nrl-ai/vn-spell-correction-train
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/nrl-ai/vn-spell-correction-train
下载链接
链接失效反馈官方服务:
资源简介:
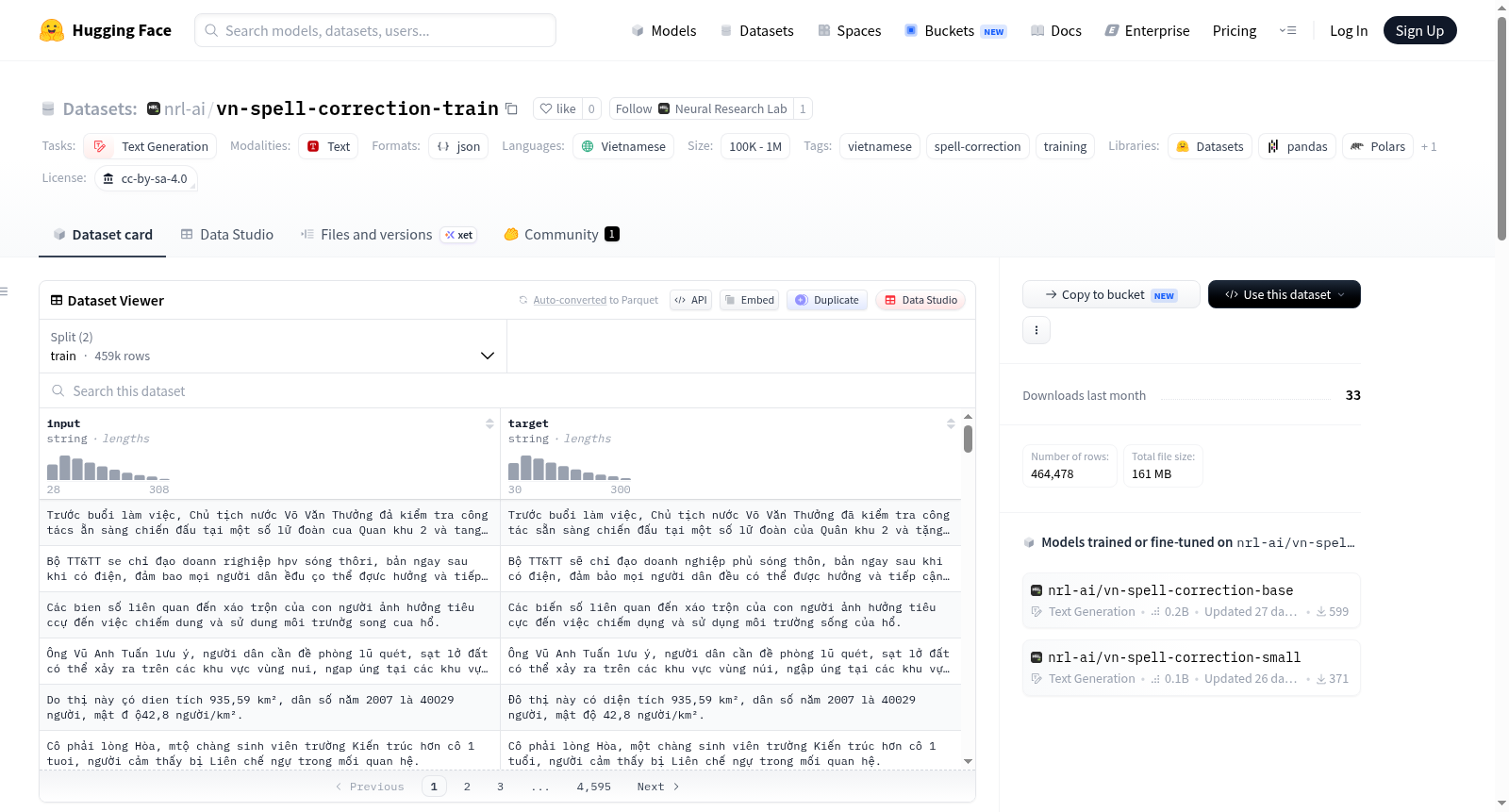
该数据集是一个越南语拼写校正训练数据集,包含459,478对(噪声,干净)越南语训练对,用于微调序列到序列的拼写校正模型。数据集的干净文本来自越南语维基百科和越南语新闻,噪声通过nom-vn库合成,包括轻度噪声、Telex输入法错误噪声和重度噪声三种预设。拼写校正任务涵盖音调恢复、键盘输入错误和OCR字符替换等。数据集格式为JSONL,包含训练集和验证集。许可证为CC-BY-SA-4.0。
This dataset is a Vietnamese spell-correction training dataset containing 459,478 (noisy, clean) Vietnamese training pairs for fine-tuning a seq2seq spell-correction model. The clean side of the dataset is sourced from Vietnamese Wikipedia and Vietnamese news, while the noisy side is synthetically generated using the nom-vn library with three noise presets: light noise, Telex typo noise, and heavy noise. The spell-correction task includes diacritic restoration, keyboard typos, and OCR-style character substitutions. The dataset is formatted in JSONL and includes train and validation splits. The license is CC-BY-SA-4.0.
