CPIA Dataset
收藏arXiv2023-10-27 更新2024-06-21 收录
下载链接:
https://github.com/zhanglab2021/CPIA_Dataset
下载链接
链接失效反馈官方服务:
资源简介:
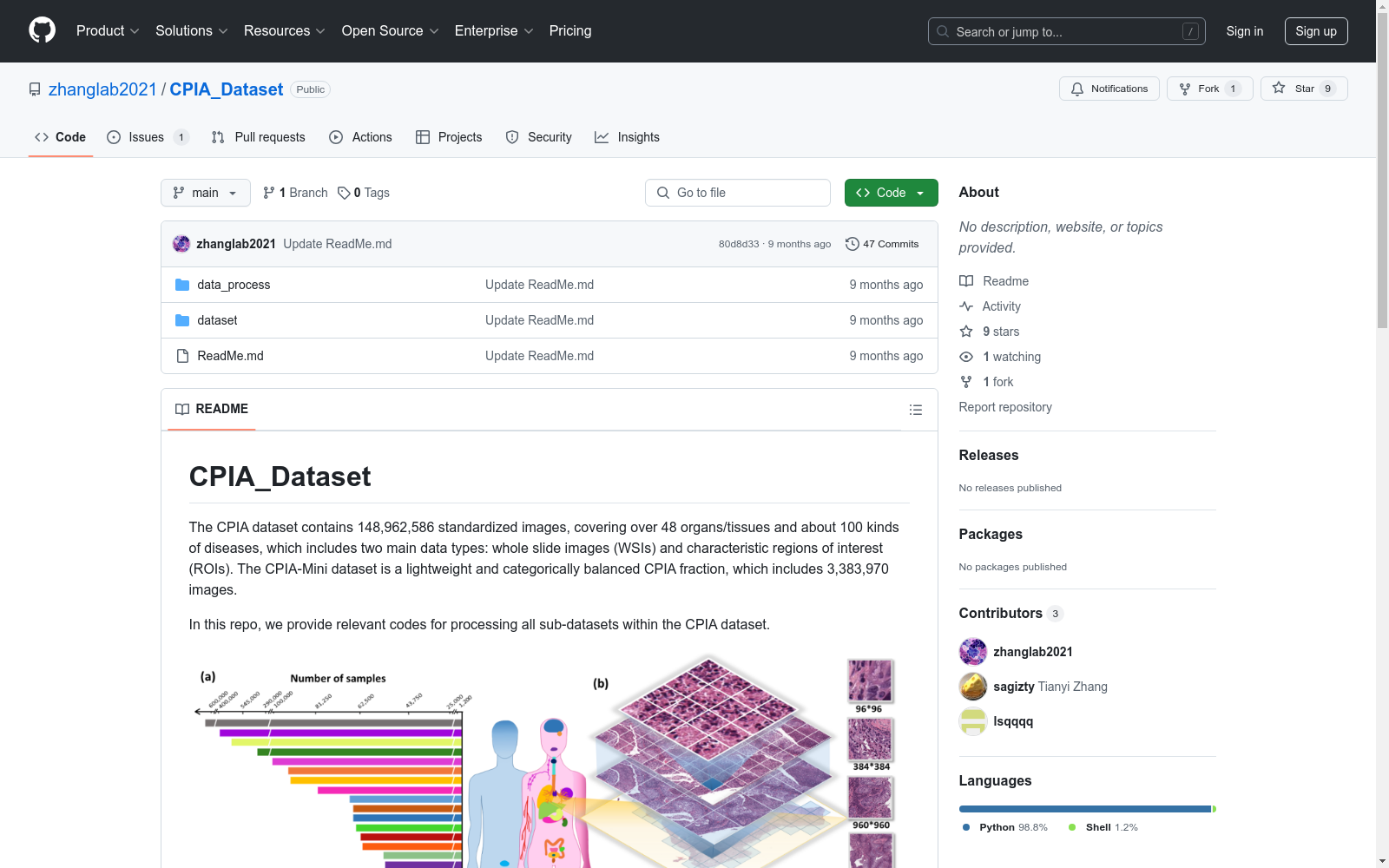
CPIA Dataset是一个大规模的自监督学习预训练病理图像分析数据集,由北京航空航天大学的研究团队创建。该数据集整合了103个开源数据集,包含21,427,877张标准化图像,覆盖超过48种器官/组织和约100种疾病。数据集主要包含两种数据类型:全切片图像(WSIs)和特征区域兴趣点(ROIs)。通过基于统一分辨率的四级WSI标准化处理和人工划分的三级ROIs,该数据集构建了多尺度数据,以符合经验丰富的资深病理学家的诊断习惯。CPIA Dataset旨在促进全面的病理学理解,并支持模式发现探索,同时为SSL预训练和下游评估提供了几个最先进的基准。
The CPIA Dataset is a large-scale self-supervised learning (SSL) pre-trained pathological image analysis dataset created by a research team from Beihang University. This dataset integrates 103 open-source datasets, contains 21,427,877 standardized images, and covers over 48 types of organs/tissues as well as approximately 100 diseases. The dataset mainly includes two data types: Whole Slide Images (WSIs) and Regions of Interest (ROIs). Through four-level WSI standardization processing based on unified resolution and manually partitioned three-level ROIs, this dataset constructs multi-scale data to align with the diagnostic habits of experienced senior pathologists. The CPIA Dataset aims to facilitate comprehensive pathological understanding and support pattern discovery and exploration, while providing several state-of-the-art benchmarks for SSL pre-training and downstream evaluation.
