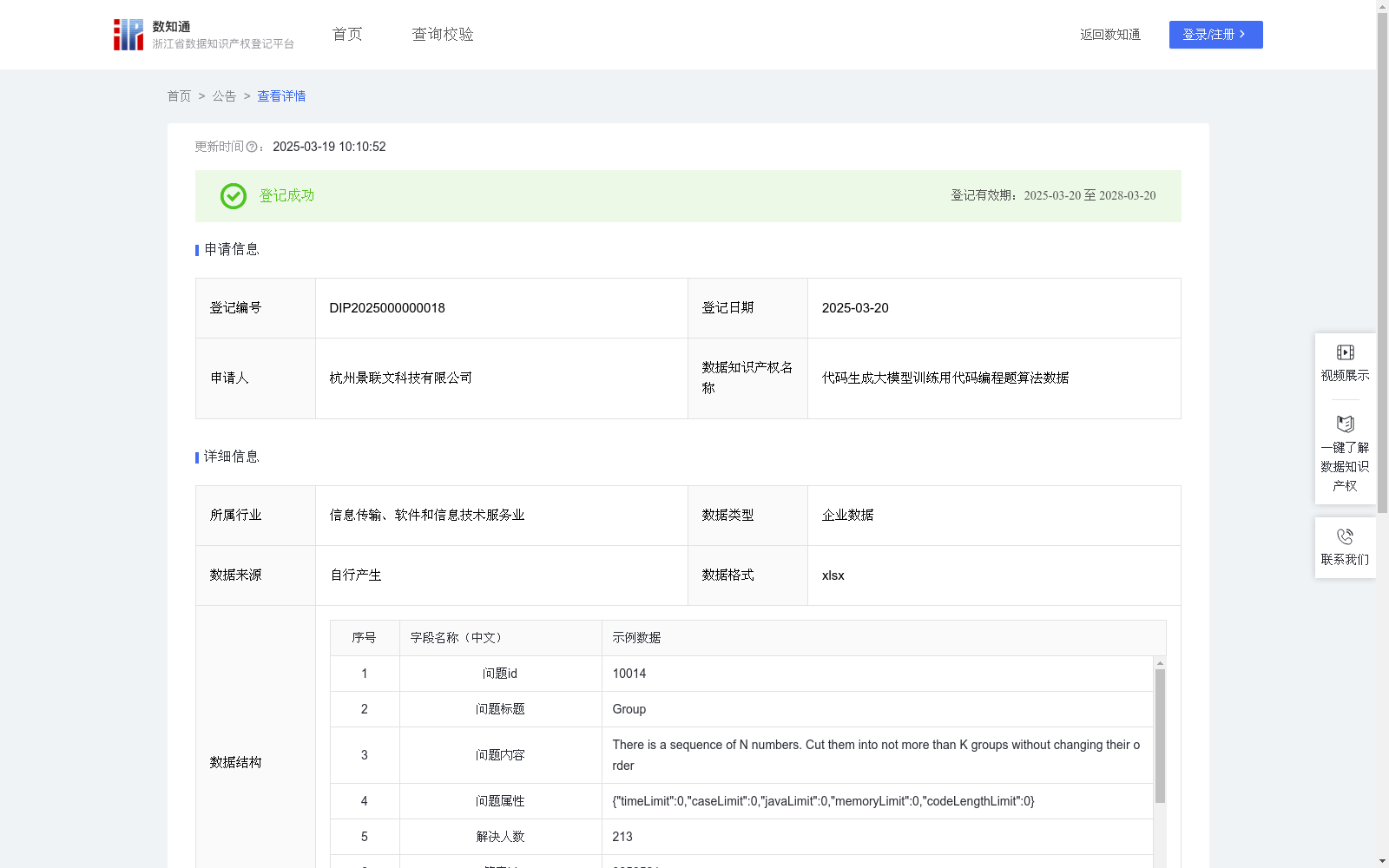
代码生成大模型训练用代码编程题算法数据
收藏浙江省数据知识产权登记平台2025-03-19 更新2025-03-20 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/118276
下载链接
链接失效反馈官方服务:
资源简介:
用于AI大模型领域中代码生成大模型训练:
1.提升大模型对用户提出的代码需求文字的上下文理解能力,使大模型能精准回答用户所需代码
2.扩展大模型的代码知识库,包含python、java、c、c#、c++、php、delphi、pascal等编程语言对应代码,使大模型能用多种编程语言解答用户的算法需求
3.扩展大模型的算法知识库,使大模型能解答用户的包含经典排序算法、经典搜索算法及各类衍生的实际应用算法需求
4.提升大模型所生成的代码性能,该数据中包含“代码运行时间““代码运行内存”字段,标记出高性能质量的代码,使大模型能识别并生成高性能代码1.数据预处理:整理经典代码编程问题,清洗数据,保证问题内容、问题属性(即答案代码性能要求)无缺失。
2.数据标准化:对上述字段设计字段标准,将各字段的长度、格式、精度等进行统一转换
3.生产答案代码:使用公司自有的人工标注平台进行人工生产答案代码,并自动化运行、记录答案状态(即代码运行结果)、代码语言、代码运行时间、代码运行内存
4.人工内容抽检:聘请专业技术人员对生成代码正确性、规范性、题目相关性以1%抽检率(共两千万条数据,抽检二十万条)进行人工检查,抽检不合格率为7.66%,符合业内大部分大模型对训练数据的质量要求
5.敏感词检测:调用算法对所有数据进行敏感词检测,包括涉黄、涉暴、涉恐及政治敏感词检测及过滤
提供机构:
杭州景联文科技有限公司
创建时间:
2025-01-02
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含10万条编程题算法数据,用于训练代码生成大模型,提升模型对代码需求的理解和生成能力,支持多种编程语言,并注重代码性能优化。数据经过严格预处理和质量控制。
以上内容由遇见数据集搜集并总结生成


