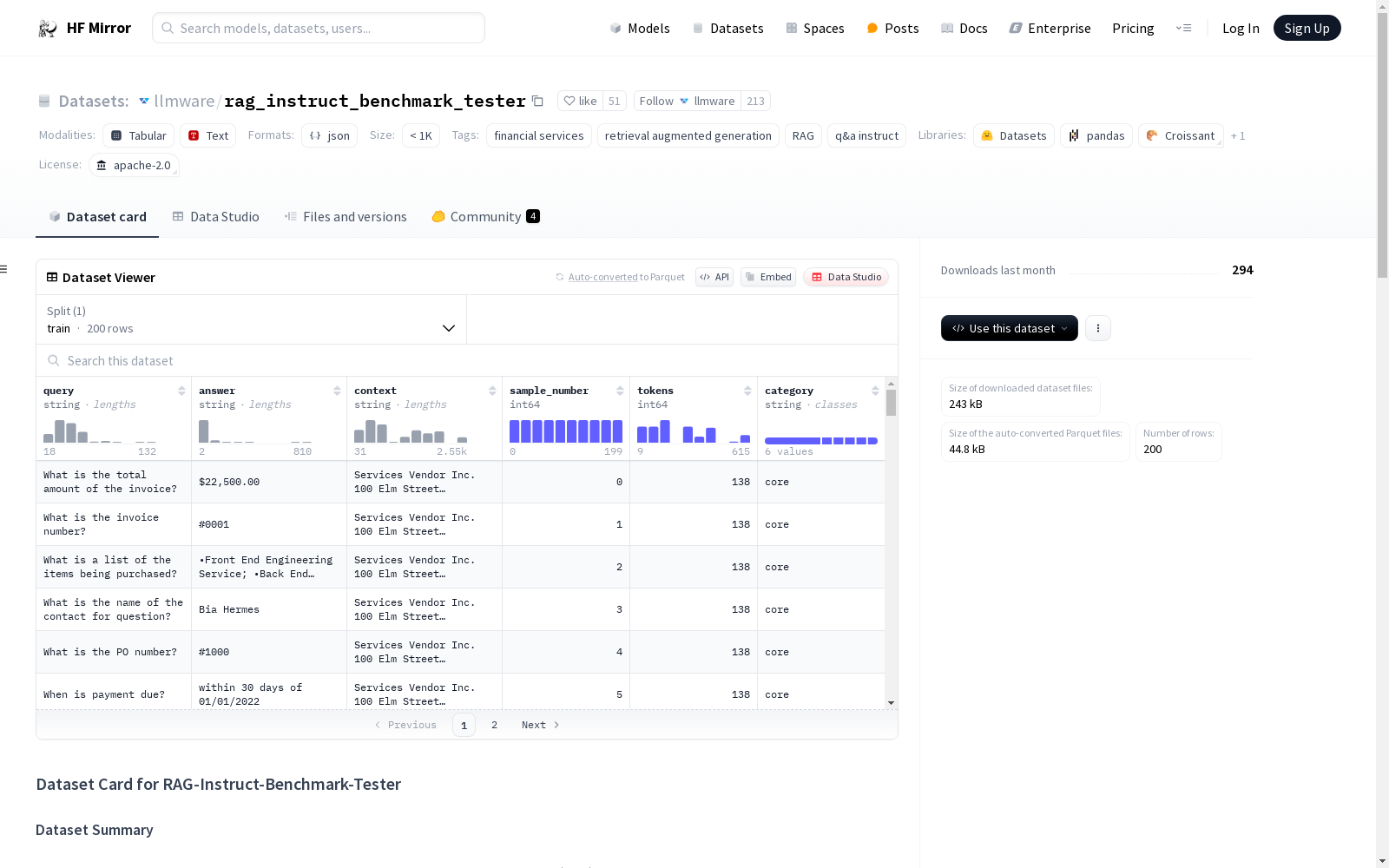
llmware/rag_instruct_benchmark_tester
收藏Hugging Face2023-11-04 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/llmware/rag_instruct_benchmark_tester
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
tags:
- financial services
- retrieval augmented generation
- RAG
- q&a instruct
pretty_name: RAG Instruct Benchmarking Test Dataset
---
# Dataset Card for RAG-Instruct-Benchmark-Tester
### Dataset Summary
This is an updated benchmarking test dataset for "retrieval augmented generation" (RAG) use cases in the enterprise, especially for financial services, and legal. This test dataset includes 200 questions with context passages pulled from common 'retrieval scenarios', e.g., financial news, earnings releases,
contracts, invoices, technical articles, general news and short texts.
