SFinD-S
收藏Hugging Face2024-08-22 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/tilmann-strative/SFinD-S
下载链接
链接失效反馈官方服务:
资源简介:
Strative Finance Dataset - Synthetic(SFinD-S)是一个全面的数据集,专为金融领域的检索增强生成(RAG)GenAI应用、自然语言处理(NLP)、大型语言模型(LLM)和其他人工智能任务设计。完整的数据集包含超过20,000条来自各种网络内容的现实金融问题和经过验证的答案。该数据集专注于金融领域的问题和答案,提供完整的HTML内容,适用于RAG、NLP、LLM和AI应用。
创建时间:
2024-08-19
原始信息汇总
数据集概述
数据集描述
SFinD-S(Strative Financial Dataset - Synthetic)是一个综合性的数据集,专为增强生成(RAG)GenAI应用、自然语言处理(NLP)、大型语言模型(LLM)以及金融领域的AI任务设计。完整的数据集包含超过20,000条来自各种网络内容的现实金融问题和经过验证的答案。
关键特性
- 专注于金融领域的问题和答案
- 完整数据集包含短和长的HTML示例(本样本侧重于较短的HTML以方便使用)
- 通过复杂的基于AI的流程创建的现实问题和验证答案
- 提供完整的HTML内容(未压缩)
- 设计用于RAG、NLP、LLM和AI应用
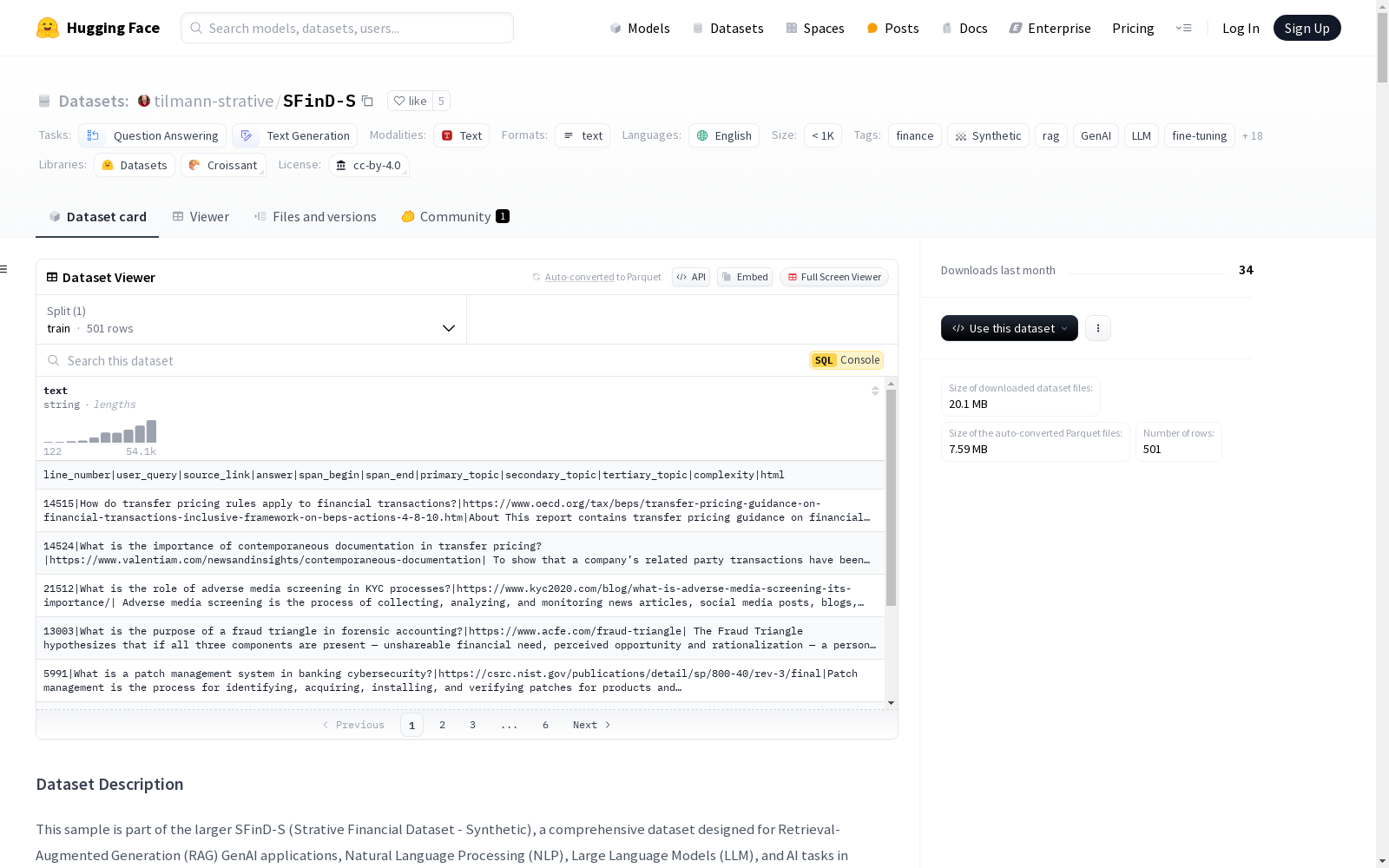
数据字段
line_number: 在更大SFinD-S数据集中引用记录的唯一标识符user_query: 原始金融问题source_link: 来源网页的URLanswer: 用户查询的提取答案span_begin: 答案在HTML内容中的起始位置span_end: 答案在HTML内容中的结束位置primary_topic,secondary_topic,tertiary_topic: 主题分类complexity: 查询/答案对的复杂性级别html: 来源网页的完整HTML内容
潜在应用
- RAG(增强生成检索)系统
- LLM微调
- 检索模型训练和微调
- RAG准确性优化
- 金融问答系统
- 金融信息检索
- 金融内容的文本摘要
- 金融主题分类
- 金融网页内容分析
数据集统计报告
样本总数
- 500
前25个主要主题
- 网络安全: 44
- 监管合规: 40
- 金融科技: 29
- 加密货币: 25
- 风险管理: 22
- 固定收益: 16
- 金融监管: 14
- 金融包容性: 14
- 公司财务: 14
- 反洗钱: 13
- 投资: 12
- 税收: 12
- 个人财务: 11
- 投资策略: 9
- 法务会计: 9
- 法律: 7
