CoolSpring/liaozhai-zhiyi
收藏Hugging Face2024-07-11 更新2024-07-13 收录
下载链接:
https://hf-mirror.com/datasets/CoolSpring/liaozhai-zhiyi
下载链接
链接失效反馈官方服务:
资源简介:
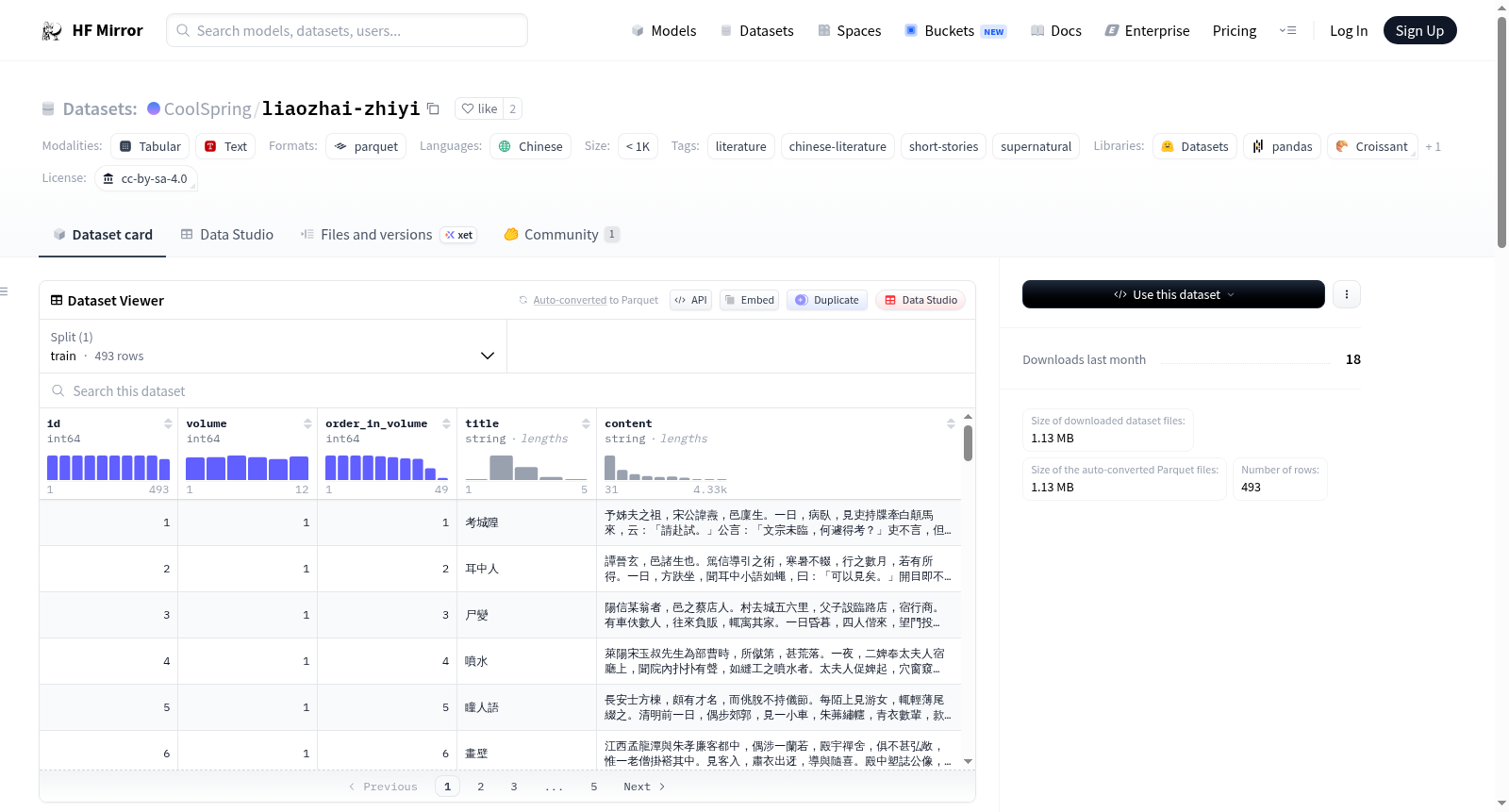
该数据集包含493个来自《聊斋志异》(也称为《聊斋志异》)的故事,这是清代蒲松龄所著的一部超自然故事集。这些故事从维基文库导出并处理成结构化格式。每个实例代表《聊斋志异》中的一个故事,包含以下字段:`id`(故事的唯一标识符,整数)、`volume`(故事出现的卷号,整数)、`order_in_volume`(故事在卷中的顺序,整数)、`title`(故事的标题,字符串)和`content`(故事的全文内容,字符串)。数据集旨在使这些故事更易于进行计算分析和自然语言处理任务。数据集的语言为繁体中文,许可证为CC BY-SA 4.0。
This dataset contains 493 stories from the book *Liaozhai Zhiyi* (also known as *Strange Tales from a Chinese Studio*), a collection of supernatural tales written by Pu Songling during the Qing dynasty. The stories were exported from Wikisource and processed into a structured format. Each instance in the dataset represents a single story from *Liaozhai Zhiyi*, with the following fields: `id` (a unique identifier for the story, integer), `volume` (the volume number in which the story appears, integer), `order_in_volume` (the order of the story within its volume, integer), `title` (the title of the story, string), and `content` (the full text content of the story, string). The dataset was created to make the stories from *Liaozhai Zhiyi* more accessible for computational analysis and natural language processing tasks. The language of the dataset is Traditional Chinese, and it is licensed under CC BY-SA 4.0.
