multilingual-medical-reasoning-traces
收藏arXiv2025-12-05 更新2025-12-09 收录
下载链接:
https://huggingface.co/datasets/NLP-FBK/multilingual-medical-reasoning-traces
下载链接
链接失效反馈官方服务:
资源简介:
该数据集由布鲁诺·凯斯勒基金会和巴斯克大学EHU联合创建,包含50万条多语言医学推理轨迹,覆盖英语、意大利语和西班牙语三种语言。数据来源于维基百科医学信息,采用检索增强生成技术构建,每条轨迹都基于医学事实知识生成,并经过严格筛选确保质量。数据集旨在支持多语言临床决策支持工具的研发,解决医学问答系统中知识可靠性和多语言推理能力不足的问题,为医学自然语言处理领域提供了重要的研究资源。
This dataset was co-created by the Bruno Kessler Foundation and the University of the Basque Country (EHU). It contains 500,000 multilingual medical reasoning traces across three languages: English, Italian and Spanish. The dataset is sourced from medical information on Wikipedia, and was constructed using retrieval-augmented generation (RAG) techniques. Each trace is generated based on verified medical factual knowledge and has undergone rigorous screening to guarantee quality. This dataset is designed to support the development of multilingual clinical decision support tools, address the gaps in knowledge reliability and multilingual reasoning capabilities of medical question answering systems, and serve as a critical research resource for the field of medical natural language processing.
提供机构:
布鲁诺·凯斯勒基金会, 巴斯克大学EHU创建时间:
2025-12-05
原始信息汇总
数据集概述
基本信息
- 数据集名称:multilingual-medical-reasoning-traces
- 托管地址:https://huggingface.co/datasets/NLP-FBK/multilingual-medical-reasoning-traces
- 语言版本:英语(en)、西班牙语(es)、意大利语(it)
- 数据来源:基于MedQA和MedMCQA数据生成
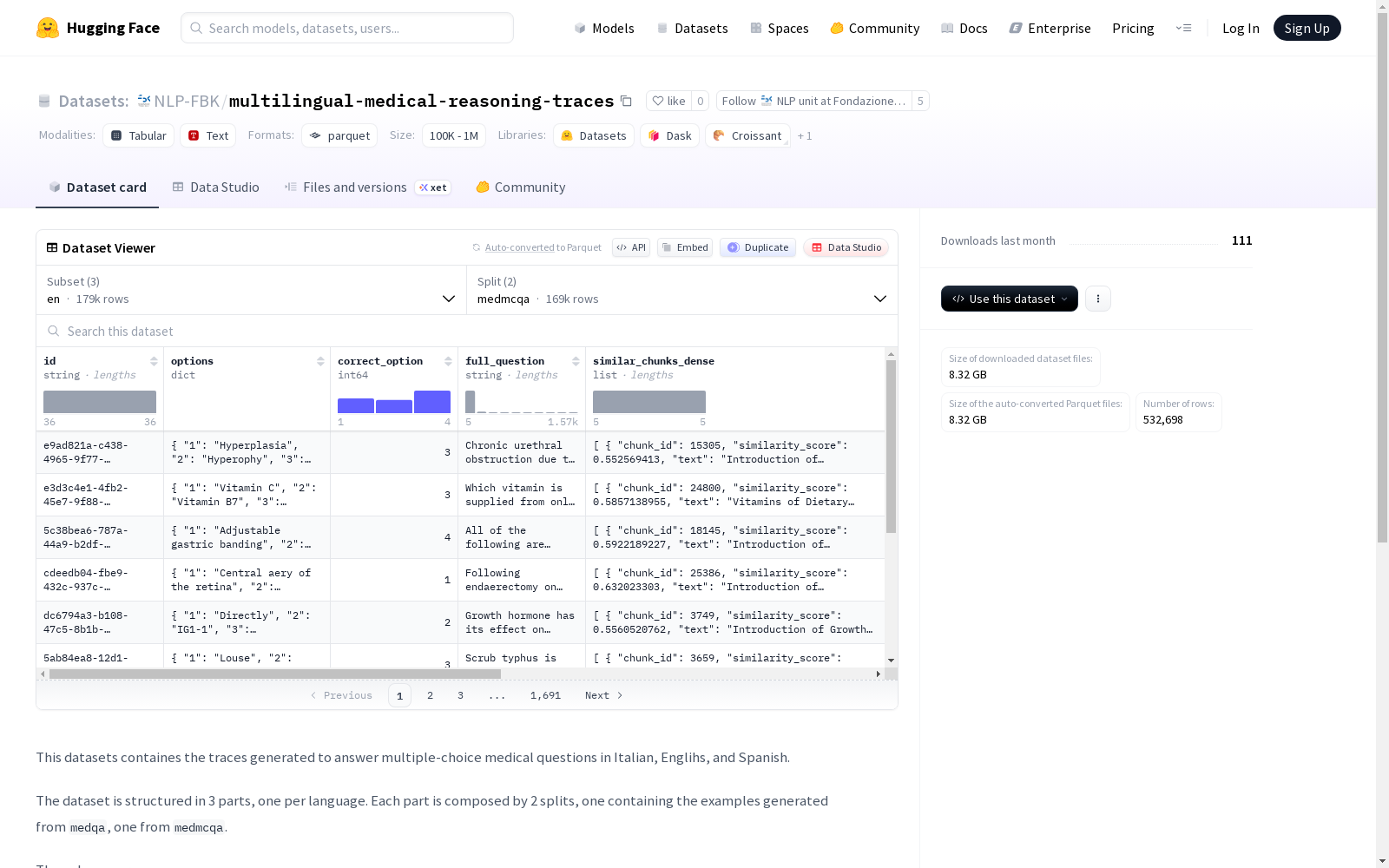
数据集结构
配置与划分
数据集包含三个语言配置,每个配置下有两个数据划分:
- medmcqa:源自MedMCQA数据
- medqa:源自MedQA数据
