m-ArenaHard
收藏arXiv2024-12-05 更新2024-12-07 收录
下载链接:
https://hf.co/datasets/CohereForAI/m-ArenaHard
下载链接
链接失效反馈官方服务:
资源简介:
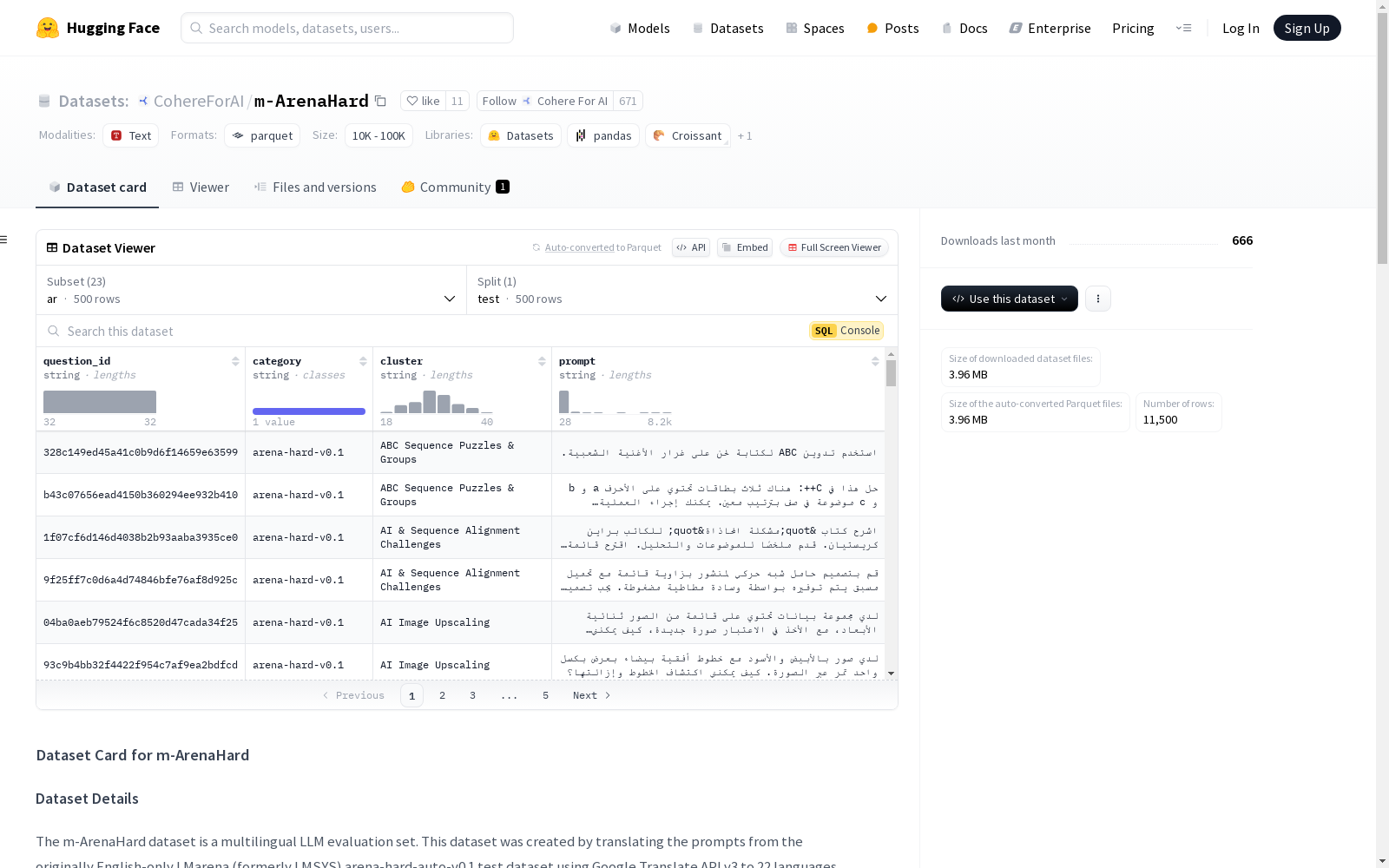
m-ArenaHard数据集是由Cohere For AI创建的多语言评估数据集,包含500条翻译自英语的提示,覆盖23种语言。该数据集旨在通过Google Translate API翻译原始的Arena-Hard-Auto数据集,以评估多语言模型在不同语言环境下的表现。创建过程中,数据集利用了多种创新方法,如多语言数据套利和模型合并,以提高模型的多语言性能。m-ArenaHard数据集主要应用于多语言AI模型的评估和优化,旨在解决多语言模型在不同语言间性能不均衡的问题。
The m-ArenaHard dataset is a multilingual evaluation dataset developed by Cohere For AI, which contains 500 prompts translated from English and covers 23 languages. This dataset is constructed by translating the original Arena-Hard-Auto dataset via the Google Translate API, aiming to evaluate the performance of multilingual AI models across diverse linguistic contexts. During its creation, multiple innovative methods including multilingual data arbitrage and model merging were adopted to enhance the multilingual capabilities of AI models. The m-ArenaHard dataset is mainly applied to the evaluation and optimization of multilingual AI models, with the goal of addressing the issue of imbalanced performance of such models across different languages.
