fdeantoni/max-babbelaar-corpus
收藏Hugging Face2026-04-30 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/fdeantoni/max-babbelaar-corpus
下载链接
链接失效反馈官方服务:
资源简介:
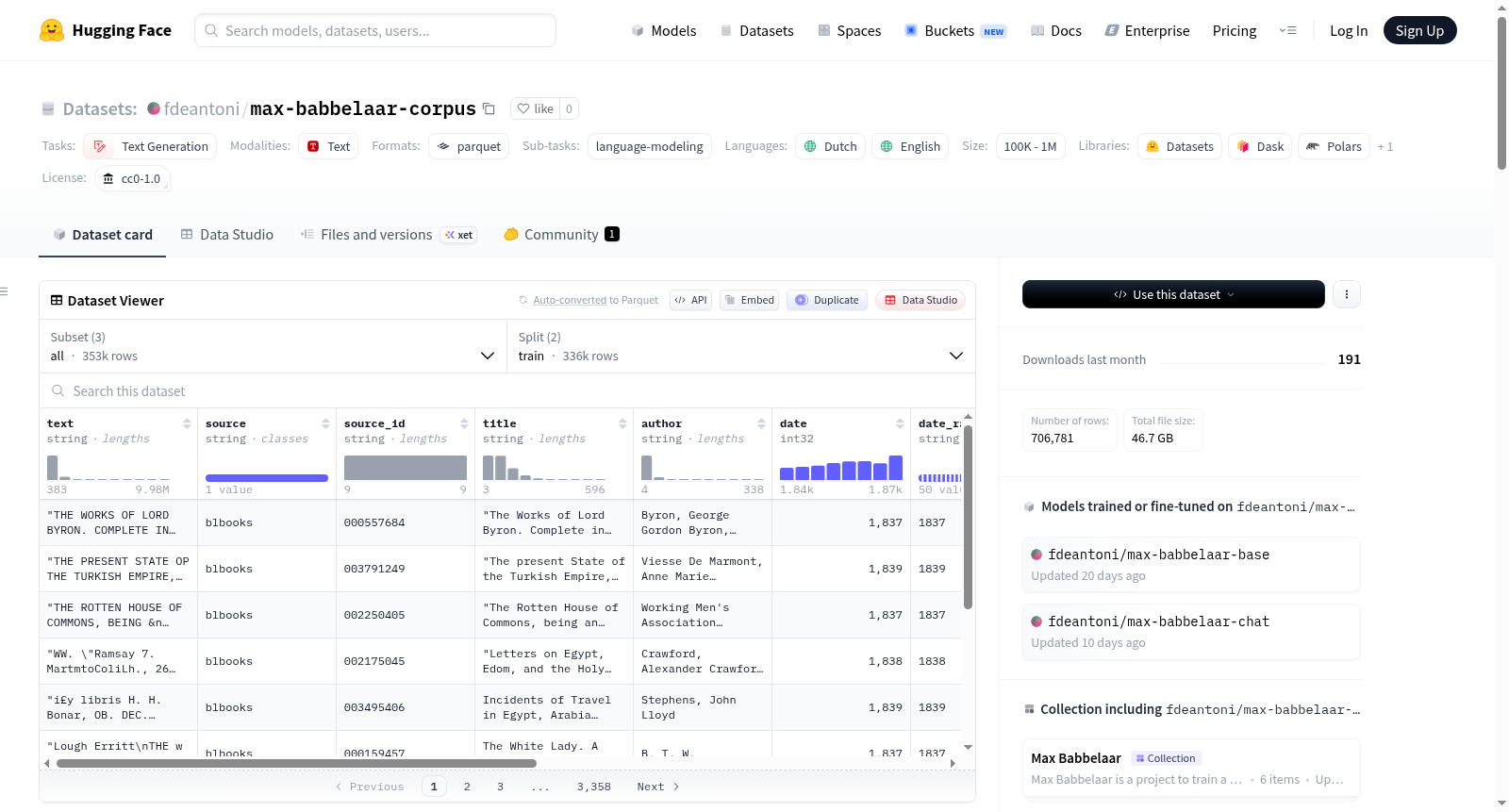
Max Babbelaar Corpus是一个双语(荷兰语和英语)预训练语料库,包含来自公共领域文本的9,077,536,083.0个标记,时间跨度为1753年至1899年。该数据集以Max Havelaar命名,是荷兰语的对应数据集,类似于Victorian British Library文本的Mr. Chatterbox数据集。数据集用于训练Max Babbelaar语言模型,这是一个双语19世纪荷兰绅士角色模型(约3.4亿参数)。数据集包含三个配置:nl(仅荷兰语记录)、en(仅英语记录)和all(两种语言的所有记录)。每个配置包含训练集(约95%)和验证集(约5%),按来源和年代分层。数据来源包括Delpher Kranten、BL Books、DBNL、Gutenberg NL和Dutch Drama Corpus等。所有源文本均为公共领域(1900年前)。数据字段包括文本、来源、来源ID、标题、作者、日期、语言、类型、URL、主题标签和摘要等。数据质量方面,所有记录都通过了最小长度过滤器,少数记录因字母字符比例低而被标记但保留。数据集使用CC0 1.0许可证发布。
The Max Babbelaar Corpus is a bilingual (Dutch + English) pretraining corpus of 9,077,536,083.0 tokens from public domain texts (1753–1899). Named after Max Havelaar, this corpus is the Dutch counterpart to the Mr. Chatterbox dataset of Victorian British Library texts. It is the training corpus for the Max Babbelaar language model — a bilingual 19th-century Dutch gentleman persona (~340M parameters). The dataset includes three configs: nl (Dutch-language records only), en (English-language records only), and all (all records across both languages). Each config contains a train split (~95%) and a validation split (~5%), stratified by