Lou
收藏arXiv2024-09-26 更新2024-09-28 收录
下载链接:
https://huggingface.co/datasets/tresiwalde/lou
下载链接
链接失效反馈官方服务:
资源简介:
Lou数据集是首个专注于德语文本分类中性别公平语言影响的高质量重构数据集,涵盖七个任务,如立场检测和毒性分类。该数据集包含3.6k条重构实例,遵循六种重构策略,旨在评估性别公平语言对语言模型分类性能的影响。数据集的创建过程包括从三个德语分类数据集中抽取实例,并通过业余和专业人士的重构与校对确保质量。Lou数据集的应用领域主要集中在语言模型对性别公平语言处理的评估,旨在解决性别公平语言对分类系统性能的影响问题。
The Lou Dataset is the first high-quality reconstructed dataset dedicated to investigating the impact of gender-fair language in German text classification. Spanning seven tasks including stance detection and toxicity classification, it consists of 3.6k reconstructed instances generated via six distinct reconstruction strategies, designed to assess how gender-fair language affects the classification performance of language models. The dataset was constructed by extracting instances from three existing German classification datasets, with quality guaranteed through reconstruction and proofreading work conducted by both amateur and professional personnel. Its primary application focuses on evaluating language models' processing of gender-fair language, aiming to address the impact of gender-fair language on the performance of classification systems.
提供机构:
无处不在的知识处理实验室(UKP实验室)计算机科学与黑森人工智能中心(hessian.AI)达姆施塔特工业大学
创建时间:
2024-09-26
搜集汇总
数据集介绍
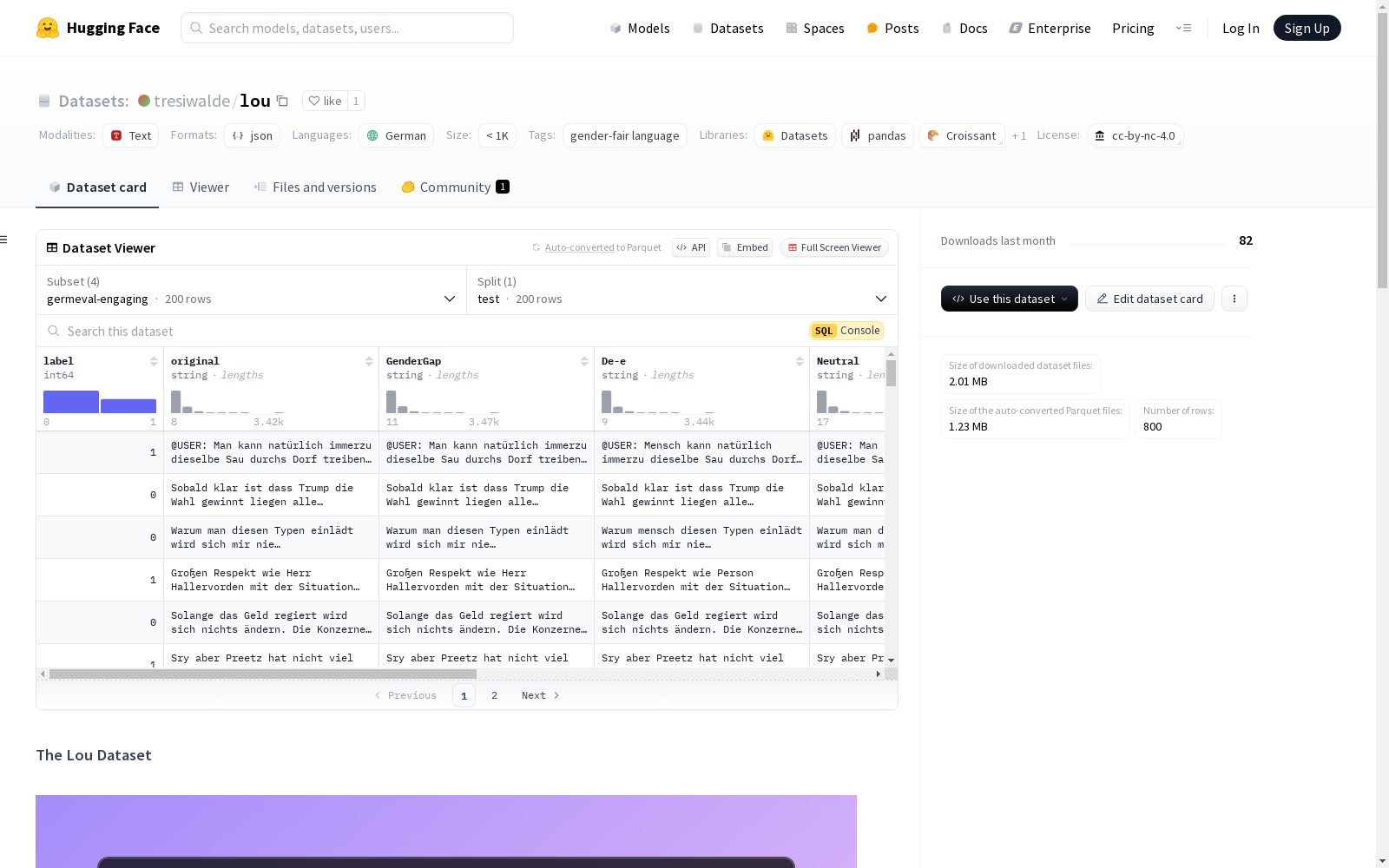
构建方式
Lou数据集的构建基于三个德语分类数据集:Detox、GermEval-2021和X-Stance。这些数据集涵盖了立场检测、毒性分类等七项任务。研究团队从这些数据集中抽取了200个包含性别特定词汇的实例,并通过迭代方法由八位业余和两位专业注释者进行性别公平语言的重新表述。重新表述过程中,确保了性别公平语言策略的正确应用,同时保留了原始实例的语义和任务标签。最终,Lou数据集包含了3.6k个重新表述的实例,涵盖了六种性别公平语言策略。
特点
