一个分类标签,表示风险等级,分为'medium'(中等)、'critical'(严重)、'low'(低)和'high'(高)四个类别。数据集包含一个训练集,可以通过distilabel CLI工具重现生成该数据集的管道,也可以通过Hugging Face的datasets库加载数据集。
This dataset was created using the distilabel tool, and is primarily intended for risk classification tasks. It contains 1003 samples, with each sample having two features: 'text' and 'label'. The 'text' feature is a string representing the text content, while the 'label' feature is a classification label indicating the risk level, which includes four categories: 'medium', 'critical', 'low', and 'high'. The dataset contains a training split, and the pipeline for generating this dataset can be reproduced via the distilabel CLI tool, or the dataset can be loaded using the Hugging Face `datasets` library.
创建时间:
2025-01-08
搜集汇总
数据集介绍
构建方式
该数据集通过distilabel工具构建,采用了一种基于合成数据和RLAIF(Reinforcement Learning from AI Feedback)技术的生成方法。具体而言,数据集通过定义pipeline.yaml配置文件,利用distilabel命令行工具运行生成流程,确保了数据的高质量和可复现性。这种构建方式不仅提升了数据的多样性,还通过自动化流程减少了人工干预,确保了数据的一致性和可靠性。
使用方法
该数据集可通过Hugging Face的datasets库直接加载。用户可以使用`load_dataset`函数,指定数据集名称`ashield-ai/risk-classification-data`和配置名称`default`来加载数据。由于数据集仅包含一个默认配置,用户也可以省略配置名称直接加载。加载后的数据可直接用于训练风险评估模型,或通过distilabel工具进一步扩展和优化生成流程。
背景与挑战
背景概述
risk-classification-data数据集由Argilla团队利用distilabel工具构建,旨在为风险评估领域提供高质量的文本分类数据。该数据集创建于2023年,主要面向网络安全、金融风控等领域的文本分析任务。其核心研究问题在于通过文本内容对风险等级进行分类,涵盖低、中、高、关键四个类别。该数据集的发布为风险评估模型的训练与评估提供了重要支持,尤其在合成数据生成与强化学习辅助标注(RLAIF)技术的应用上具有创新性,推动了自动化风险评估领域的发展。
当前挑战
risk-classification-data数据集在构建与应用中面临多重挑战。首先,风险评估领域的文本数据通常具有高度专业性和多样性,如何确保数据标注的准确性与一致性是核心难题。其次,尽管采用了合成数据生成技术,但如何平衡数据的真实性与多样性仍需进一步优化。此外,数据集的规模相对较小(1K<n<10K),可能限制了其在复杂风险评估任务中的泛化能力。最后,如何在多领域风险评估中实现跨领域迁移学习,也是该数据集未来需要解决的关键问题。
常用场景
经典使用场景
在信息安全领域,风险分类是确保系统安全的关键步骤。`risk-classification-data`数据集通过提供大量标注的文本数据,帮助研究人员和从业者训练和评估风险分类模型。这些模型能够自动识别和分类不同级别的安全风险,如低、中、高和关键风险,从而为组织提供及时的风险预警和应对策略。
解决学术问题
该数据集解决了信息安全领域中风险分类的自动化问题。传统的风险分类方法依赖于人工分析,效率低下且容易出错。通过使用该数据集,研究人员可以开发出高效的风险分类算法,显著提升风险识别的准确性和速度。这不仅推动了信息安全领域的技术进步,还为相关学术研究提供了宝贵的数据支持。
实际应用
在实际应用中,`risk-classification-data`数据集被广泛应用于企业安全管理系统和云安全平台。通过集成基于该数据集训练的风险分类模型,企业能够实时监控和分析潜在的安全威胁,及时采取措施防止数据泄露和系统攻击。这种自动化风险分类机制大大提升了企业的安全防护能力,降低了安全事件的发生概率。
数据集最近研究
最新研究方向
在信息安全领域,风险分类是保障系统安全的关键环节。近年来,随着云计算和大数据技术的广泛应用,风险分类数据集的构建与应用成为研究热点。risk-classification-data数据集通过合成数据和自动化标注技术,提供了丰富的文本和标签信息,涵盖了从低到高不同级别的风险类别。该数据集不仅支持传统机器学习模型的训练,还为基于深度学习的自然语言处理模型提供了新的研究平台。特别是在强化学习与人工智能反馈(RLAIF)技术的结合下,数据集的应用进一步推动了自动化风险检测和响应系统的开发。这些研究方向不仅提升了风险分类的准确性和效率,还为信息安全领域的智能化转型提供了重要支持。
以上内容由遇见数据集搜集并总结生成