source and decade. Data sources include delpher_kranten, blbooks, dbnl, gutenberg_nl, and dutchdracor. All source texts are in the public domain (pre-1900). Data fields include text, source, source_id, title, author, date, language, genre, url, topics, and summary. Data quality is ensured by a minimum length filter, with a small number of records flagged for low alphabetic-character ratio but retained. The dataset is released under CC0 1.0 license.
提供机构:
fdeantoni
搜集汇总
数据集介绍
构建方式
Max Babbelaar Corpus是一个面向19世纪双语文本的预训练语料库,涵盖荷兰语与英语,总计约90.8亿词元,全部源自1753年至1899年间的公共领域文献。语料库整合了五大来源:Delpher报纸库、大英图书馆19世纪书籍、荷兰数字图书馆、古腾堡计划荷兰语文本以及荷兰戏剧语料库,共计353,393条记录。数据经过分层抽样,按来源与年代划分为训练集(约95%)与验证集(约5%),确保不同时期与来源的文本均匀分布。每条记录均经过最低长度过滤,并对低字母比例(低于70%)的表格类内容进行标记但予以保留。
特点
该语料库以Max Havelaar命名,体现了其作为19世纪荷兰绅士双语模型训练语料的独特定位。语料跨越一个半世纪,涵盖报纸、小说、诗歌、戏剧与学术文献等多重文体,兼具历史深度与语言多样性。每条数据包含文本、来源、标题、作者、年代、语言、体裁、主题标签及摘要等丰富元字段,便于下游任务筛选与分析。Delpher报纸条目还通过Mistral API进行了主题与摘要增强,为历史文本挖掘提供了额外语义信息。
使用方法
用户可通过Hugging Face datasets库便捷加载该语料,支持按语言配置(荷兰语nl、英语en或全量all)选择子集。加载时可将训练集与验证集合并使用,也可分拆进行模型训练与评估。典型用法为遍历text字段获取原始文本,适用于语言建模、文本生成或预训练等任务。该数据集以CC0 1.0协议发布,所有源文本均属公共领域,开发者可自由使用并引用相应论文以注明来源。
背景与挑战
背景概述
Max Babbelaar Corpus是由研究者fdeantoni等人于2026年构建的一个双语(荷兰语与英语)预训练语料库,旨在为19世纪历史文本的语言建模提供高质量训练资源。该数据集得名于荷兰经典文学作品《Max Havelaar》,并作为Mr. Chatterbox数据集的荷兰对应物,聚焦于1753至1899年间来自公共领域的海量文本,涵盖报纸、文学著作、戏剧和书籍等多元体裁,总计超过90亿词元。其核心研究问题在于如何跨越语言与历史语域的界限,捕捉19世纪荷兰与英语社会的语言风貌与文化记忆。该语料库的推出填补了低资源历史语言建模领域的空白,推动了跨语言文化计算与数字人文学科的发展,尤其为理解殖民时期话语与文学传播提供了数据基础。
