pretext-ui-harbor-runs-v0
收藏Hugging Face2026-05-02 更新2026-05-04 收录
下载链接:
https://huggingface.co/datasets/RLAIF/pretext-ui-harbor-runs-v0
下载链接
链接失效反馈官方服务:
资源简介:
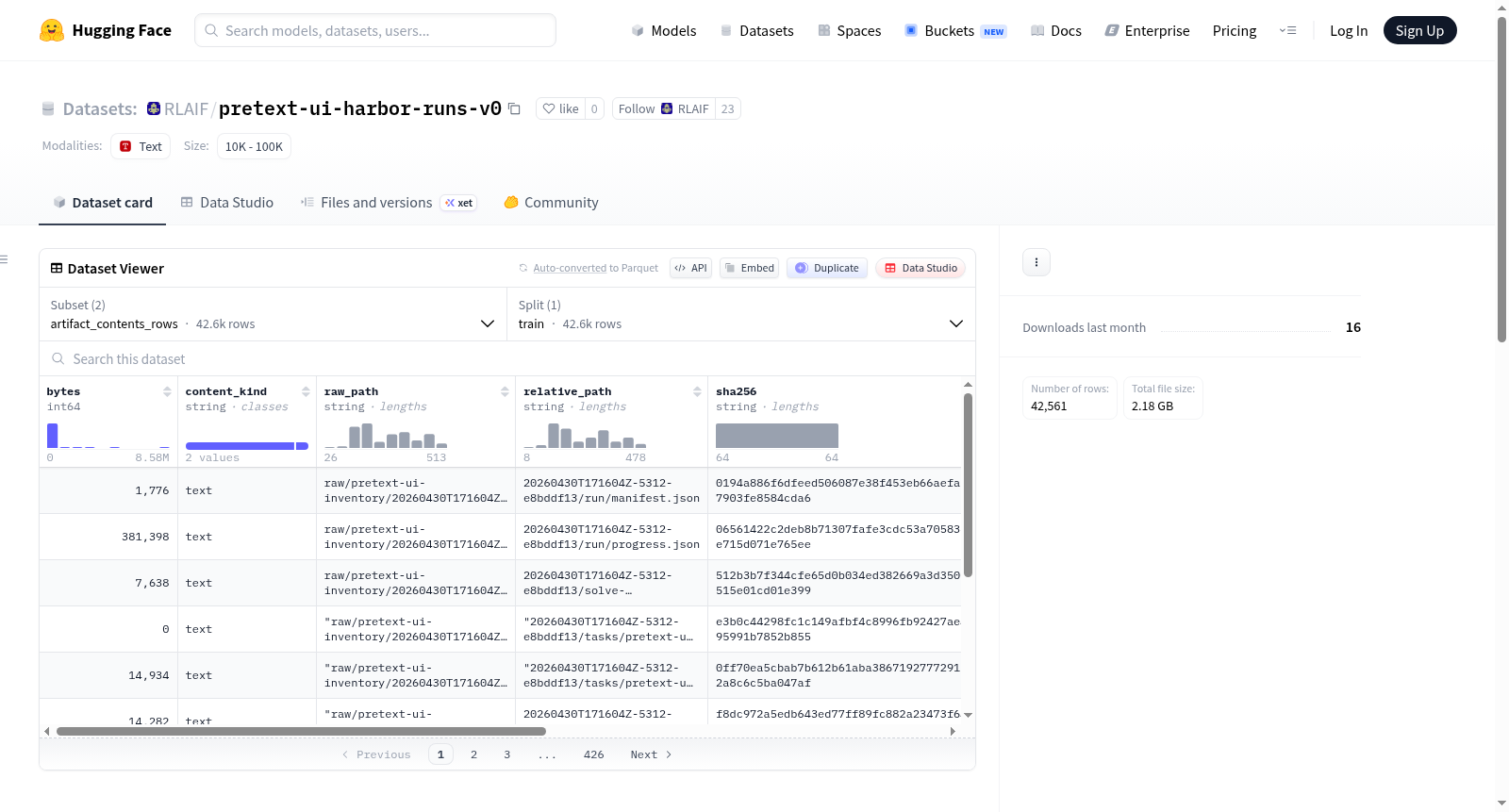
Pretext UI Harbor Runs数据集是一个用于`@chenglou/pretext` UI任务家族的Harbor任务生成和解决运行的语料库。数据集包含平面训练索引和原始脱敏Harbor工件,主要内容包括尝试记录(每行包含模型桶、奖励、Gemini分数、提示和原始工件指针)、任务标识/哈希索引、从轨迹中派生的OpenAI风格用户/助手对话行(不含隐藏推理)、用于DPO/RL风格实验的奖励排序尝试对、用于重建Harbor查看器作业/试验分组的平面索引,以及原始工件文件清单和哈希。此外,数据集还提供完整的脱敏Harbor运行输出和材料化任务。数据集规模包括1022条尝试记录、239条任务记录、764条SFT对话记录、6871条偏好对记录、42559个原始文件和1333360423字节的原始数据。数据集在发布前已进行API密钥字段的脱敏处理和未脱敏秘密的最终扫描。
The Pretext UI Harbor Runs dataset is a corpus for the Harbor task generation and solution runs of the `@chenglou/pretext` UI task family. The dataset includes flat training indices and original desensitized Harbor artifacts. Main contents include: attempt records (each line contains a model bucket, reward, Gemini score, prompt, and original artifact pointer), task ID/hash indices, OpenAI-style user/assistant dialogue lines derived from trajectories (without hidden reasoning), reward-ranked attempt pairs for DPO/RL-style experiments, flat indices for reconstructing Harbor viewer job/trial groupings, and original artifact file manifests and hashes. Additionally, the dataset provides complete desensitized Harbor run outputs and materialized tasks. The