arda-argmax/simchoir-parquet
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/arda-argmax/simchoir-parquet
下载链接
链接失效反馈官方服务:
资源简介:
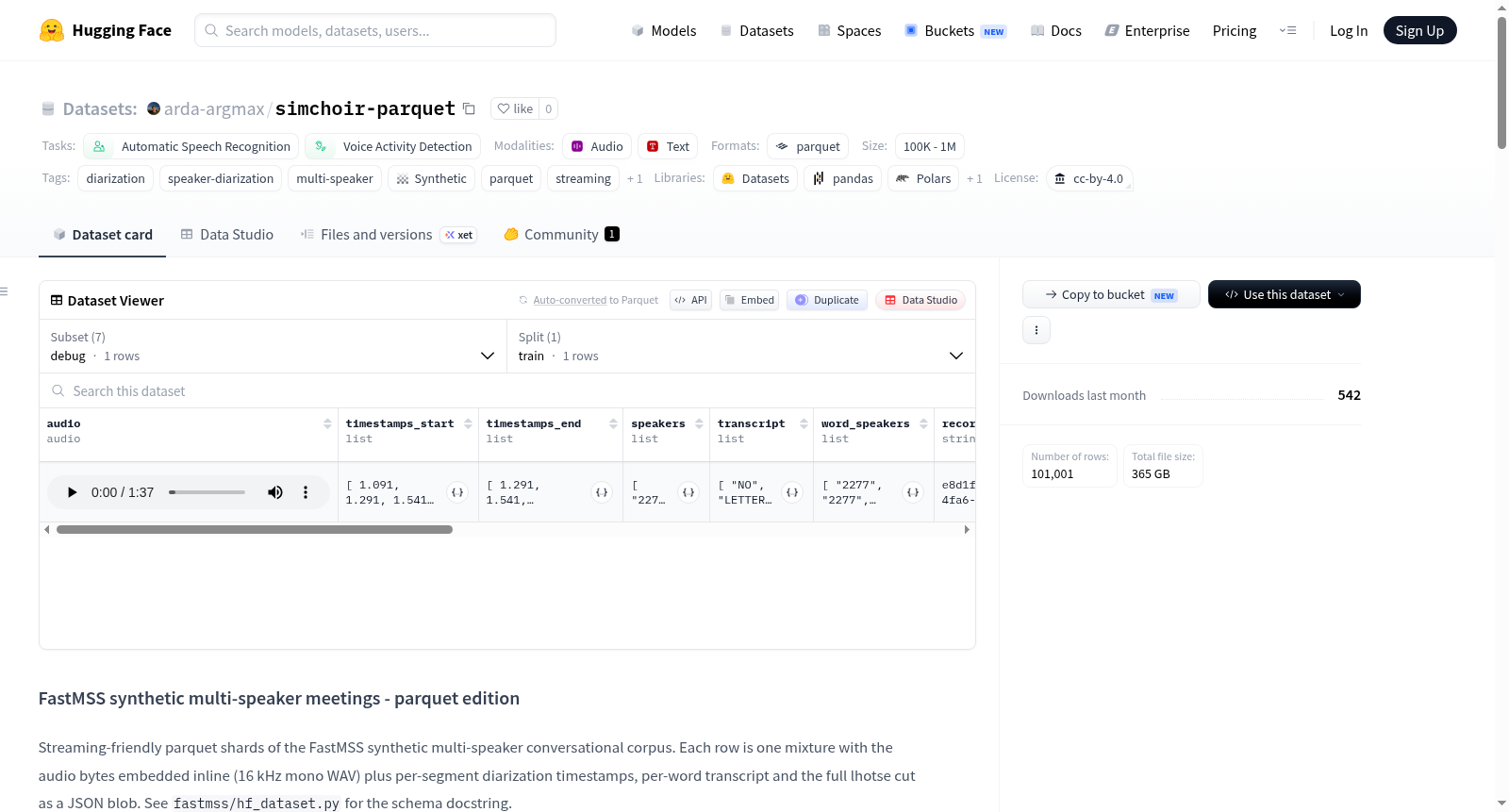
FastMSS合成的多说话人会议数据集(parquet版)是一个流式友好的parquet分片数据集,包含合成的多说话人对话语料库。每行数据包含内联嵌入的音频字节(16 kHz单声道WAV)、每个片段的说话人日志时间戳、逐字转录以及完整的lhotse cut JSON blob。数据集适用于自动语音识别(ASR)、语音活动检测(VAD)和说话人日志(diarization)任务。数据集包含多个子集(debug、v0.1、v0.2),每个子集有不同的训练和验证分割。数据集的详细字段包括音频、时间戳、说话人标签、转录文本等。
FastMSS synthetic multi-speaker meetings (parquet edition) is a streaming-friendly parquet shards dataset containing synthetic multi-speaker conversational corpus. Each row includes inline embedded audio bytes (16 kHz mono WAV), per-segment diarization timestamps, per-word transcript, and the full lhotse cut as a JSON blob. The dataset is suitable for automatic speech recognition (ASR), voice activity detection (VAD), and speaker diarization tasks. It includes multiple subsets (debug, v0.1, v0.2) with different train and validation splits. Detailed fields in the dataset include audio, timestamps, speaker labels, transcript text, etc.