The questions are segmented into several categories for benchmarking evaluation:
-- **Core Q&A Evaluation** (Samples 0-99) - 100 samples - fact-based 'core' questions- used to assign a score between 0-100 based on correct responses.
-- **Not Found Classification** (Samples 100-119) - 20 samples - in each sample, the context passage does not contain a direct answer to the question, and the objective is to evaluate whether the model correctly identifies as "Not Found" or attempts to answer using information in the context.
-- **Boolean - Yes/No** (Samples 120-139) - 20 samples - each sample is a Yes/No question.
-- **Basic Math** (Samples 140-159) - 20 samples - these are "every day" math questions - basic increments, decrements, percentages, multiplications, sorting, and ranking with amounts and times.
-- **Complex Q&A** (Samples 160-179) - 20 samples - tests several distinct 'complex q&a' skills - multiple-choice, financial table reading, multi-part extractions, causal, and logical selections.
-- **Summary** (Sample 180-199) - 20 samples - tests long-form and short-form summarization.
### Representative Questions
-- What are the payment terms?
-- What was the improvement in operating income year-to-year?
-- According to the CFO, what led to the increase in cloud revenue?
-- Who owns the intellectual property?
-- What is the notice period to terminate for convenience?
-- How often will the Board review the salary?
-- What section of the agreement defines the governing law?
-- How many jobs were predicted by economists?
-- How many shares were repurchased in second quarter?
-- What was the percentage increase in data center revenue compared to the first quarter?
-- When will the next dividend be paid?
-- Is the expected gross margin greater than 70%?
-- What is the amount of expected non-GAAP operating expense?
-- What did economists expect for the trade surplus amount?
-- What is Bank of Americas' rating on Snowflake?
-- Has the S&P increased over the last year? (Yes/No)
-- Is Barclay's raising its price target on KHC? (Yes/No)
-- Were third quarter sales more than 5 billion euros? (Yes/No)
-- If automotive revenue increases by $100 million in third quarter, what will be the amount? (Math)
-- If the rent increased by 50%, what is the new rental price? (Math)
-- Which stock index increased by the most points yesterday? (Math)
-- Why did the intraday reversal occur? (Complex)
-- What is a list of the top 3 financial highlights for the quarter? (Summary)
-- What is a list of the top 5 summary points? (Summary)
-- What is a summary of the CEO's statement in 15 words or less? (Summary)
-- What are the key terms of the invoice? (Summary)
### Languages
English
## Dataset Structure
200 JSONL samples with 6 keys - "query" | "context" | "answer" | "category" | "tokens" | "sample_number"
Note: this dataset includes elements from test_dataset_0.1 and test_dataset2_financial- and is intended to replace them for benchmarking evaluations.
### Personal and Sensitive Information
The dataset samples were written bespoke for this objective, derived from publicly-available sources and/or originally-written samples.
## Dataset Card Contact
Darren Oberst & llmware team
Please reach out anytime if you are interested in more information about this project.
---
license: apache-2.0
标签:
- 金融服务
- 检索增强生成
- RAG
- 问答指令
展示名:RAG指令基准测试数据集
---
# RAG-Instruct-Benchmark-Tester 数据集卡片
### 数据集概述
本数据集为针对企业级场景(尤其金融服务与法律领域)的**检索增强生成(Retrieval Augmented Generation, RAG)**任务更新的基准测试数据集。本次测试集共包含200道问题,配套上下文段落取自常见检索场景,例如金融新闻、财报公告、合同、发票、技术文章、通用新闻及短文本。
所有问题被划分为多个类别以支持基准评估:
- **核心问答评估(样本0-99)**:共100个样本,为基于事实的“核心”问题,用于基于正确回答进行0-100分的评分。
- **未找到分类任务(样本100-119)**:共20个样本,每个样本的上下文段落均未包含问题的直接答案,评估目标为判断模型能否正确识别为“未找到”,或仅基于上下文信息强行作答。
- **布尔型(是/否)问答(样本120-139)**:共20个样本,所有问题均为是/否类题型。
- **基础数学计算(样本140-159)**:共20个样本,均为日常基础数学问题,涵盖加减运算、百分比计算、乘法、金额与时间相关的排序与排名。
- **复杂问答(样本160-179)**:共20个样本,用于测试多项差异化的“复杂问答”能力,包括选择题、金融表格解读、多部分信息提取、因果与逻辑选择。
- **摘要生成(样本180-199)**:共20个样本,用于测试长文本与短文本摘要生成能力。
### 典型示例问题
- 付款条款是什么?