- 小额信贷: 7
- 公共财务: 7
- 衍生品: 7
- 伊斯兰金融: 6
- 市场监管: 6
- 另类投资: 5
- 金融科技: 5
- 高管薪酬: 5
- 交易: 5
其他: 156
前25个次要和第三主题
- 风险管理: 30
- 监管: 26
- 举报人保护: 23
- 通胀保护: 20
- 反洗钱: 18
- 破产: 17
- 人工智能: 15
- 合规: 10
- 监管合规: 10
- 转让定价: 9
- 网络安全: 9
- 银行监管: 8
- 金融教育: 7
- 债权人权利: 7
- 投资策略: 7
- 数据分析: 7
- 政府证券: 7
- 国际合作: 7
- 个人财务: 7
- 自然语言处理: 6
- 市场操纵: 6
- 欺诈检测: 6
- 信用风险: 6
- 银行: 6
- 银行监管: 6
其他: 720
复杂度分布
- 高级: 305
- 中级: 173
- 初级: 22
问题长度统计
- 平均值: 71.21
- 中位数: 70.50
- 最小值: 23.00
- 最大值: 118.00
答案长度统计
- 平均值: 300.77
- 中位数: 286.00
- 最小值: 50.00
- 最大值: 1140.00
HTML大小统计(字节)
- 平均值: 38436.53
- 中位数: 40970.00
- 最小值: 5506.00
- 最大值: 51008.00
许可证
本样本数据集根据Creative Commons Attribution 4.0 International (CC BY 4.0)许可证授权。该许可证允许共享和改编材料用于任何目的,包括商业用途,前提是提供适当的归属给Strative。用户必须给予Strative信用,提供许可证链接,并指出是否进行了更改。这可以以任何合理的方式进行,但不得以任何方式暗示Strative认可用户或其使用。
搜集汇总
数据集介绍
构建方式
SFinD-S数据集通过先进的AI技术生成,涵盖了超过20,000条金融领域的问答数据。这些数据源自广泛的网络内容,经过严格的验证和筛选,确保其真实性和准确性。数据集的构建过程包括从网页中提取完整的HTML内容,并标注答案的起始和结束位置,以便于后续的信息检索和生成任务。
使用方法
SFinD-S数据集适用于多种AI任务,包括检索增强生成(RAG)系统、自然语言处理(NLP)和大语言模型(LLM)的微调。用户可以通过数据集中的HTML内容和标注信息,训练和优化信息检索模型,提升金融问答系统的准确性。此外,数据集还可用于金融文本摘要、主题分类和金融内容分析等任务。
背景与挑战
背景概述
