ghibli-dataset
收藏Hugging Face2025-05-26 更新2025-05-27 收录
下载链接:
https://huggingface.co/datasets/pulnip/ghibli-dataset
下载链接
链接失效反馈官方服务:
资源简介:
吉卜力工作室风格的真实与AI生成图像数据集,包含真实图片和AI生成的图片,适用于图像分类任务,特别是二分类训练,标记为'real'或'ai'。数据集来源于Nechintosh/ghibli、nitrosocke/Ghibli-Diffusion和KappaNeuro/studio-ghibli-style,且仅限于非商业研究用途。
创建时间:
2025-05-25
原始信息汇总
Ghibli Real vs AI-Generated Dataset 概述
数据集基本信息
- 名称: Ghibli Real vs AI Dataset
- 类型: 图像分类
- 语言: 英文
- 标签: ghibli, ai-generated, image-classification
- 大小: 1K<n<10K
- 许可证: other(非商业研究用途)
- 任务类别: 图像分类
- 任务ID: 多类分类
- 分割:
- train: 4347个样本
- 注释创建者: 机器生成
- 源数据集:
- Nechintosh/ghibli
- nitrosocke/Ghibli-Diffusion
- KappaNeuro/studio-ghibli-style
数据集内容
- 标签: real, ai
- 数据形式:
metadata.jsonl(默认)
- 每行一个样本
- 包含字段:
id,image,label,description - 用途: 标准分类或图像-文本训练
pairs.jsonl
- 真实和AI生成图像配对
- 包含字段:
real_image,ai_image,description,seed - 用途: 对比学习或元学习
数据来源
- 真实图像:
- 来源: Nechintosh/ghibli
- 数量: 810张
- 许可证: 未明确说明,假设仅限非商业研究用途
- AI生成图像:
- 来源模型:
- nitrosocke/Ghibli-Diffusion(2727张)
- KappaNeuro/studio-ghibli-style(810张)
- 许可证: 社区许可证,限制为非商业和研究用途
- 来源模型:
加载方式
python from datasets import load_dataset
单图像分类
samples = load_dataset("pulnip/ghibli-dataset", split="train")
配对元学习结构
pairs = load_dataset("pulnip/ghibli-dataset", data_files="pairs.jsonl", split="train")
转换为二分类标签
for sample in samples: sample["binary_label"] = "real" if sample["label"] == "real" else "ai"
许可证与使用
- 数据集包含多个来源的内容,许可证各不相同。
- 整体数据集许可证为other,应视为仅限非商业研究用途。
- 用户在使用或重新分发前需仔细审查每个组件的许可证条款。
搜集汇总
数据集介绍
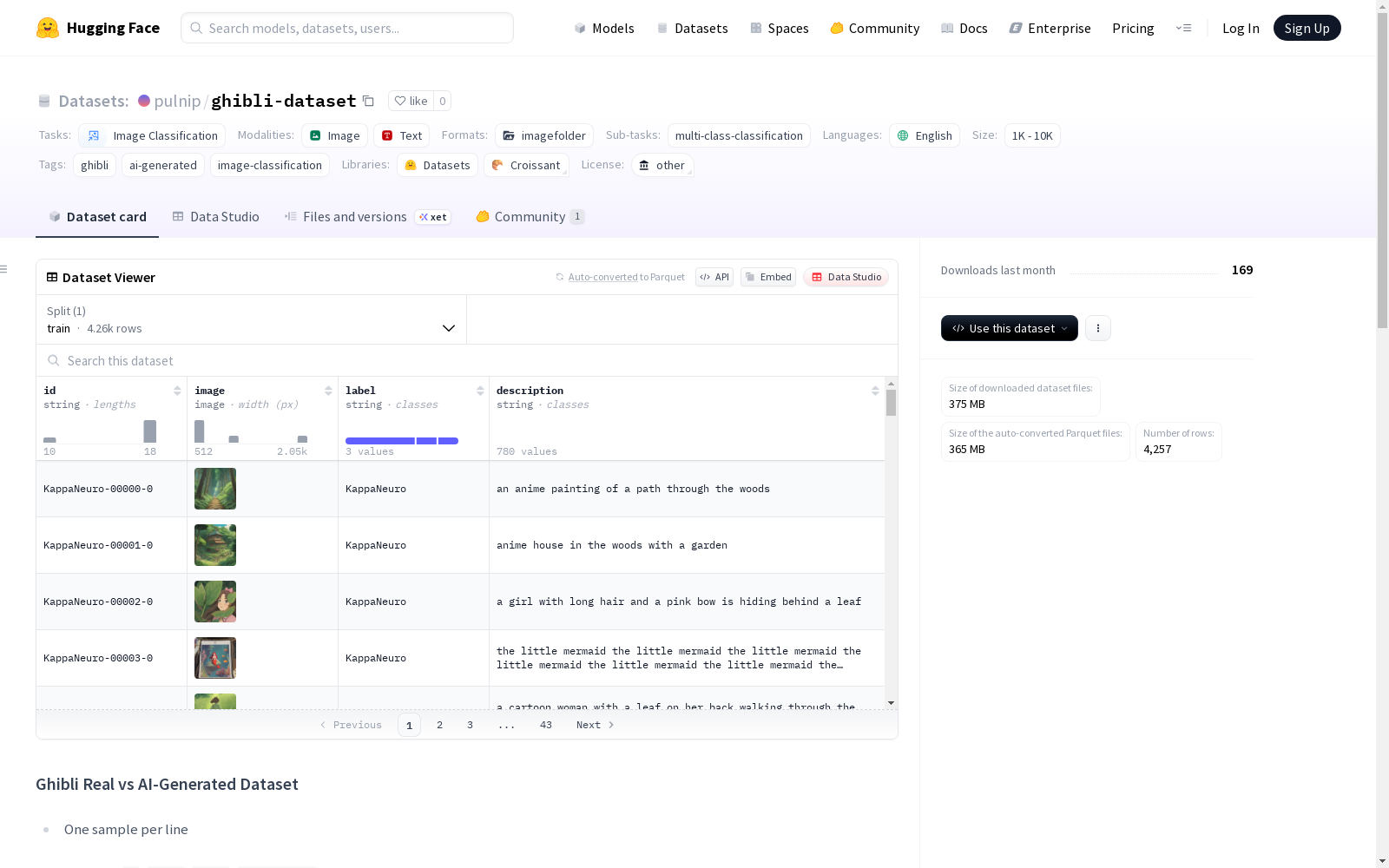
构建方式
在数字媒体艺术领域,吉卜力工作室作品的美学特征为图像生成技术提供了重要参考。本数据集通过整合真实图像与人工智能生成图像构建而成,真实图像来源于Nechintosh/ghibli数据集提供的810幅吉卜力风格作品,AI生成部分则利用nitrosocke/Ghibli-Diffusion和KappaNeuro/studio-ghibli-style两个扩散模型分别生成2637幅和810幅图像。所有样本采用机器自动标注机制,每条数据包含图像标识符、像素数据、分类标签及文本描述,最终形成包含4257个样本的训练集。
