hikma_results
收藏Hugging Face2026-04-21 更新2026-04-22 收录
下载链接:
https://huggingface.co/datasets/alinf/hikma_results
下载链接
链接失效反馈官方服务:
资源简介:
HIKMA(人文与伊斯兰知识多任务评估)基准测试结果数据集记录了AI模型在伊斯兰知识相关任务上的性能评估数据。数据集包含1条结果记录,主要字段包括:模型名称(model)、综合得分(overall)、古兰经相关得分(quran)、多种波斯语塔夫西尔(tafsir)注释的难易版本评估结果(如hikma_quran_almizan/hikma_quran_nemooneh等)、模型元数据(参数量#parameters (B)、架构architecture、许可license等)。该数据集适用于评估语言模型在伊斯兰教文本理解、古兰经注释分析等领域的多任务表现,特别关注波斯语场景下的难易度区分。数据以结构化表格形式存储,总大小为157字节。
The HIKMA (Humanities and Islamic Knowledge Multi-task Assessment) benchmark results dataset records the performance evaluation data of AI models on tasks related to Islamic knowledge. The dataset contains 1 result record, with main fields including: model name (model), overall score (overall), Quran-related score (quran), evaluation results of various Persian Tafsir (commentary) difficulty versions (e.g., hikma_quran_almizan/hikma_quran_nemooneh, etc.), and model metadata (#parameters (B), architecture, license, etc.). This dataset is suitable for evaluating the multi-task performance of language models in the fields of Islamic text understanding and Quran commentary analysis, with a particular focus on difficulty differentiation in Persian scenarios. The data is stored in a structured table format, with a total size of 157 bytes.
创建时间:
2026-04-21
原始信息汇总
数据集概述:HIKMA Benchmark Results
数据集名称:HIKMA (Humanities and Islamic Knowledge Multitask Assessment) Benchmark Results
数据集地址:https://huggingface.co/datasets/alinf/hikma_results
数据集描述
