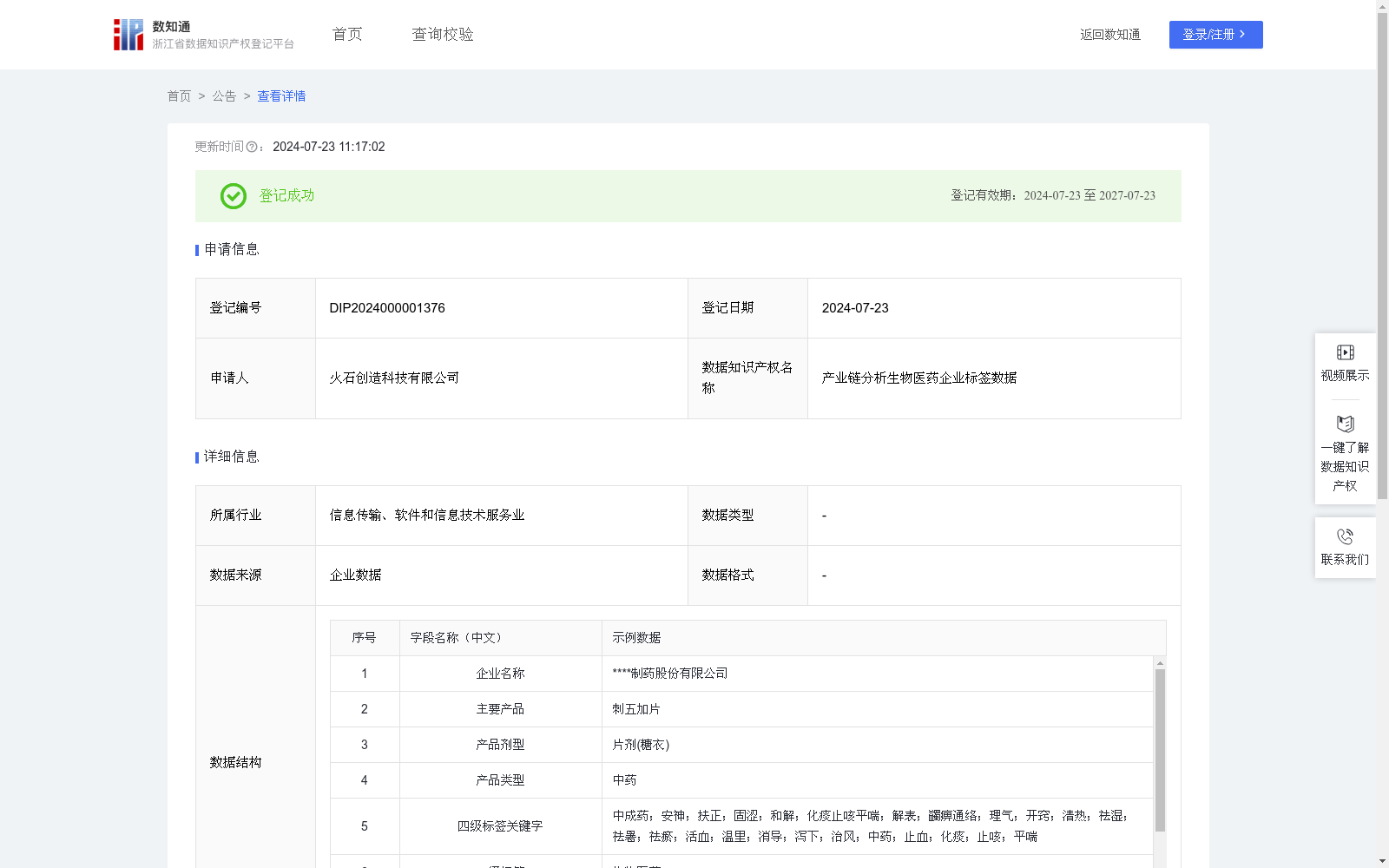
产业链分析生物医药企业标签数据
收藏浙江省数据知识产权登记平台2024-07-23 更新2024-07-24 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/40140
下载链接
链接失效反馈官方服务:
资源简介:
通过对企业基本信息和关键词的匹配,确定公司的行业分类,为企业数据分类、分析提供前提对企业名称、主要产品、产品剂型、产品类型四个字段进行文本识别,和四级标签关键字字段进行匹配。匹配算法使用前缀树算法,用关键字字段构建前缀树,确定根节点。根节点就是所有关键字的公共前缀,比如说所有的关键字都是“药”开头的,那根节点就是“药”,如果关键字的开头不相同,那根节点就是为空字符,不影响计算。然后用文本从根节点开始逐字符遍历,如果节点出现该字符则进入子节点,如果没有出现则返回上一节点向下遍历,适用于大文本量快速匹配。当文本中出现四级标签关键字字段中任意一个关键词时,即确定该公司的行业分类一级标签为生物医药,二级标签为药品,三级标签为中药,四级标签为中成药。随即完成对一级标签、二级标签、三级标签、四级标签的自动填写。如果没有出现关键字字段中的任何关键词,则不匹配到该分类。
By matching enterprise basic information with keywords, this method determines the industry classification of companies, providing a prerequisite for enterprise data classification and analysis. It conducts text recognition on four fields: enterprise name, main products, product dosage form, and product type, and matches the recognized text with the keyword field for four-level classification tags. The matching algorithm employs the prefix tree (trie) algorithm: a trie structure is constructed using the keyword field to determine the root node. The root node represents the common prefix of all keywords. For example, if all keywords start with "drug", the root node is "drug"; if the starting characters of the keywords differ, the root node is an empty string, which does not impact the calculation. Subsequently, the recognized text is traversed character by character starting from the root node. If the current node has a child node corresponding to the current character, the traversal proceeds to the child node; otherwise, it returns to the parent node and continues downward traversal. This method is suitable for fast matching of large-volume texts. If any keyword from the four-level tag keyword field appears in the recognized text, the company's industry classification tags are determined as follows: the first-level label is Biomedical, the second-level label is Pharmaceuticals, the third-level label is Traditional Chinese Medicine (TCM), and the fourth-level label is Chinese Proprietary Medicines. The automatic filling of the first-level, second-level, third-level, and fourth-level tags is then completed. If none of the keywords in the keyword field are detected in the text, no matching classification will be assigned.
提供机构:
火石创造科技有限公司
创建时间:
2024-05-22
搜集汇总
数据集介绍
特点
该数据集包含2788条生物医药企业的标签数据,通过文本识别和前缀树算法匹配企业信息与标签关键字,确定企业的行业分类。数据每周更新,适用于企业数据分类和分析。
以上内容由遇见数据集搜集并总结生成