使用方法
研究者可通过HuggingFace数据集库直接加载该资源,使用load_dataset函数指定数据集名称即可获取训练分割。由于原始标签包含三个细分类别,用户需通过二值化处理将非真实标签统一归为AI类别,以适配真假图像分类任务。数据集支持标准图像分类流程,也可结合描述文本开展多模态学习实验。需要注意的是,所有图像均受非商业使用限制,研究人员应严格遵守各数据源的知识产权协议,在模型训练前仔细核查许可条款。
背景与挑战
背景概述
随着生成式人工智能技术的迅猛发展,数字媒体领域面临真实与合成内容鉴别的迫切需求。Ghibli Real vs AI数据集应运而生,由研究社区于近期构建,旨在针对吉卜力工作室艺术风格,系统化地区分真实图像与AI生成图像。该数据集整合了来自Nechintosh/ghibli的810张真实图像,以及基于nitrosocke/Ghibli-Diffusion和KappaNeuro/studio-ghibli-style两个扩散模型生成的3447张合成图像,共计4257条样本,专门服务于图像分类任务的非商业研究用途。其构建标志着计算机视觉领域在数字内容溯源与 authenticity 验证方面迈出关键一步,为媒体取证和生成模型安全性评估提供了重要基准。
当前挑战
该数据集核心挑战在于解决AI生成图像检测这一新兴领域的技术难题,特别是针对特定艺术风格(如吉卜力动画)的细微差异辨识。构建过程中面临多重挑战:其一,真实图像源数据规模有限且版权状态模糊,需严格遵循非商业研究用途的伦理约束;其二,合成图像生成依赖不同技术架构的扩散模型,需确保生成质量与风格一致性的平衡;其三,数据标注完全依赖机器生成,缺乏人工验证环节,可能引入标签噪声。此外,多源数据融合带来的许可证兼容性问题,以及生成模型快速迭代导致的基准过时风险,均为该数据集的可持续应用埋下隐忧。
常用场景
经典使用场景
在数字媒体与人工智能交叉领域,Ghibli数据集为图像分类任务提供了独特资源。该数据集最经典的应用场景在于训练和评估二分类模型,以区分真实吉卜力工作室图像与AI生成图像。通过包含4257张标注样本,研究者能够构建稳健的分类器,探索生成式模型在艺术风格模仿上的能力边界。这种应用不仅推动了图像鉴伪技术的发展,还为理解AI生成内容的视觉特征提供了实证基础。
解决学术问题
该数据集有效解决了生成式人工智能时代的关键学术问题,即如何可靠识别AI生成内容。通过提供标准化的真实与合成图像对比数据,它支持了数字媒体取证、生成模型评估等研究方向。其意义在于建立了艺术风格图像的可控实验环境,使研究者能定量分析生成模型的视觉保真度与缺陷,为数字内容真实性认证研究提供了重要基准。
实际应用
在实际应用层面,该数据集支撑了版权保护与内容审核系统的开发。文化创意产业可利用基于该数据训练的模型,检测未经授权的AI仿制作品,维护原创艺术家的权益。媒体平台也能借助此类技术识别合成内容,防止虚假信息传播。这些应用体现了人工智能伦理治理与文化产业数字化保护的现实需求。
数据集最近研究
最新研究方向
在数字媒体与人工智能交叉领域,Ghibli数据集为真实图像与AI生成图像的鉴别研究提供了重要基准。该数据集聚焦于吉卜力工作室风格的艺术作品,通过整合真实画作与基于Stable Diffusion等模型生成的合成图像,推动了生成式AI检测技术的前沿探索。当前研究热点集中于深度伪造检测、风格一致性分析以及跨模态表征学习,这些方向对于维护数字内容真实性、保障版权安全具有深远意义。随着AI生成内容的爆炸式增长,该数据集为构建鲁棒的分类模型和制定行业标准提供了关键支撑。
以上内容由遇见数据集搜集并总结生成