dataset scale includes 1022 attempt records, 239 task records, 764 SFT dialogue records, 6871 preference pair records, 42559 original files, and 1333360423 bytes of raw data. The dataset has undergone desensitization of API key fields and a final scan for unredacted secrets prior to release.
提供机构:
RLAIF
创建时间:
2026-05-02
搜集汇总
数据集介绍
构建方式
本数据集源自预训练文本用户界面(Pretext UI)任务家族中的Harbor任务生成与求解运行语料库,旨在为基于@chenglou/pretext框架的界面任务提供结构化训练索引与原始工件。其构建方式整合了多源异构数据:一方面包含平铺式训练索引,如候选尝试记录、任务身份哈希索引、基于轨迹生成的类OpenAI对话行及偏好对数据;另一方面汇集了完整的Harbor运行输出、物化任务、源生成工件及家族资源等原始文件。数据集分为多个配置子集,其中artifact_contents_rows配置专注于存储工件的字节数、内容种类、路径、哈希值及文本信息。原始数据在出版前已通过源仓库导出机制对已知API密钥字段进行脱敏处理,并经由未脱敏秘密扫描确保数据安全性。
使用方法
该数据集在HuggingFace平台上以多种配置形式提供加载。用户可通过指定config_name参数分别加载artifact_contents_rows配置以获取工件内容行数据,或加载default配置以获取平铺式训练索引文件。数据文件采用JSONL格式存储,便于流式处理与分布式训练。artifact_contents_rows配置下,训练集包含42561条样本,总字节数约1.24GB,下载大小约308MB,适合在内存受限环境下进行逐步加载。数据集的多种子集——如尝试记录、任务索引、对话行、偏好对及Viewer任务分组——均可通过路径区分直接使用,方便研究者针对监督微调、基于人类反馈的强化学习或偏好优化等不同实验范式快速选取所需数据子集。
背景与挑战
背景概述
Pretext UI Harbor Runs v0 数据集诞生于人工智能领域对用户界面(UI)任务自动化与推理能力日益增长的需求之中。该数据集由以 @chenglou 为核心的 Pretext 项目团队创建,旨在为多模态 UI 任务生成与求解的基准测试提供系统化支撑。通过整合 Harbor 框架下的任务生成与求解运行记录,数据集囊括了任务索引、模型尝试、奖励信号及偏好对等丰富结构,为视觉语言模型在复杂 UI 环境下的行为研究奠定了重要基础。其对 UI 任务学习与评估范式的推动,使其在智能代理与交互式系统研究中占据关键位置。
当前挑战
