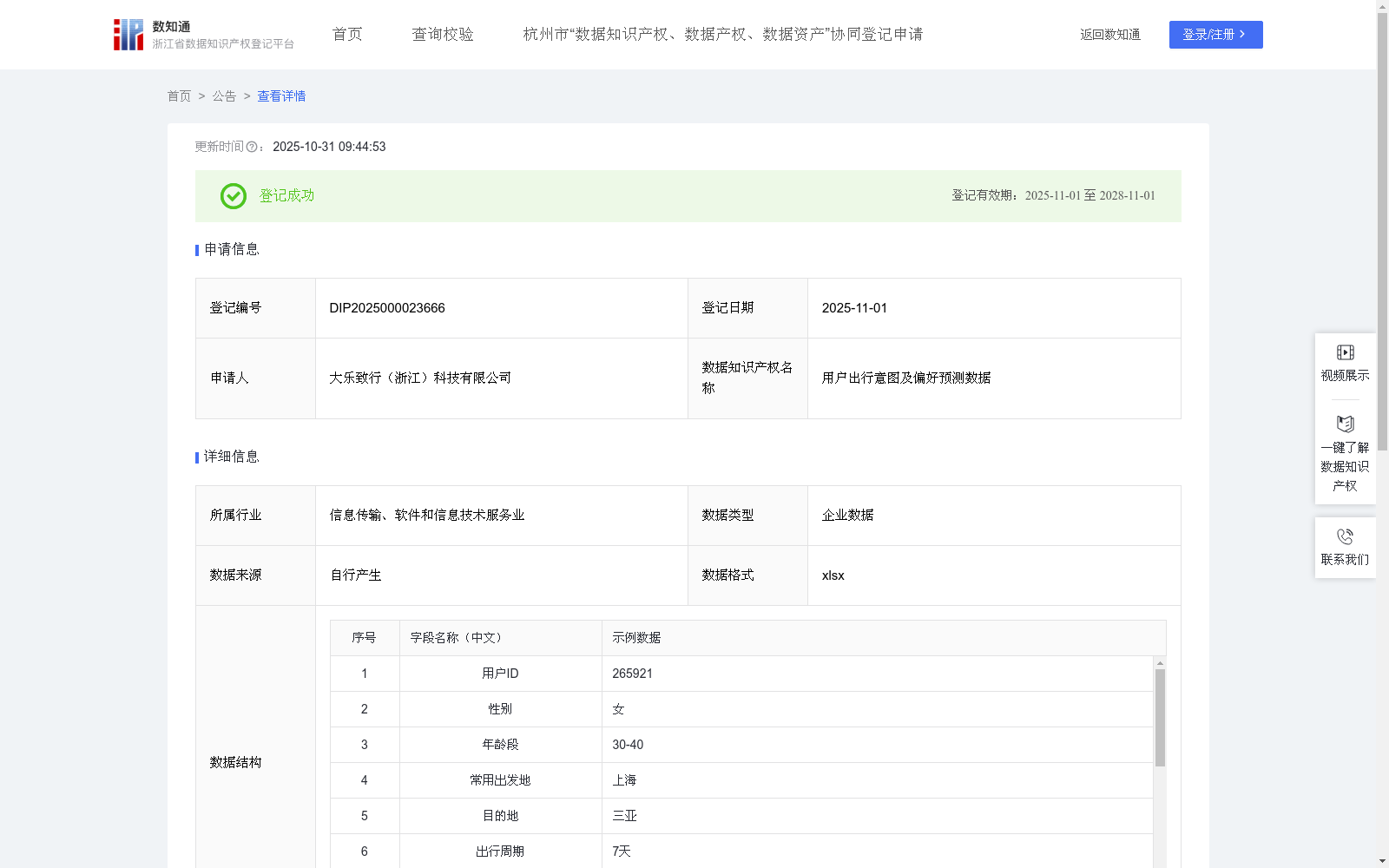
用户出行意图及偏好预测数据
收藏浙江省数据知识产权登记平台2025-10-31 更新2025-11-01 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/7166754
下载链接
链接失效反馈官方服务:
资源简介:
该数据包括用户画像、偏好预测、流失风险等级三大维度的结构化、可操作知识集合,其核心价值在于将原始数据转化为支持企业决策管理的数据。将用户的静态属性与动态行为通过 “流失风险预测得分” 和 “用户流失风险等级” 进行量化,实现客户生命周期的精细化管理。企业制定差异化策略,对“高风险”用户推送高价格优惠券及专属客户回访,对“中风险”用户进行轻度触达,可实现对潜在流失风险的高价值客户进行精准、低成本的干预与挽留,显著优化客户维系预算的投入产出比。1、数据采集:通过采集于自有平台内用户授权的历史交易数据、行为日志数据及基础属性数据。
2、数据处理:对直接个人用户ID标识符进行加密哈希处理,无法回溯到特定个人。对缺失、异常及逻辑错误的数据进行识别、清洗与填充,确保数据质量与一致性。将来自不同数据源的表进行关联与整合,形成以用户ID为主键的、统一的全量用户行为记录表。
3、本数据产品采用的“梯度提升决策树算法(Gradient Boosting Decision Tree)”,基于用户的历史行为,通过统计与规则模型,将其动态偏好固化为稳定标签。用户偏好预测模型通过进行多目标分类,以固化后的用户画像(性别、年龄段、历史地域偏好、交通偏好等)及近期活跃度作为模型输入特征模型输出为每个用户对不同偏好标签的预测概率,最终汇集成结构化的 “偏好预测” 字段。用户流失风险预测模型采用二分类模型,以用户是否在后续周期内流失为目标变量进行训练。核心特征为用户活跃度指标,模型为每个用户计算出一个0-1之间的 “流失风险预测得分”。得分越高,代表流失可能性越大。对“流失风险预测得分”设置阈值区间,进行分段。0-3为低风险,4-6为中风险,7-9为高风险。这是一个基于规则的后处理过程。为确保预测的时效性,本数据产品设定了“预测有效期”。整套数据处理与模型预测流程每月自动执行一次,对全量用户数据进行更新,确保企业始终基于最新、最准确的预测进行决策。
This dataset is a structured and actionable knowledge set covering three dimensions: user profile, preference prediction, and churn risk level. Its core value lies in transforming raw data into data that supports enterprise decision-making and management. It quantifies users' static attributes and dynamic behaviors through "churn risk prediction score" and "user churn risk level", enabling refined management of the customer lifecycle. By formulating differentiated strategies—sending high-value coupons and conducting exclusive customer follow-ups for "high-risk" users, and carrying out light-touch outreach for "medium-risk" users—enterprises can achieve precise and low-cost intervention and retention of high-value customers with potential churn risks, significantly optimizing the return on investment (ROI) of customer retention budgets.
1. Data Collection: Collect authorized historical transaction data, behavior log data, and basic attribute data of users from the enterprise's own platform.