该数据集收录了 HIKMA 基准测试的评估结果,HIKMA 代表“人文与伊斯兰知识多任务评估”,专注于衡量模型在人文和伊斯兰知识领域的多任务表现。
数据配置
- 配置名称:
results - 数据划分:仅包含一个
results划分,包含 1 个样本,占用 157 字节。
数据特征
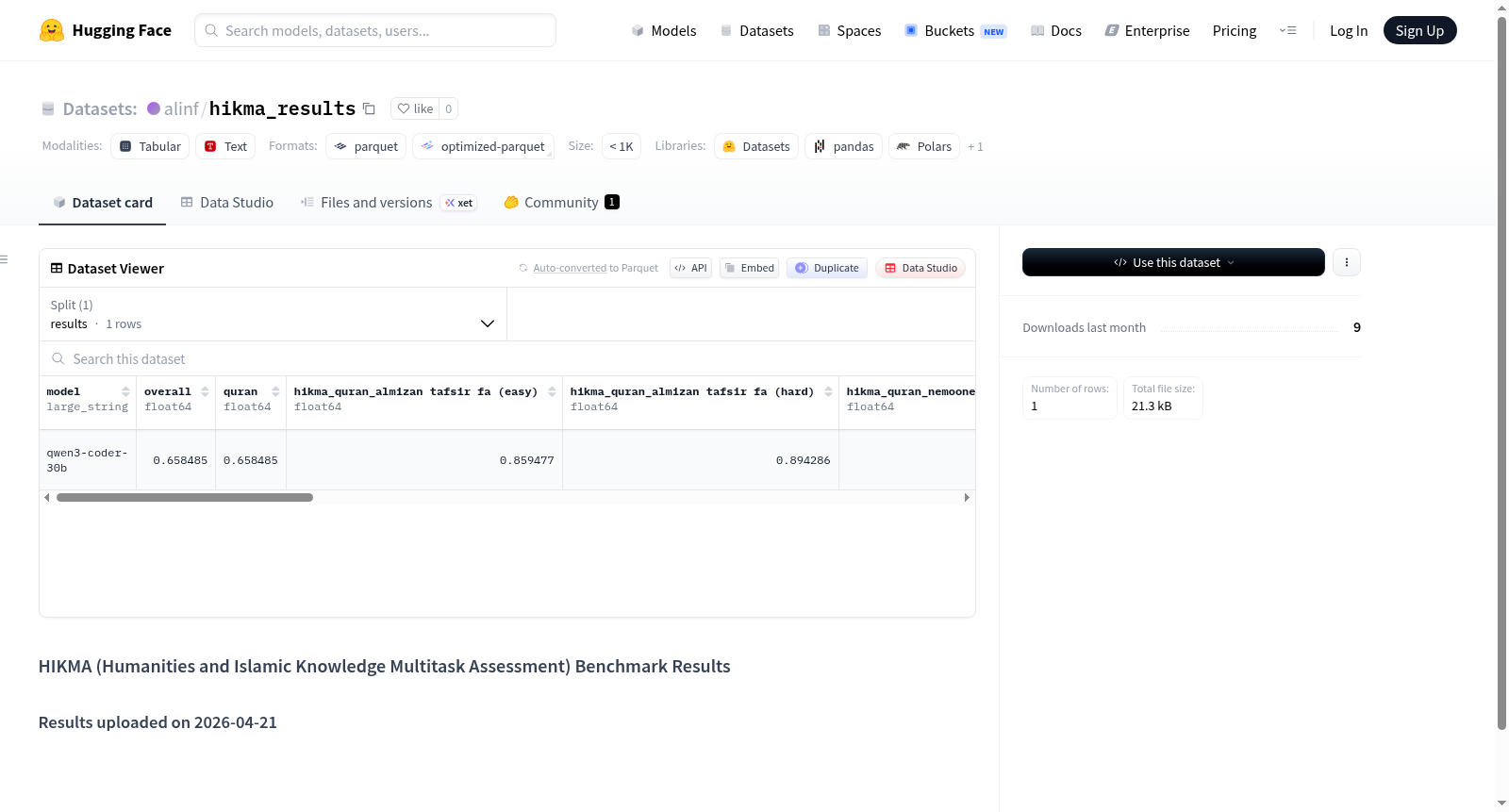
数据集中包含以下字段:
- model(字符串):模型名称
- overall(浮点数):总体得分
- quran(浮点数):古兰经相关任务得分
- hikma_quran_almizan tafsir fa (easy)(浮点数):Almizan 注释(简单)得分
- hikma_quran_almizan tafsir fa (hard)(浮点数):Almizan 注释(困难)得分
- hikma_quran_nemooneh tafsir fa (easy)(浮点数):Nemooneh 注释(简单)得分
- hikma_quran_nemooneh tafsir fa (hard)(浮点数):Nemooneh 注释(困难)得分
- hikma_quran_quran balagha nahw fa (easy)(浮点数):古兰经修辞与语法(简单)得分
- hikma_quran_quran balagha nahw fa (hard)(浮点数):古兰经修辞与语法(困难)得分
- hikma_quran_quran memorization fa (easy)(浮点数):古兰经背诵(简单)得分
- hikma_quran_surah info fa (easy)(浮点数):章节信息(简单)得分
- hikma_quran_surah info fa (hard)(浮点数):章节信息(困难)得分
- precision(字符串):精度设置
- #parameters (B)(浮点数):参数量(十亿)
- architecture(浮点数):模型架构
- license(浮点数):许可证
- model sha(浮点数):模型 SHA 值
其他信息
- 下载大小:8944 字节
- 结果上传时间:2026年4月21日
搜集汇总
数据集介绍
构建方式
在伊斯兰知识与人文领域评估的迫切需求下,HIKMA基准测试应运而生,旨在系统衡量大语言模型在伊斯兰研究及阿拉伯人文领域的多任务能力。hikma_results数据集作为该基准的标准化结果记录库,其构建遵循严谨的评估框架。数据以单行记录形式存储,包含模型名称、总体得分及细粒度分类指标,如《古兰经》知识、不同注释版本(如阿尔米赞经注、内穆内经注)的难易层级评估,以及修辞学、语法学等细分维度。每个模型的参数量、架构类型、许可证与模型哈希值均被纳入,形成结构化评估档案。所有结果经由统一预处理与归档流程,最终以Parquet格式存储于Hugging Face Datasets仓库中,确保数据可复现与可比较。
特点
该数据集的核心特色在于其高度的结构化与细粒度评估能力。每条记录不仅呈现模型在伊斯兰知识领域的综合表现,还深入剖析其在《古兰经》背诵、苏拉信息、巴拉加修辞学等12个特定子任务上的准确率,且每个任务均区分为简单与困难两种难度级别,从而精准定位模型的能力边界。此外,数据集中包含了模型的精确度(precision)、参数量级、架构类型等元信息,为分析模型规模与性能之间的关系提供了丰富维度。尽管当前仅包含单条示例数据,但其设计理念支撑着未来多模型、多版本结果的持续扩展,形成动态演进的评估生态。