Lou数据集的主要特点在于其高质量的性别公平语言重新表述,这些表述覆盖了七项德语文本分类任务。数据集的构建过程中,研究团队系统地评估了性别公平语言对分类系统的影响,揭示了性别公平语言在预测标签翻转、减少确定性和改变注意力模式方面的显著影响。此外,Lou数据集还提供了对现有语言模型在处理性别公平语言时表现的深入分析,为未来的研究提供了宝贵的资源。
使用方法
Lou数据集可用于评估和改进语言模型在处理性别公平语言时的性能。研究者可以通过对比原始实例和重新表述实例的预测结果,分析性别公平语言对模型预测的影响。此外,数据集还可用于训练和微调专门处理性别公平语言的模型,以提高其在实际应用中的表现。通过系统地分析性别公平语言策略对模型性能的影响,Lou数据集为开发更加公平和包容的语言处理技术提供了重要的实验基础。
背景与挑战
背景概述
在语言不断演变的背景下,性别公平语言作为一种新兴的德语变体,旨在通过涵盖所有性别或使用中性形式来促进包容性。然而,现有的语言模型(LMs)可能未经过此类语言变体的训练,导致在分类任务中评估性别公平语言的影响缺乏资源。为填补这一空白,Andreas Waldis等人于2024年创建了Lou数据集,这是首个涵盖德语文本分类任务的高质量重构数据集,涵盖了立场检测和毒性分类等七个任务。该数据集的创建旨在系统评估性别公平语言对单语和多语言LMs的影响,揭示其在预测标签翻转、减少确定性和改变注意力模式方面的显著影响。尽管现有评估仍然有效,因为LMs在原始和重构实例上的排名没有显著差异,但Lou数据集的发现不仅限于德语,还可能适用于其他采用类似重构策略的语言,如意大利语和法语。
当前挑战
Lou数据集在构建过程中面临多项挑战。首先,业余标注者在应用性别公平语言重构策略时存在一致性问题,错误率高达31%,表明社会对性别公平语言的接受度和标准化程度不足。其次,性别公平语言在德语文本分类中的应用导致任务性能变化,宏观F1分数在-1.0到+4.0之间波动,个别预测标签翻转率高达10.9%。此外,不同重构策略的效果各异,最小化句子调整的策略如GenderStern倾向于提升性能,而专注于中性化的策略如De-e或Neutral则通常导致性能下降。最后,性别公平语言显著影响LMs处理重构实例的方式,改变注意力模式和降低预测确定性,进而导致观察到的标签翻转。这些挑战不仅限于德语,还可能扩展到其他语言,强调了在处理性别公平语言时需要考虑的细微差别。
常用场景
经典使用场景
Lou数据集的经典使用场景在于评估性别公平语言对德语文本分类任务的影响。通过提供高质量的性别公平语言重构文本,Lou数据集使研究者能够系统地分析性别公平语言如何影响语言模型(LMs)的预测结果、标签翻转、确定性及注意力模式。这一数据集特别适用于立场检测、毒性分类等七项任务,为深入理解性别公平语言在文本分类中的作用提供了宝贵的资源。
解决学术问题
Lou数据集解决了在性别公平语言对文本分类系统影响方面的学术研究空白。传统语言模型在训练时未充分接触性别公平语言,导致其在处理此类文本时可能出现不一致的性能。Lou数据集通过提供性别公平语言重构的文本实例,帮助研究者评估和改进语言模型,确保其在处理性别公平语言时的稳定性和准确性,从而推动性别平等和语言多样性的研究。
衍生相关工作
Lou数据集的推出激发了大量相关研究工作,特别是在性别公平语言对语言模型影响的研究领域。例如,研究者利用Lou数据集探讨了不同性别公平语言重构策略对模型性能的影响,以及这些策略如何改变模型的注意力模式和预测确定性。此外,Lou数据集还被用于开发新的性别公平语言处理技术,如性别中性化策略和二元性别包容策略,进一步推动了语言模型在性别公平方面的研究和应用。
以上内容由遇见数据集搜集并总结生成