该数据集所应对的核心领域挑战在于,现有模型在理解与执行多步骤 UI 任务时缺乏鲁棒且可泛化的评估基准,而研究者常受限于任务规模小、重复性高及奖励信号噪声大等问题。构建过程中,团队面临多重技术难题:一是需对 Harbor 运行输出进行去敏感化处理,并确保红action后的数据不泄露 API 密钥等敏感信息;二是如何从庞杂的原始工件中提取结构化的奖励排序与偏好对,以支持 DPO/RL 等进阶训练范式;三是平衡数据规模与质量,在压缩存储的同时保持任务多样性和标注一致性。
常用场景
经典使用场景
在人工智能与用户界面(UI)自动生成的交叉领域中,Pretext UI Harbor Runs数据集扮演着关键角色。该数据集收集了针对@chenglou/pretext UI任务家族的各类求解尝试,涵盖了任务生成与求解运行的完整流程。最经典的使用场景在于,它为训练和评估基于语言模型的UI任务自动化代理提供了结构化的训练索引与原始红acted Harbor工件。研究者可利用其中的attempts、tasks、sft_conversations及preference_pairs等子集,构建从任务理解到行为生成的端到端学习范式,从而推动UI任务自动化领域从规则驱动向数据驱动的方法演进。
解决学术问题
该数据集有效应对了UI任务自动化研究中长期存在的两大困境:一是缺乏大规模、多样化且经过标注的UI任务样本,二是难以量化模型在复杂UI场景中的求解质量。通过提供包含模型分桶、奖励值、Gemini评分及原始工件指针的尝试记录,Pretext UI Harbor Runs使得研究者能够开展奖励建模、偏好对齐以及策略优化等前沿课题。其SFT对话与偏好对数据子集,更是弥合了隐式推理轨迹与显式监督信号之间的鸿沟,为探索可解释UI代理与基于人类反馈的强化学习(RLHF)奠定了基础,深刻影响了人机交互与智能体系统的理论发展。
实际应用
在实际部署中,该数据集赋能了众多面向图形用户界面的智能助理与自动化测试工具。基于数据集中任务索引与求解轨迹的映射关系,开发者能够训练模型自动执行如表单填写、菜单导航、参数配置等重复性UI操作,从而显著提升软件测试与办公自动化的效率。此外,数据集中的红acted工件与求解报告可用于构建UI操作的安全审核机制,例如通过对比不同模型在相同任务上的行为模式来检测异常或偏差。这些应用在金融、医疗等对界面操作准确性要求严苛的行业中,具有极高的落地价值。
数据集最近研究
最新研究方向
在软件工程与人工智能交叉领域中,pretext-ui-harbor-runs-v0数据集为基于预训练模型的UI自动化任务生成与求解研究提供了关键支撑。该数据集收录了Harbor框架下的完整任务求解轨迹、偏好对及对话序列,其独特之处在于同时包含了原始执行产物与经过脱敏处理的运行时工件,使得研究者能够在确保安全性的前提下,深入探究大语言模型在复杂图形用户界面上的行为模式与推理能力。当前前沿方向聚焦于利用该数据集中的偏好对结构进行直接偏好优化(DPO)实验,并结合多轮交互轨迹构建高效的监督微调流水线,以期在真实UI环境中实现更稳健的任务泛化与错误校正。这一数据资源的开放,正推动着从静态指令遵循到动态环境交互的研究范式跃迁,对于构建可靠且可解释的自主UI代理系统具有里程碑式的意义。
以上内容由遇见数据集搜集并总结生成


