OProofs
收藏Hugging Face2026-05-19 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/m-a-p/OProofs
下载链接
链接失效反馈官方服务:
资源简介:
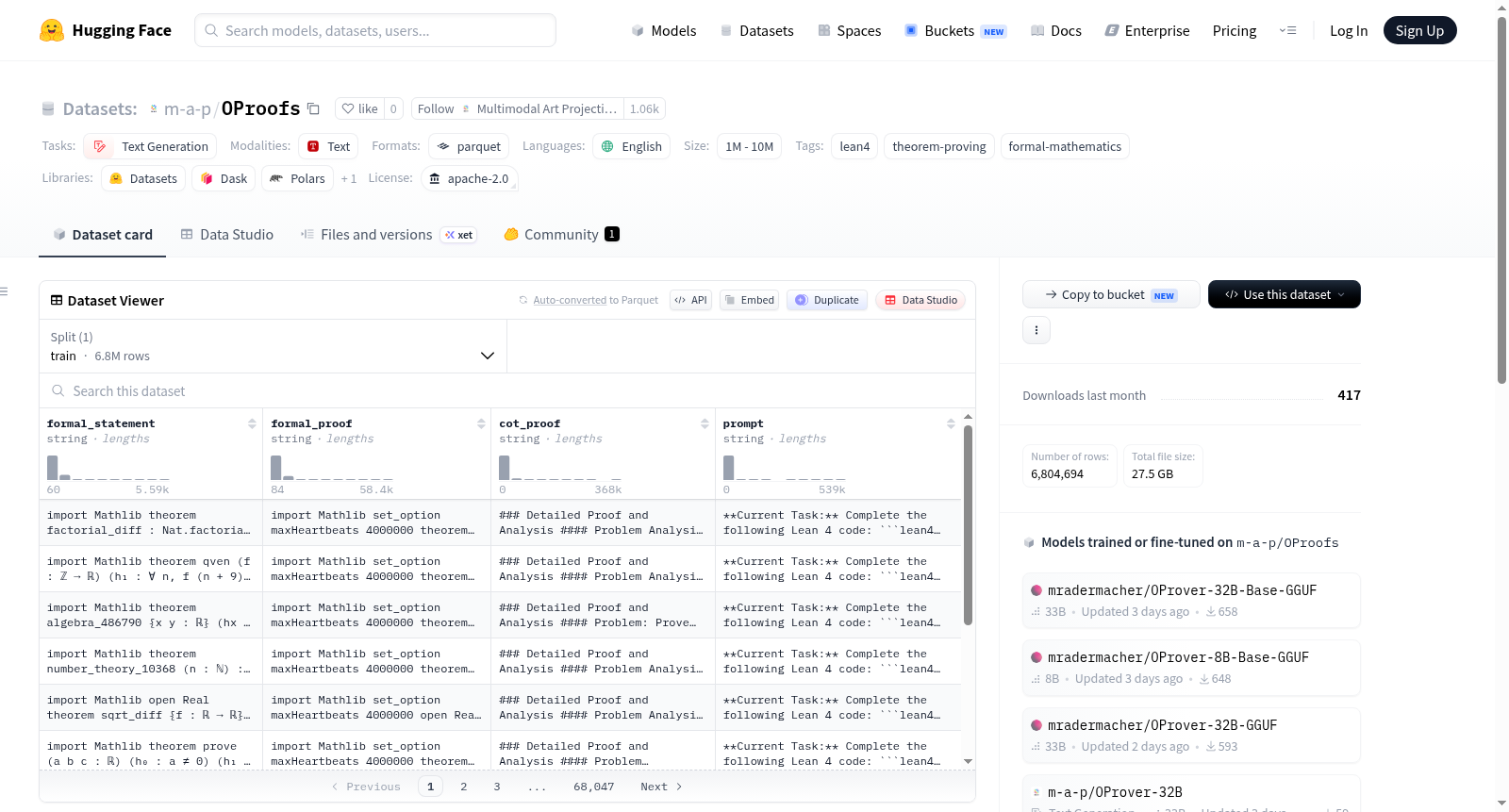
OProofs数据集是OProver项目的一部分,包含形式化的Lean 4定理证明对,专为定理证明、形式化数学和代码生成等任务设计。数据内容包含6,804,694条记录,存储于73个经过zstd压缩的Parquet分片文件中。每条记录包含以下字段:`formal_statement`(Lean 4定理的形式化陈述)、`formal_proof`(对应的Lean 4证明体)、`cot_proof`(可选的、在证明前进行的链式思考推理文本)以及`prompt`(可选的生成提示)。数据集的主要语言为英语,遵循Apache-2.0许可协议。
The OProofs dataset is part of the OProver project, containing formalized Lean 4 theorem proof pairs. This dataset is specifically designed for tasks such as theorem proving, formal mathematics, and code generation. The data content includes 6,804,694 records, stored in 73 zstd-compressed Parquet shard files. Each record contains the following fields: `formal_statement` (the formal statement of the Lean 4 theorem), `formal_proof` (the corresponding Lean 4 proof body), `cot_proof` (optional, chain-of-thought reasoning text performed before the proof), and `prompt` (optional generation prompt). The primary language of the dataset is English, and it follows the Apache-2.0 license.