- 本年度营业营收同比增幅如何?
- 据首席财务官(CFO)表述,云服务营收增长的动因是什么?
- 知识产权归属方是谁?
- 任意终止合同的通知期限是多久?
- 董事会多久审查一次薪酬方案?
- 协议中的哪一条款定义了管辖法律?
- 经济学家预测的就业岗位数量是多少?
- 第二季度的股票回购数量是多少?
- 数据中心营收较第一季度的增幅百分比是多少?
- 下一次股息派发时间是什么时候?
- 预计毛利率是否高于70%?(是/否)
- 预计非GAAP营业费用总额是多少?
- 经济学家预期的贸易顺差金额是多少?
- 美国银行(Bank of America)对Snowflake的评级是什么?
- 标普500指数去年全年是否出现上涨?(是/否)
- 巴克莱银行(Barclays)是否上调了对KHC的目标股价?(是/否)
- 第三季度销售额是否超过50亿欧元?(是/否)
- 若第三季度汽车营收增加1亿美元,总营收将达到多少?(数学计算)
- 若租金上涨50%,新的租金价格是多少?(数学计算)
- 昨日涨幅最大的股票指数是哪一个?(数学计算)
- 日内反转行情出现的原因是什么?(复杂问答)
- 请列出本季度前三大财务亮点?(摘要生成)
- 请列出前五大核心总结要点?(摘要生成)
- 请用15个及以内的单词总结首席执行官(CEO)的声明?(摘要生成)
- 发票的关键条款是什么?(摘要生成)
### 语言
英语
## 数据集结构
共200条JSONL格式样本,包含6个键值字段:`query`(查询)、`context`(上下文)、`answer`(答案)、`category`(类别)、`tokens`(Token)、`sample_number`(样本编号)。
注:本数据集整合了`test_dataset_0.1`与`test_dataset2_financial`的相关元素,旨在替代二者用于基准评估任务。
### 个人与敏感信息
本数据集样本均为本项目量身定制,源自公开可用数据源或原创编写。
## 数据集卡片联系人
达伦·奥伯斯特(Darren Oberst)与llmware团队。如有兴趣了解项目更多信息,可随时联系。
提供机构:
llmware
原始信息汇总
数据集卡片 - RAG-Instruct-Benchmark-Tester
数据集概述
这是一个针对企业中“检索增强生成”(RAG)用例的更新基准测试数据集,特别是在金融服务和法律领域。该测试数据集包含200个问题,这些问题与从常见“检索场景”中提取的上下文段落相关,例如金融新闻、财报、合同、发票、技术文章、一般新闻和短文本。
问题被分为几个类别进行基准评估:
- 核心问答评估(样本0-99) - 100个样本 - 基于事实的“核心”问题 - 用于根据正确响应分配0-100的分数。
- 未找到分类(样本100-119) - 20个样本 - 每个样本中,上下文段落不包含问题的直接答案,目标是评估模型是否正确识别为“未找到”或尝试使用上下文中的信息回答。
- 布尔值 - 是/否(样本120-139) - 20个样本 - 每个样本是一个是/否问题。
- 基本数学(样本140-159) - 20个样本 - 这些是“日常”数学问题 - 基本增减、百分比、乘法、排序和排名,涉及金额和时间。
- 复杂问答(样本160-179) - 20个样本 - 测试几种不同的“复杂问答”技能 - 多选、财务表格阅读、多部分提取、因果和逻辑选择。
- 总结(样本180-199) - 20个样本 - 测试长格式和短格式总结。
代表性问题
- 付款条款是什么?
- 运营收入同比改善了多少?
- 根据CFO的说法,是什么导致了云收入的增加?
- 谁拥有知识产权?
- 终止方便的通知期限是多久?
- 董事会多久审查一次薪水?
- 协议的哪一部分定义了管辖法律?
- 经济学家预测了多少个工作岗位?
- 第二季度回购了多少股票?
- 数据中心收入与第一季度相比增长了多少百分比?
- 下一次股息何时支付?
- 预期毛利率是否大于70%?
- 预期非GAAP运营费用是多少?
- 经济学家对贸易顺差金额的预期是多少?
- 美国银行对Snowflake的评级是什么?
