propicto-orfeo
收藏Propicto-orféo
📝 数据集描述
Propicto-orféo 是一个法语数据集,包含对齐的语音ID、转录和图标(图标对应于与ARASAAC图标关联的标识符)。该数据集是从CEFC-Orféo语料库创建的,并在LREC-Coling 2024的研究论文 "A Multimodal French Corpus of Aligned Speech, Text, and Pictogram Sequences for Speech-to-Pictogram Machine Translation" 中进行了介绍。数据集被分为训练集、验证集和测试集。
Propicto-orféo 包含三个CSV文件:train、valid和test,统计信息如下:
| Split | Number of utterances |
|---|---|
| train | 231 374 |
| valid | 28 796 |
| test | 29 009 |
- 策划者: Cécile MACAIRE
- 资助方: PROPICTO ANR-20-CE93-0005
- 语言(NLP): 法语
- 许可证: CC-BY-NC-SA-4.0
⚒️ 数据集结构
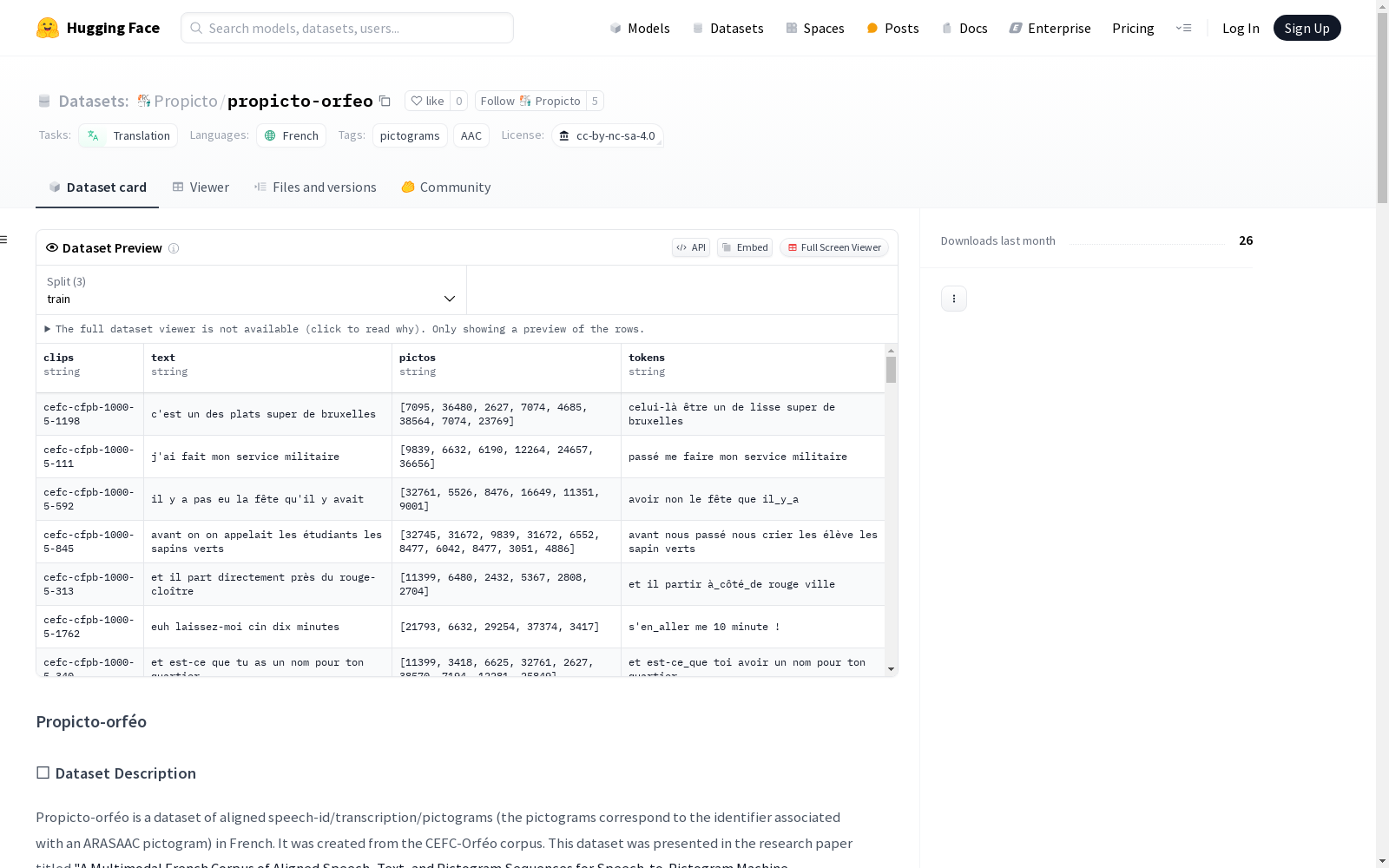
每个文件包含以下信息: csv id : 语音的唯一标识符,对应于orféo数据集中的唯一音频剪辑文件(wav格式) text : 音频剪辑的转录 pictos : ARASAAC的图标ID序列 tokens : 与ARASAAC图标ID关联的关键字序列
💡 数据集示例
给定样本: csv id : cefc-cfpb-1000-5-1186 text : tu essayes de mélanger les deux pictos : [6625, 26144, 7074, 5515, 5367] tokens : toi essayer de mélanger à_côté_de
- 该剪辑来自Orféo子语料库 CFPB, 1000-5,句子ID为1186。
- 文本是对应的转录,英文为:“you try to mix the two”。
- Pictos是图标ID序列,每个图标可以从以下地址检索:6625 = https://static.arasaac.org/pictograms/6625/6625_2500.png
- Tokens是从特定词典中检索的,可用于训练翻译模型。
数据集来源
- 语料库: CEFC-Orféo
- 论文:
💻 用途
Propicto-orféo 旨在用于训练语音到图标和文本到图标的翻译模型。该数据集还可用于微调大型语言模型,以执行图标翻译。