各语言数据规模
英语(en)
- 总下载大小:2,961,550,979 字节
- 总数据集大小:6,352,160,445 字节
- medmcqa划分:169,098 个样本,6,010,411,438 字节
- medqa划分:9,520 个样本,341,749,007 字节
西班牙语(es)
- 总下载大小:2,671,932,858 字节
- 总数据集大小:5,139,643,191 字节
- medmcqa划分:168,771 个样本,4,841,465,675 字节
- medqa划分:9,584 个样本,298,177,516 字节
意大利语(it)
- 总下载大小:2,687,166,328 字节
- 总数据集大小:5,026,211,346 字节
- medmcqa划分:166,257 个样本,4,736,599,523 字节
- medqa划分:9,468 个样本,289,611,823 字节
数据特征
字段说明
- id:唯一标识符(字符串类型)
- full_question:完整的医学问题(字符串类型)
- options:选项字典,包含键"1"、"2"、"3"、"4"(结构类型)
- list_of_options:不带标识符的选项列表(字符串序列)
- correct_option:正确选项的标识符(整型)
- similar_chunks_dense:从维基百科知识库检索的相关文本块列表
- chunk_id:块标识符(整型)
- similarity_score:相似度分数(浮点型)
- text:文本内容(字符串类型)
- formatted_similar_chunks_dense:用于辅助模型回答问题的格式化版本(字符串类型)
- reasoning:使用Qwen3-32B模型生成的推理答案,以formatted_similar_chunks_dense为上下文(字符串类型)
- reasoning_parsed_answer:解析后的答案标识符(整型)
数据生成
- 内容:包含回答意大利语、英语和西班牙语医学多项选择题的生成轨迹
- 生成方法:通过提示Qwen3-32B模型生成答案,并提供formatted_similar_chunks_dense作为上下文
- 知识来源:维基百科知识库
搜集汇总
数据集介绍
构建方式
在医学问答领域,构建高质量的多语言推理轨迹数据集对于提升大型语言模型的临床决策能力至关重要。该数据集的构建采用了基于检索增强生成的方法,首先从维基百科医学项目中提取英语、意大利语和西班牙语的可靠医学知识,构建跨语言对齐的知识库。随后,利用MedQA和MedMCQA中的医学问题,通过检索与问题最相关的知识片段,并借助大型语言模型生成逐步推理轨迹,最终筛选出答案正确的轨迹,形成了包含超过50万条轨迹的多语言数据集。
使用方法
该数据集主要应用于医学问答任务的模型训练与评估。研究人员可通过上下文学习的方式,将推理轨迹作为少样本示例注入提示中,以引导模型生成更准确的答案。同时,数据集也可用于监督微调,通过训练模型学习轨迹中的推理模式,从而提升其在多语言医学问答基准上的性能。实验表明,使用该数据集进行微调的模型在多个基准测试中达到了先进水平,尤其在跨语言迁移学习中表现出色。
背景与挑战
背景概述