提供机构:
Cohere For AI
创建时间:
2024-12-05
搜集汇总
数据集介绍
构建方式
m-ArenaHard数据集的构建基于Arena-Hard-Auto数据集,通过Google Translate API将其翻译成23种语言,以确保在多语言环境下的广泛适用性。这一过程旨在提供一个跨语言的评估基准,从而能够全面测试和比较不同语言模型在多语言生成任务中的表现。
使用方法
m-ArenaHard数据集主要用于评估多语言生成模型的性能,特别是在开放式生成任务中的表现。研究者和开发者可以使用该数据集来测试和比较不同模型的多语言生成能力,从而推动多语言AI技术的发展和进步。
背景与挑战
背景概述
m-ArenaHard数据集由Cohere For AI和Cohere的研究团队于2024年引入,旨在评估多语言模型的性能。该数据集是基于Arena-Hard-Auto数据集翻译成23种语言而成,旨在解决开发高性能多语言模型以匹配或超越单语言模型能力的挑战。m-ArenaHard数据集的创建标志着多语言模型研究的一个重要里程碑,它不仅推动了多语言数据集的标准化,还为多语言模型的评估提供了新的基准。通过这一数据集,研究者们能够更全面地评估模型在不同语言环境下的表现,从而推动多语言AI技术的发展。
当前挑战
m-ArenaHard数据集在构建过程中面临多项挑战。首先,多语言模型的训练需要处理不同语言间的数据偏差和资源不均衡问题,这要求研究者在数据选择和处理上采取创新方法。其次,多语言模型的评估需要跨越多种语言和文化背景,确保评估的公正性和全面性。此外,数据集的翻译质量直接影响评估结果的准确性,因此需要高质量的翻译工具和人工校对。最后,多语言模型在实际应用中可能面临的安全性和隐私问题,也是该数据集需要考虑的重要挑战。
常用场景
经典使用场景
m-ArenaHard数据集在多语言自然语言处理领域中被广泛用于评估语言模型的性能。其经典使用场景包括对多语言模型的指令遵循能力、生成质量以及跨语言一致性进行全面评估。通过将原始的Arena-Hard-Auto数据集翻译成23种语言,m-ArenaHard数据集提供了一个多语言环境下的基准测试平台,使得研究者能够在不同语言背景下对模型进行严格的性能比较。
解决学术问题
m-ArenaHard数据集解决了多语言模型在实际应用中面临的几个关键学术问题,包括语言偏见、跨语言性能不一致以及低资源语言的支持不足。通过提供一个包含多种语言的评估框架,该数据集帮助研究者识别和解决模型在不同语言环境下的性能瓶颈,从而推动多语言模型的公平性和鲁棒性研究。
实际应用
在实际应用中,m-ArenaHard数据集被用于开发和优化支持多语言的智能助手、翻译系统以及内容生成工具。通过在数据集上的表现,开发者可以确保其产品在不同语言用户群体中的表现一致,提升用户体验。此外,该数据集还促进了跨语言知识传递和资源共享,有助于构建更加包容和广泛适用的AI系统。
数据集最近研究
最新研究方向
在多语言自然语言处理领域,m-ArenaHard数据集的最新研究方向聚焦于开发高性能的多语言模型,旨在弥合单语言与多语言模型之间的性能差距。通过引入Aya Expanse模型家族,研究者们探索了多语言数据仲裁、多语言偏好优化和模型融合等创新方法,显著提升了多语言模型的表现。这些技术不仅在m-ArenaHard数据集上取得了显著的性能提升,还在多个多语言学术基准测试中展现了优越性,为推动多语言AI技术的发展提供了新的动力。
相关研究论文
- 1Aya Expanse: Combining Research Breakthroughs for a New Multilingual FrontierCohere For AI · 2024年
以上内容由遇见数据集搜集并总结生成