⚙️ 数据集创建
数据集通过应用特定的形式化方法创建,该方法将法语口语转录转换为相应的图标序列。形式化方法包括一组语法规则,用于处理法语中的特定现象(否定、命名实体、代词形式、复数等),以及一个词典,该词典将每个ARASAAC图标ID与一组关键字(tokens)关联。该形式化方法在 LREC 中进行了介绍。
源数据:对话/会议/日常生活情境(口语转录)
偏差、风险和局限性
由于翻译中可能存在错误或遗漏的词语,翻译可能部分不正确。
📌 引用
bibtex @inproceedings{macaire-etal-2024-multimodal, title = "A Multimodal {F}rench Corpus of Aligned Speech, Text, and Pictogram Sequences for Speech-to-Pictogram Machine Translation", author = "Macaire, C{e}cile and Dion, Chlo{e} and Arrigo, Jordan and Lemaire, Claire and Esperan{c{c}}a-Rodier, Emmanuelle and Lecouteux, Benjamin and Schwab, Didier", booktitle = "Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)", year = "2024", publisher = "ELRA and ICCL", url = "https://aclanthology.org/2024.lrec-main.76", pages = "839--849", }
@inproceedings{macaire24_interspeech, title = {Towards Speech-to-Pictograms Translation}, author = {Cécile Macaire and Chloé Dion and Didier Schwab and Benjamin Lecouteux and Emmanuelle Esperança-Rodier}, year = {2024}, booktitle = {Interspeech 2024}, pages = {857--861}, doi = {10.21437/Interspeech.2024-490}, issn = {2958-1796}, }
👩🏫 数据集卡片作者
Cécile MACAIRE, Chloé DION, Emmanuelle ESPÉRANÇA-RODIER, Benjamin LECOUTEUX, Didier SCHWAB