2. Data Processing: Direct personal user ID identifiers are processed with encrypted hashing, making it impossible to trace back to a specific individual. Identify, clean, and impute missing, abnormal, and logically erroneous data to ensure data quality and consistency. Associate and integrate tables from different data sources to form a unified full user behavior record table with user ID as the primary key.
3. The "Gradient Boosting Decision Tree" algorithm adopted by this data product solidifies users' dynamic preferences into stable labels through statistical and rule-based models based on their historical behaviors. The user preference prediction model adopts multi-label classification, taking the solidified user profiles (gender, age group, historical regional preferences, transportation preferences, etc.) and recent activity level as input features. The model outputs the prediction probability of each user for different preference labels, which are finally aggregated into the structured "preference prediction" field. The user churn risk prediction model adopts a binary classification model, which is trained with the target variable of whether the user will churn in the subsequent cycle. The core feature is the user activity index, and the model calculates a "churn risk prediction score" between 0 and 1 for each user. The higher the score, the greater the possibility of churn. Threshold intervals are set for the "churn risk prediction score" for segmentation: 0-3 is low risk, 4-6 is medium risk, and 7-9 is high risk. This is a rule-based post-processing procedure. To ensure the timeliness of predictions, this data product sets a "prediction validity period". The entire data processing and model prediction workflow is automatically executed once a month to update the full user data, ensuring that enterprises always make decisions based on the latest and most accurate predictions.
提供机构:
大乐致行(浙江)科技有限公司
创建时间:
2025-09-30
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含608条用户出行相关数据,每月更新,涵盖用户ID、性别、出行偏好和流失风险预测等16个字段,用于预测用户出行意图和偏好。它采用梯度提升决策树算法分析用户历史行为,生成结构化预测结果,支持企业进行客户流失干预和精准营销决策。
以上内容由遇见数据集搜集并总结生成