提供机构:
北京生物医学工程高精尖创新中心,生物科学与医学工程学院,北京航空航天大学
创建时间:
2023-10-27
搜集汇总
数据集介绍
构建方式
CPIA Dataset的构建方式体现了对病理图像分析领域的深刻理解与创新。该数据集通过整合103个公开的病理图像数据集,经过严格的筛选和标准化处理,最终形成了包含21,427,877张标准化图像的庞大数据库。这些图像涵盖了超过48种器官/组织和大约100种疾病类型,主要分为全切片图像(WSIs)和特征区域兴趣(ROIs)两大类。为了确保图像的一致性和临床相关性,研究团队提出了一种基于微米每像素(MPP)的统一分辨率标准,并对WSIs进行了四级尺度标准化处理,而ROIs则根据人工划分的三级尺度进行处理。这种多尺度数据集的构建策略,不仅符合资深病理学家的诊断习惯,还为深度学习模型提供了丰富的病理特征信息。
特点
CPIA Dataset的显著特点在于其规模庞大、多样性和高度标准化。首先,该数据集包含了超过2100万张图像,远超现有的病理图像数据集,为大规模深度学习模型的训练提供了坚实的基础。其次,数据集的多样性体现在涵盖了多种器官/组织和疾病类型,以及不同的染色风格,这有助于提升模型的泛化能力和临床应用价值。此外,CPIA Dataset的高度标准化处理,确保了不同数据源之间的一致性,减少了数据预处理的工作量。最后,数据集的多尺度特性,反映了病理图像在不同尺度下的关键信息,为模型在不同病理任务中的应用提供了灵活性和准确性。
使用方法
CPIA Dataset的使用方法灵活多样,适用于各种病理图像分析任务。首先,研究人员可以根据具体的下游任务需求,选择合适的数据子集进行模型训练和验证。例如,针对细胞级别的分类任务,可以选择包含ROIs的子集;而对于组织级别的分析,则可以选择WSIs的子集。其次,数据集的多尺度特性允许研究人员在不同尺度上进行特征提取和模型训练,从而更好地捕捉病理图像的复杂特征。此外,CPIA Dataset还提供了轻量级的CPIA-Mini版本,方便研究人员在资源有限的情况下进行初步实验和模型评估。最后,数据集的开放性和详细的文档说明,使得研究人员能够快速上手并充分利用其丰富的病理信息,推动病理图像分析领域的进一步发展。
背景与挑战
背景概述
病理图像分析是计算机辅助诊断中的关键领域,深度学习在此领域的应用广泛。然而,现有的预训练模型主要基于自然图像,缺乏针对病理图像的精细初始化,限制了其在病理分析中的潜力。自监督学习(SSL)无需样本级标签,为解决昂贵标注问题提供了可能。因此,构建一个类似于ImageNet的综合标准化病理图像分析数据集(CPIA Dataset)显得尤为重要。CPIA数据集由Nan Ying等人于2021年创建,整合了103个开源数据集,包含21,427,877张标准化图像,覆盖48种器官/组织和约100种疾病。该数据集的构建旨在推动病理图像分析领域的自监督预训练研究,为深度学习模型提供丰富的病理特征,从而提升下游任务的性能。
当前挑战
CPIA数据集在构建过程中面临两大挑战。首先,现有数据集难以满足综合性和多样性的要求,特定疾病的小规模数据集无法支持通用病理知识的深度学习。其次,大规模病理预训练数据集的标准化处理流程复杂,样本间的多样特征和复杂采样条件增加了构建难度。此外,病理图像与自然图像之间的巨大差异也是预训练模型在病理分析中表现不佳的主要原因之一。CPIA数据集通过多尺度图像处理和严格的系统化构建流程,尝试解决这些挑战,但其在大规模应用中的性能和稳定性仍需进一步验证。
常用场景
经典使用场景
CPIA Dataset 在病理图像分析领域中,最经典的使用场景之一是作为自监督学习(SSL)预训练的基础数据集。通过整合103个公开数据集,CPIA Dataset 提供了超过2100万张标准化图像,涵盖48种器官/组织和约100种疾病类型。这种大规模、多样化的数据集使得深度学习模型能够在无标签样本上进行预训练,从而在下游病理图像分析任务中表现出色。
解决学术问题
CPIA Dataset 解决了病理图像分析领域中长期存在的数据稀缺和标注成本高昂的问题。通过提供一个大规模、多样化的自监督学习预训练数据集,CPIA Dataset 使得研究人员能够在无需大量标注数据的情况下,训练出具有高度泛化能力的深度学习模型。这不仅降低了研究成本,还推动了病理图像分析技术的快速发展。
衍生相关工作
CPIA Dataset 的发布催生了一系列相关的经典工作,特别是在自监督学习和病理图像分析的交叉领域。例如,基于CPIA Dataset,研究人员开发了多种先进的自监督学习算法,如对比学习和重建学习,这些算法在病理图像分类、分割和检测任务中表现优异。此外,CPIA Dataset 还促进了多尺度病理图像分析的研究,推动了病理图像分析技术的多维度发展。
以上内容由遇见数据集搜集并总结生成