- 标准普尔指数在过去一年中是否上涨?(是/否)
- 巴克莱是否提高了KHC的目标价格?(是/否)
- 第三季度销售额是否超过50亿欧元?(是/否)
- 如果汽车收入在第三季度增加1亿美元,金额是多少?(数学)
- 如果租金增加了50%,新的租金价格是多少?(数学)
- 昨天哪个股票指数上涨最多点?(数学)
- 日内反转发生的原因是什么?(复杂)
- 本季度的前3个财务亮点是什么?(总结)
- 前5个总结点是什么?(总结)
- CEO声明的15个字以内的总结是什么?(总结)
- 发票的关键条款是什么?(总结)
语言
英语
数据集结构
200个JSONL样本,包含6个键 - "query" | "context" | "answer" | "category" | "tokens" | "sample_number"
注意:此数据集包含来自test_dataset_0.1和test_dataset2_financial的元素,旨在替代它们进行基准评估。
个人和敏感信息
数据集样本是为这一目标定制编写的,源自公开可用来源和/或原创样本。
搜集汇总
数据集介绍
构建方式
RAG Instruct Benchmarking Test Dataset 采取精心设计的结构,将200个问题与对应的上下文段落结合,这些问题和段落源自金融新闻、财报、合同、发票、技术文章以及通用新闻等常见的检索场景。数据集被细分为多个类别,以针对不同的问答技能进行基准测试评估,包括事实性问题、未找到分类、是非题、基本数学题、复杂问答以及总结题,旨在全面评估模型在检索增强生成任务中的表现。
特点
本数据集的特点在于其多样化的问答类型和针对性的评估设计,覆盖了从简单的事实性问题到复杂的逻辑推理和总结任务。所有样本均为专门为此目的编写的,确保来源的公开性和可靠性。此外,数据集遵循Apache-2.0许可,保证了使用的灵活性和开放性。其结构化的JSONL格式,包含六个关键字,便于处理和分析。
使用方法
使用该数据集时,用户可以依据数据集中的不同类别,对模型进行综合性的性能评估。数据集的每个样本都包含问题、上下文、答案、类别、令牌和样本编号,便于用户进行精确的测试和结果分析。此外,数据集取代了之前的test_dataset_0.1和test_dataset2_financial,成为新的基准测试标准,用户可以直接用于模型的性能评估和优化。
背景与挑战
背景概述
RAG Instruct Benchmarking Test Dataset,简称RAG-Instruct-Benchmark-Tester,是一个针对企业级'检索增强生成'(retrieval augmented generation,简称RAG)使用案例的更新版基准测试数据集。该数据集特别针对金融服务和法务领域,包含了从常见的'检索场景'中提取的200个问题及上下文段落,如金融新闻、收益报告、合同、发票、技术文章、一般新闻和短文本。此数据集由llmware团队创建,旨在为相关领域的研究提供评价标准,其创建时间为近期,具体年份未在README中明确提及。该数据集对RAG技术在企业中的应用进行了深入研究,对相关领域产生了显著影响。
当前挑战
该数据集在构建过程中面临的挑战主要包括:如何精确地构建不同类型的问题以全面评估RAG的性能,以及如何确保所提供的上下文信息既具有代表性又不过于冗长。此外,数据集在解决金融和法律服务领域的领域问题时,需要处理的挑战包括准确识别并处理'未找到'答案的情况,以及评估模型在处理布尔问题、基础数学问题和复杂问答技能方面的表现。数据集的构建还需考虑如何平衡各类问题的数量,以及如何确保数据集中不含有个人敏感信息,以保证数据的安全性和隐私性。
常用场景
经典使用场景
在深入理解金融和法律领域知识的基础上,RAG Instruct Benchmarking Test Dataset被广泛运用于评估检索增强生成(RAG)模型的性能。该数据集精选了200个问题,涵盖了从金融新闻到技术文章等多种文本类型,旨在模拟实际场景中模型的检索和生成能力,特别是在面对事实性问题、信息检索、数学计算和复杂问题解答等场景中,该数据集提供了丰富的评估样本。
实际应用
在实际应用中,该数据集可以帮助企业评估其使用的检索增强生成系统在处理金融和法律文档时的有效性。通过使用该数据集进行系统测试,企业能够确保其系统在处理合同、财务报告和其他关键法律文件时能够提供准确和及时的回答,这对于提升决策质量和客户服务质量至关重要。
衍生相关工作
基于RAG Instruct Benchmarking Test Dataset的研究已经衍生出了一系列相关工作,包括对现有模型的改进、新型生成模型的开发以及针对特定金融和法律任务的定制化模型构建。这些工作进一步推动了在金融和法律领域中自然语言处理技术的应用,为相关领域的智能化提供了强有力的技术支撑。
以上内容由遇见数据集搜集并总结生成