提供机构:
arda-argmax
搜集汇总
数据集介绍
构建方式
在语音信号处理领域,多说话人会议场景的语料资源长期面临标注成本高昂与隐私保护的双重挑战。simchoir-parquet数据集作为FastMSS项目的衍生成果,采用合成数据生成技术构建,通过将LibriSpeech、AMI等公开数据集中的单通道语音片段,依据预设的说话人轮次与重叠模式进行混合与拼接,模拟出包含2至4位参与者的会议录音。数据以Parquet列式存储格式提供,按版本迭代组织,从v0.1至v0.4逐步扩展规模与场景复杂度,并专门设置了debug配置便于快速验证流程。
特点
该数据集的核心特色在于其面向说话人日志(Speaker Diarization)与语音活动检测(Voice Activity Detection)任务设计的精细化标注。每一条样本均包含了多说话人语音的混合波形以及精确到帧级别的时间戳与说话人身份标签,支持对说话人切换与重叠发音的深入研究。版本v0.3_4spk与v0.4系列进一步引入了基于不同声源数据库的变体,使得模型能够适应多种声学环境与口音特征。数据采用流式加载友好的Parquet格式,兼顾了存储效率与大规模训练的随机读取需求。
使用方法
研究者在加载simchoir-parquet数据集时,可通过HuggingFace Datasets库指定配置名称,例如选择'v0.2'或'v0.4_librispeech'版本,以适配不同的实验需求。数据集预划分了训练集与验证集,便于直接用于模型训练与性能评估。使用过程需注意将Parquet文件中的音频张量字段解码为波形数组,并结合标注的时间边界构建diarization损失函数。由于数据规模随版本增大,建议采用流式加载或分片读取策略,以降低内存占用。
背景与挑战
背景概述
在语音处理领域,多说话人场景下的声纹识别、语音活动检测与说话人日志任务长期受限于真实标注数据的稀缺性与高昂的采集成本。FastMSS(Fast Multi-Speaker Synthesis)项目旨在通过合成手段生成大规模、高质量的多说话人会议对话数据,以弥补这一空白。该数据集以Parquet格式存储,依托于cc-by-4.0许可协议,由相关研究机构于近年开发,核心研究问题聚焦于如何利用可控的合成策略模拟真实会议中的重叠语音、说话人交替及背景噪声等复杂声学现象。其影响力体现在为自动语音识别、语音活动检测及说话人日志等任务提供了可扩展、可复现的基准训练资源,尤其推动了端到端模型在多人交互场景下的泛化能力研究。
当前挑战
该数据集面临的核心挑战之一在于合成数据与真实录音之间的领域鸿沟,包括合成语音中残留的人工痕迹、说话人声学特征的真实性不足,以及重叠语音的自然度问题,这些均可能影响模型在真实场景中的鲁棒性。构建过程中,需精细模拟多说话人会议的动态结构,涵盖说话人数量、轮次切换、语速差异及背景噪声的多样性,同时确保标注的同步精准性。此外,大规模合成带来数据分片与版本管理的复杂性,如多版本配置(v0.1至v0.4)间的数据一致性维护,以及如何高效处理海量Parquet文件在流式训练中的I/O瓶颈,均为数据构建与使用增添了技术挑战。
常用场景
经典使用场景
在语音信号处理与多说话人交互分析领域,simchoir-parquet数据集以其合成多说话人会议音频的独特设计,成为训练和评估说话人日志(Speaker Diarization)系统的经典基石。该数据集通过FastMSS方法生成逼真的多说话人对话场景,为自动语音识别(ASR)与语音活动检测(VAD)模型提供了大规模、高覆盖度的训练样本,尤其适用于研究重叠语音、说话人快速切换等复杂声学环境下的性能优化。
衍生相关工作
围绕simchoir-parquet衍生的经典工作包括FastMSS流水线优化、端到端联合语音活动检测与说话人日志框架,以及融合声学与语义特征的跨模态说话人识别方法。研究者在此基础上开发了动态时间对齐与说话人嵌入空间分离技术,进而催生了面向低资源语言的合成数据增强策略与基于自监督预训练的无标注日志模型,深刻影响了后续多说话人处理系统的评价标准与设计范式。
数据集最近研究
最新研究方向
在语音分离与说话人日志领域,合成多说话人会议数据集正成为推动模型鲁棒性与泛化能力的关键基石。围绕FastMSS框架构建的simchoir-parquet数据集,通过模拟真实会议场景中的重叠语音与说话人轮转,为自动语音识别和说话人日志任务提供了大规模、可扩展的基准资源。当前前沿研究聚焦于利用此类合成数据预训练端到端声纹分割模型,以应对复杂声学环境下的说话人重叠与快速切换挑战。该数据集的多版本迭代(如基于LibriSpeech和AMI的变体)进一步促进了跨域迁移学习,成为连接仿真训练与真实部署的重要桥梁,显著提升了多说话人场景下智能语音系统的可信度与实用性。
以上内容由遇见数据集搜集并总结生成