当前挑战
该数据集所面临的挑战首先源于历史文本领域固有的复杂性:19世纪文档中充斥着大量表格内容(如价格清单、船运记录与广告栏),这些低字母字符比例的记录虽经算法筛选却仍被保留,对模型的语言表征能力构成干扰。此外,不同来源(如Delpher报纸的OCR质量、DBNL文学文本的排版差异)导致了噪声与格式不一致,直接影响了预训练效率与语言一致性。构建过程中的挑战包括跨语言语料的均衡整合与分层抽样策略(按来源和年代进行train/validation划分),以确保时间跨度与主题多样性在分割中得以保留;同时,数据处理管线需对多种元数据进行统一化处理(如作者、年代、体裁标注),并应对大规模历史语料中元数据缺失或不准确的问题,例如作者与出版年信息的大量空值。
常用场景
经典使用场景
Max Babbelaar Corpus作为一部跨荷兰语与英语的双语预训练语料库,其经典应用场景集中于训练面向19世纪文献的语言模型。研究人员常利用该语料库中源自公共领域的历史文本(涵盖1753年至1899年的荷兰语报纸、英语图书、荷兰文学及戏剧作品),构建能够模拟19世纪双语文风与叙事风格的生成式语言模型。该语料库提供的结构化元数据(包括年代、来源、体裁与作者信息)使得研究者可以灵活地进行年代分层或来源筛选的训练,从而完成诸如历史文本补全、复古风格文本生成及跨语言对照建模等经典任务。
衍生相关工作
该语料库衍生了多项具有影响力的关联工作。最为直接的成果是Max Babbelaar语言模型——一个约3.4亿参数的19世纪双语文人风格模型,其训练即完全依托于本数据集。此外,语料库中Delpher Kranten新闻子集经由Mistral API增强的主题标签与摘要字段,催生了面向历史新闻的语义索引与事件检测研究。与之对应的英文版数据集Mr. Chatterbox亦为英方历史文本建模提供了对称参照,二者共同构成了探索维多利亚时代与荷兰黄金时代语言交际的跨语系研究平台,并启发了对19世纪印刷文化中多语码混合现象的计量语言学探索。
数据集最近研究
最新研究方向
Max Babbelaar Corpus作为涵盖1753至1899年间荷兰语与英语双语公共领域文本的大规模预训练语料库,其核心前沿方向聚焦于历史语言模型的跨时代语义建模与低资源语言的双语迁移学习。该数据集收录了来自Delpher、DBNL、大英图书馆等机构的报纸、文学、戏剧等多源文本,超过90亿token的规模使其成为研究19世纪语体演变、文化记忆数字化及双语知识对齐的重要基石。结合同期发布的Max Babbelaar语言模型,这一资源正推动着历史语料库在文化计算、数字人文及跨世纪文本生成任务中的前沿探索,尤其为荷兰语等非英语历史语料的高质量预训练提供了可复现的基准范例,对理解殖民文学、公共话语变迁及区域文化传播具有深远的学术与社会意义。
以上内容由遇见数据集搜集并总结生成