使用方法
研究者可通过Hugging Face Datasets库直接加载该数据集,例如使用`load_dataset("hikma_results", split="results")`获取单行结果。加载后的数据以字典形式呈现,字段如`model`、`overall`及各子任务得分均可直接访问。鉴于数据集当前仅含一条记录,实际应用中更适合作为模板,引导用户按相同结构上传自家模型的评估结果。开发者亦可参照HIKMA基准的官方评估流程,运行标准化测试后,将输出结果整理为兼容格式,再追加至数据集。未来版本将支持跨模型结果查询与对比分析,助力研究社区追踪伊斯兰知识领域语言模型的演进轨迹。
背景与挑战
背景概述
HIKMA(人文学科与伊斯兰知识多任务评估)基准测试结果数据集于2026年4月21日由相关研究团队创建,旨在系统评估大规模语言模型在伊斯兰知识与人文学科领域的多任务能力。该数据集聚焦于《古兰经》相关任务,涵盖背诵、语法修辞、经文注释等子领域,并区分难易等级,为跨学科自然语言处理研究提供了标准化评估框架。其影响力在于弥补了当前模型在宗教与文化类高专业性任务上的评测空白,推动了多语言、多维度模型性能的比较研究。
当前挑战
该数据集所解决的领域挑战在于,现有评测基准多集中于通用知识或科学领域,缺乏对伊斯兰知识体系深度与专业性的精细评估,导致模型在宗教文本理解、逻辑推理与文化敏感性上表现欠佳。在构建过程中,研究者面临多重困难:如何准确划分任务难易等级并确保注释权威性;如何平衡不同子任务(如《古兰经》背诵与语法分析)的权重以反映真实能力;以及如何保证评测结果的可重复性与公平性,特别是在多模型、多参数规模下的比较分析中避免偏差。
常用场景
经典使用场景
在自然语言处理与计算人文科学交叉领域中,hikma_results数据集作为HIKMA基准测试的成果集合,主要用于评估多任务语言模型在伊斯兰知识与人文科学文本理解上的表现。该数据集聚焦于《古兰经》及其注释(如Al-Mizan和Nemouneh经注)、修辞学、语法学及背诵任务等多元化子领域,通过简单与困难两种难度层次,系统性地衡量模型在宗教文本解析中的精确度与泛化能力。研究者常借助此数据集验证模型在低资源、高语义复杂度场景下的推理性能,尤其适用于波斯语相关任务的细粒度评估。
衍生相关工作
围绕hikma_results数据集已衍生出多项具有启发性的研究工作。首先,该基准催生了对伊斯兰知识体系多任务学习的专项探索,研究者基于其评估框架提出了针对阿拉伯语与波斯语混合语料的细粒度预训练策略。其次,部分工作聚焦于难度分级对模型鲁棒性的影响,通过对比简单与困难子任务的表现差异,揭示了当前模型在复杂宗教论证链上的薄弱环节。此外,该数据集还激励了跨模态学习在《古兰经》注释中的尝试,将文本结果与语音背诵准确性相关联,开拓了宗教文本评估的新维度。
数据集最近研究
最新研究方向
当前,随着大语言模型在通用领域的性能日趋饱和,针对特定文化背景与专业知识领域的评估基准成为研究热点。HIKMA基准专注于伊斯兰知识与人文科学的多任务评估,涵盖古兰经理解、注释解析、修辞语法及记忆等维度,填补了宗教文本与古典学术交叉领域模型评测的空白。该数据集通过精细划分难度层级与子任务,推动模型在低资源语言(如波斯语)与宗教典籍上的深度推理能力研究。其最新结果发布于2026年,反映了对模型在非西方知识体系下语义理解与文化敏感性的前沿探索,对构建包容性、多元化的人工智能评估框架具有重要参考意义。
以上内容由遇见数据集搜集并总结生成