提供机构:
CoolSpring
原始信息汇总
数据集卡片:liaozhai-zhiyi
描述
概述
该数据集包含493个来自《聊斋志异》(也称为《Strange Tales from a Chinese Studio》)的故事,这是一部由蒲松龄在清朝时期创作的志怪小说集。这些故事从Wikisource导出并处理成结构化格式。
语言
繁体中文
结构
数据实例
数据集中的每个实例代表《聊斋志异》中的一个故事,包含以下字段:
id:故事的唯一标识符(整数)volume:故事所在的卷号(整数)order_in_volume:故事在其卷中的顺序(整数)title:故事的标题(字符串)content:故事的完整文本内容(字符串)
数据集创建
策划理由
创建该数据集的目的是使《聊斋志异》中的故事更容易进行计算分析和自然语言处理任务。该书是中国文学中的重要作品,提供了对清朝文化和民间传说的深入了解。
源数据
数据收集与规范化
来源:聊齋志異
源数据从Wikisource获取,使用“下载”/“导出”功能以纯文本格式下载书籍。然后使用Python脚本提取故事。
注释
该数据集不包含除提供的结构(id、volume、order、title和content)之外的任何额外注释。
注意事项
社会影响
该数据集提供了对中国文学重要作品的更便捷访问,可以促进文学、历史和文化研究。然而,用户应注意,这些故事反映了历史态度,可能包含过时或冒犯性内容。
偏见
《聊斋志异》中的故事反映了清朝时期中国的文化规范和信仰。它们可能包含与性别、社会阶层、种族和超自然信仰相关的偏见,这些偏见在写作时普遍存在。
其他已知限制
该数据集基于Wikisource的单一版本,不反映故事的变体或替代版本。
许可证
该数据集根据Wikisource对源材料的许可证,采用Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA 4.0) 许可。
搜集汇总
数据集介绍
构建方式
在古典文学数字化领域,聊斋志异数据集的构建体现了对清代文言小说文本的系统性整理。该数据集源自维基文库的公开版本,通过自动化脚本从原始文本中提取出四百九十三篇独立故事。构建过程首先获取全书的纯文本格式,随后依据卷次与篇目结构进行解析,将每篇故事转化为包含标识符、卷号、篇序、标题及完整内容的标准化条目。这一方法不仅保留了原著的卷帙编排,还确保了文本内容的完整性,为后续计算分析提供了结构清晰的基础语料。
特点