SFinD-S(Strative Financial Dataset - Synthetic)数据集由Strative公司开发,旨在为金融领域的生成式人工智能(GenAI)应用、自然语言处理(NLP)和大语言模型(LLM)提供支持。该数据集包含超过20,000条真实的金融问题及其经过验证的答案,涵盖了广泛的金融主题,如网络安全、监管合规、金融科技等。Strative作为一家专注于生成式AI和大语言模型开发的先锋企业,致力于通过先进的数据科学技术推动金融领域的创新与效率提升。SFinD-S的构建不仅为金融问答系统、信息检索和文本摘要等任务提供了高质量的训练数据,还为金融服务的智能化转型奠定了坚实基础。
当前挑战
SFinD-S数据集在构建和应用过程中面临多重挑战。首先,金融领域的复杂性和专业性要求数据集必须涵盖广泛的主题,并确保答案的准确性和权威性,这对数据源的筛选和验证提出了极高要求。其次,生成式AI模型在金融领域的应用需要处理大量非结构化数据,如HTML格式的网页内容,如何高效提取和标注这些数据成为一大难题。此外,金融数据的动态性和时效性要求数据集必须不断更新,以反映最新的市场变化和监管政策。最后,如何在保证数据多样性的同时,避免引入偏见或错误信息,也是构建高质量金融数据集的关键挑战。
常用场景
经典使用场景
SFinD-S数据集在金融领域的自然语言处理任务中展现了其独特的价值。该数据集通过提供大量真实的金融问题和经过验证的答案,为检索增强生成(RAG)系统、大型语言模型(LLM)的微调以及信息检索模型的训练提供了丰富的资源。研究人员和开发者可以利用这些数据来优化金融问答系统的性能,提升模型在复杂金融场景下的理解和生成能力。
解决学术问题
SFinD-S数据集解决了金融领域自然语言处理中的多个关键问题。首先,它通过提供多样化的金融问题和答案,帮助研究人员更好地理解金融文本的复杂性和多样性。其次,数据集中的HTML内容为信息提取和文本分析提供了丰富的上下文信息,使得模型能够在更广泛的金融文档中进行精确的答案检索和生成。此外,数据集的复杂性分级为模型在不同难度任务上的性能评估提供了标准化的基准。
实际应用
在实际应用中,SFinD-S数据集被广泛用于金融科技领域的多个场景。例如,金融机构可以利用该数据集训练智能客服系统,以自动回答客户关于投资、税务、合规等方面的复杂问题。此外,数据集的文本摘要功能可以帮助分析师快速提取金融文档中的关键信息,提升工作效率。在金融监管领域,该数据集还可以用于训练自动化合规检查系统,帮助机构快速识别潜在的合规风险。
数据集最近研究
最新研究方向
SFinD-S数据集作为金融领域的重要资源,近年来在检索增强生成(RAG)系统和大语言模型(LLM)的微调中展现了显著的应用潜力。随着金融科技的快速发展,该数据集被广泛用于构建智能问答系统、信息检索模型以及金融文本摘要生成。特别是在金融合规、风险管理和加密货币等热点领域,SFinD-S通过其丰富的主题分类和复杂性问题设计,为研究者提供了高质量的训练数据。此外,该数据集在金融信息提取和主题分类任务中的表现,进一步推动了金融领域自然语言处理技术的发展,为金融机构的智能化转型提供了有力支持。
以上内容由遇见数据集搜集并总结生成