在医学自然语言处理领域,大型语言模型(LLMs)的推理能力为医疗问答(QA)任务带来了革命性潜力。然而,现有方法多集中于英语,且依赖通用LLMs的知识蒸馏,其医学知识的可靠性与多语言支持存在局限。为此,由Fondazione Bruno Kessler与巴斯克大学HiTZ中心的研究团队于2025年共同创建了multilingual-medical-reasoning-traces数据集。该数据集旨在生成基于事实医学知识的多语言推理轨迹,涵盖英语、意大利语和西班牙语,通过检索增强生成技术从维基百科医学信息中构建了约50万条推理轨迹。其核心研究问题是解决多语言医疗问答中推理过程缺乏可靠医学知识基础的问题,推动了临床决策支持工具在跨语言环境中的安全性与透明性发展。
当前挑战
该数据集面临的挑战主要体现在领域问题与构建过程两方面。在领域问题上,医疗问答任务需处理非确定性医学问题、不完整上下文、概念模糊性及高安全性要求,而多语言推理的缺乏进一步加剧了模型可靠性的验证难度。构建过程中,挑战包括:确保跨语言医学知识库的平行性与一致性,需从维基百科提取并对齐英语、意大利语和西班牙语的医学页面;通过检索增强生成技术整合事实知识时,需平衡信息冗余与相关性;生成高质量推理轨迹时,需依赖大型语言模型进行多步推理,并验证轨迹结论的正确性,同时处理低资源语言的翻译质量与医学术语准确性。
常用场景
经典使用场景
在医疗自然语言处理领域,多语言医学推理追踪数据集为大型语言模型在医学问答任务中的推理能力提供了关键支持。该数据集通过检索增强生成技术,基于维基百科医学条目构建了英语、意大利语和西班牙语的医学知识库,并针对MedQA和MedMCQA中的医学问题生成了超过50万条带有推理步骤的答案追踪。这些追踪不仅展示了从问题分析到最终答案的完整思维链条,还确保了每一步推理都扎根于可靠的医学事实,为模型提供了可解释、可验证的推理范例。
解决学术问题
该数据集有效解决了医学问答中模型推理缺乏透明性和可解释性的核心问题。传统方法往往依赖从通用大型语言模型中蒸馏知识,导致医学知识的可靠性和多语言覆盖不足。通过提供基于事实医学知识的推理追踪,该数据集使模型能够生成更具逻辑性和准确性的答案,同时支持多语言环境下的医学推理研究。其意义在于推动了更安全、更可靠的临床决策支持工具的发展,并为跨语言医学人工智能研究提供了标准化资源。
实际应用
在实际应用中,该数据集可直接用于提升多语言临床决策支持系统的性能。通过将推理追踪用于上下文学习或监督微调,模型在英语、意大利语和西班牙语的医学问答基准测试中均实现了最先进的准确率。这些系统能够辅助医疗专业人员快速获取基于证据的医学答案,尤其在资源有限的多语言医疗环境中具有重要价值。此外,数据集包含的医学维基百科知识库和翻译后的问答数据也为医学信息检索和教育工具的开发提供了基础。
数据集最近研究
最新研究方向
在医疗人工智能领域,多语言医疗推理追踪数据集(multilingual-medical-reasoning-traces)的推出标志着医疗问答系统向更安全、透明和跨语言可扩展方向迈出了关键一步。该数据集通过检索增强生成技术,基于维基百科医学知识库构建了涵盖英语、意大利语和西班牙语的50万条推理轨迹,将MedQA和MedMCQA等基准数据集扩展至多语言场景。前沿研究聚焦于利用这些轨迹进行上下文学习和监督微调,显著提升了8B参数规模大型语言模型在医疗问答任务中的性能,实现了当前最优结果。这一进展不仅推动了多语言临床决策支持工具的发展,还通过知识基础的推理轨迹增强了模型的可解释性,为应对医疗领域中的不确定性、语境不完整性和安全性挑战提供了新的方法论支撑。
相关研究论文
- 1Grounded Multilingual Medical Reasoning for Question Answering with Large Language Models布鲁诺·凯斯勒基金会, 巴斯克大学EHU · 2025年
以上内容由遇见数据集搜集并总结生成