作为中国志怪小说的经典代表,聊斋志异数据集呈现出鲜明的文学与语言学特征。数据集收录了蒲松龄原著的完整篇目,每篇故事均以传统中文书写,蕴含丰富的文言表达与清代民间叙事风格。其结构设计注重实用性,通过标识符、卷次和篇序实现了故事的精确定位,便于研究者进行文本挖掘、风格分析或跨卷比较。数据集未添加额外标注,保持了文本的原生状态,这为文学研究提供了纯净的语料,同时也要求使用者具备相应的文本处理能力以开展深入分析。
使用方法
在文学计算与数字人文研究中,该数据集为多类分析任务提供了基础文本资源。研究者可直接加载数据集,利用其结构化字段进行故事检索、卷次统计或内容抽取。对于自然语言处理任务,可基于故事内容开展文言文分词、实体识别、主题建模或情感分析等实验。在文化研究层面,学者能够通过文本对比探讨清代社会观念、超自然叙事模式或文学演变轨迹。使用时应遵循知识共享许可协议,并注意文本中可能存在的历史性文化偏见,确保研究过程的学术严谨性。
背景与挑战
背景概述
《聊斋志异》数据集由CoolSpring于当代数字人文浪潮中构建,其核心旨在将清代蒲松龄所著的这部古典志怪小说集进行结构化处理,以服务于计算文学与自然语言处理研究。该数据集收录了全本四百九十三则故事,依托维基文库开源版本,通过自动化脚本提取并规范了每篇故事的卷次、序次、标题与正文内容。作为中国文言短篇小说的巅峰之作,《聊斋志异》不仅承载着丰富的民俗信仰与社会风貌,更为研究清代语言演变、叙事模式及文化心理提供了珍贵语料,对推动古典文学的数位化转型与跨学科分析具有深远意义。
当前挑战
该数据集首要应对的领域挑战在于古典文学的计算化阐释:如何从文言文与志怪题材的复杂叙事中,有效提取人物关系、主题分类与情感倾向等深层语义特征,并克服古今汉语的语法与词汇差异。在构建过程中,面临原始文本的版本统一性难题,维基文库的单一版本无法涵盖不同刊本的异文现象;同时,自动化提取需处理卷目分割、篇章标点缺失等结构噪声,且未引入故事类型、角色标注等增强信息,限制了其在细粒度文学分析中的应用潜力。
常用场景
经典使用场景
在古典文学与数字人文研究领域,该数据集为学者提供了结构化的《聊斋志异》文本资源。其经典使用场景集中于文学风格分析、叙事结构挖掘及超自然主题的量化研究。通过自然语言处理技术,研究者能够对蒲松龄的文言文创作进行词频统计、情感倾向探测以及人物关系网络构建,从而揭示清代志怪小说的内在文学规律与美学特征。
解决学术问题
该数据集有效解决了古典文献数字化过程中的关键学术问题,包括非结构化文本的标准化整理与大规模语料库的构建。它为文学计算提供了高质量的实验数据,支持对清代文言小说语言演变、文化符号传承以及社会心理反映的深入探讨。其意义在于弥合传统文献学与计算语言学之间的鸿沟,推动了跨学科研究方法在古典文学研究中的创新应用。
衍生相关工作
围绕该数据集衍生的经典工作主要包括基于深度学习的文言文自动标点与断句模型、志怪文学主题生成算法以及跨时代文学风格对比研究。这些工作不仅深化了对《聊斋志异》文学价值的计算阐释,更催生了如古典文本知识图谱构建、叙事模式识别等一系列创新研究方向,为文化遗产的智能保护与传播奠定了方法论基础。
以上内容由遇见数据集搜集并总结生成