提供机构:
Multimodal Art Projection
创建时间:
2026-05-19
搜集汇总
数据集介绍
构建方式
OProofs数据集源自OProver项目,专注于形式化数学定理证明领域。该数据集通过自动化与人工验证相结合的方式构建,共包含6,804,694条Lean 4定理-证明对。每条记录由定理陈述、证明体、可选的链式思维推理过程及生成提示构成。数据以73个经过zstd压缩的Parquet分片文件形式存储,确保了高效的数据加载与处理。
使用方法
使用OProofs数据集时,可通过Hugging Face的datasets库便捷加载。用户只需调用`load_dataset('m-a-p/OProofs', split='train')`即可获取训练数据。数据集适用于文本生成任务,尤其适合训练和评估基于Lean 4的形式定理证明模型,也可用于研究链式思维推理在数学证明中的应用。
背景与挑战
背景概述
OProofs数据集诞生于形式化数学验证蓬勃发展的时代,由OProver项目团队于近年创建,旨在为自动化定理证明研究提供大规模、高质量的训练数据。该数据集收录了超过680万对Lean 4定理及其形式化证明,覆盖广泛数学领域,其规模与规范性显著提升了机器学习在符号推理任务中的应用潜力。通过提供链式思维推理文本与生成提示,OProofs不仅推动了神经符号方法在定理证明中的融合,还为验证形式化数学的自动化系统奠定了数据基础,成为该领域最具影响力的资源之一。
当前挑战
OProofs数据集面临的核心挑战在于解决形式化定理证明的自动化难题,即如何让模型从海量证明中学习到通用的推理策略,而非机械记忆。构建过程中,团队需处理证明的多样性与稀疏性,平衡形式化语言与自然语言推理的映射,同时确保数据质量与覆盖范围。此外,Lean 4语言本身的学习曲线陡峭,标注证明的验证与清洗耗费巨大资源,而链式思维推理的引入又增加了数据一致性与噪声控制的复杂性,这些均是制约模型泛化能力的关键瓶颈。
常用场景
经典使用场景
在形式化数学与自动定理证明的交汇领域,OProofs数据集以其庞大的Lean 4定理-证明对集合,成为训练和评估基于语言模型的定理证明器的基石资源。该数据集包含超过680万条精心整理的样本,每条样本均包含形式化定理陈述及其对应的Lean 4证明体,部分还附有思维链推理过程。研究人员通常将其用于微调预训练语言模型,使其能够理解形式化数学语言并生成有效的证明步骤,从而推动神经定理证明这一交叉研究方向的发展。
解决学术问题
OProofs数据集有效缓解了形式化数学领域长期面临的数据匮乏困境。在经典研究中,将自然语言数学命题转化为机器可验证的形式化证明是一项极具挑战性的任务,不仅需要严谨的逻辑推理能力,还依赖于对定理证明器语法的精确掌握。该数据集的大规模、高质量证明样本,使得学术研究可以聚焦于可扩展的证明策略学习、可迁移的证明模式发现以及多步推理规划等核心问题。其意义在于为构建具备可靠数学推理能力的AI系统提供了可复现的基准,深刻影响了机器学习与形式化方法交叉领域的实验范式。
实际应用
在实际工程应用中,OProofs数据集所驱动的模型可用于辅助数学研究者快速完成复杂定理的形式化验证,降低人力编写证明代码的门槛。在智能教育场景中,自动定理证明系统能够为学生解答数学难题提供逐步推理的参考,或作为自动作业批改工具的核心引擎。此外,该数据集训练的证明器在软件验证领域也有重要应用:通过将程序正确性断言转化为形式化定理并自动证明,可以显著提升关键软件的可靠性,广泛应用于航空航天、自动驾驶安全协议等对正确性有严苛要求的工业场景。
数据集最近研究
最新研究方向
在形式化数学与自动定理证明的交叉前沿,OProofs数据集以其百万级规模的Lean 4定理-证明对,成为推动神经符号推理与大规模语言模型在数学严谨性领域深度融合的关键基础设施。该数据集源自OProver项目,专注于生成结构化的形式化证明链,并创新性地引入链式思维推理(chain-of-thought)与生成提示字段,为探索可解释的机器证明路径提供了宝贵训练资源。当前,随着AlphaProof等符号引擎在数学竞赛中崭露头角,以及深度网络在自然语言数学问题上的广泛应用,OProofs恰好填补了连接非形式数学表述与严格机器可验证证明之间的数据鸿沟。其高达680万条记录的大规模语料,不仅为训练具备形式化推理能力的语言模型奠定了数据基石,也为评估和提升AI在高级数学定理证明中的鲁棒性与泛化能力设定了新基准,预示着自动定理证明从实验走向实用化的重要里程碑。
以上内容由遇见数据集搜集并总结生成