提供机构:
nrl-ai
搜集汇总
数据集介绍
构建方式
该数据集由越南语维基百科与新闻文本构成清洁端语料,分别遵循CC-BY-SA-4.0与CC-BY-4.0协议,经NFC规范化处理后,通过`nom-vn`库的`nom.text.noise`模块对清洁文本施加三类合成噪声,包括模拟键盘输入错误的轻度噪声、模拟Telex/VNI输入法声调错误的特莱克斯噪声,以及模拟OCR识别错误的重度噪声,三类噪声以轮询方式均匀分布,最终生成459,478条(含噪文本,清洁文本)配对样本,确保模型能够学习多样化的拼写错误模式。
特点
该数据集涵盖了拼写校正任务的完整范畴,不仅包括声调恢复,还涉及字母缺失与冗余、键盘手误、以及OCR字符混淆等复杂噪声场景,相对于仅处理声调丢失的常规数据集,其适用性更为广泛。通过确定性的种子控制,可复现完全一致的训练配对,严谨的评估泄露防护机制确保训练集与独立评估集无重叠。
使用方法
开发者可通过HuggingFace的`datasets`库直接加载,指定`split='train'`即获得训练集,每条数据以JSON格式包含`input`与`target`字段。该数据集适用于微调序列到序列(seq2seq)模型,例如T5或Bart架构,用于越南语拼写校正任务。推荐在训练后结合官方评估集(`nrl-ai/vn-spell-correction-eval`)进行性能验证,并依据CC-BY-SA-4.0协议声明来源。
背景与挑战
背景概述
在自然语言处理领域,拼写纠错是提升文本质量与下游任务性能的关键环节,尤其对于形态丰富的语言如越南语而言,其复杂的声调系统和输入法错误导致拼写校正任务面临独特挑战。vn-spell-correction-train数据集由Neural Research Lab的Viet-Anh Nguyen等人于2026年创建,旨在为越南语序列到序列拼写校正模型提供大规模训练数据。该数据集包含459,478对(噪声,干净)越南语文本对,其核心研究问题在于构建一个能够同时处理声调恢复、字符替换和键盘误触等多类型错误的统一校正模型。作为越南语拼写校正领域的重要资源,该数据集通过合成噪声技术模拟真实场景中的打字错误与OCR输出,为相关研究提供了标准化的训练基准,显著推动了越南语文本纠错技术的发展。
当前挑战
该数据集旨在解决越南语拼写校正这一领域难题,其挑战包括:1)拼写校正是声调恢复的超集,需要同时应对声调缺失、字母替换、键盘误触及OCR字符混淆等多种噪声类型,而传统方法往往仅专注于单一错误来源;2)构建过程中面临的挑战在于生成逼真的合成噪声,需设计三种校准噪声预设(轻噪声、Telex输入法错误和重噪声)以平衡不同类型错误的分布,同时确保噪声的确定性和可复现性;3)数据集需避免训练与评估集之间的信息泄露,通过哈希校验实现严格防护,这对数据清洗与预处理流程提出了极高要求。
常用场景
经典使用场景
在越南语自然语言处理领域,拼写纠错是一项基础而关键的任务,尤其适用于处理带有打字错误、声调混乱或光学字符识别(OCR)噪声的文本。该数据集提供了近46万对经过精心构造的(噪声,干净)训练样本,覆盖从轻度键盘误触到重度OCR退化的多种噪声模式,为序列到序列模型的微调提供了标准范式。经典使用场景包括:针对越南语键盘输入错误(如Telex或VNI输入法导致的声调错位)、社交媒体短文本中的拼写失常,以及扫描文档的OCR后处理等进行模型训练。研究者可直接基于这些配对数据训练Transformer架构的编解码器模型,在越南语拼写纠错任务上达到最优效果。
衍生相关工作
该数据集的发布衍生了一系列相关研究工作。首先,其设计的合成噪声方案采用三阶段轮换机制,为后续低资源语言噪声数据增强提供了可复现的模板。基于该数据集训练的拼写纠错模型可替代传统声调还原模型,在更嘈杂的输入分布上保持更高精度。进一步,研究者可将其与对应的评测集(如vn-spell-correction-eval)结合,系统评估模型对未知噪声类型的泛化能力。同时,该数据集促使了越南语文本领域统一评测基准的建立,为对比不同噪声注入策略、模型架构与预训练权重效果提供了标准化平台,推动了越南语文本纠错技术的持续迭代与优化。
数据集最近研究
最新研究方向
在越南语自然语言处理领域,拼写纠错正从传统的基于规则的方法迈向端到端的序列到序列(seq2seq)学习范式。vn-spell-correction-train数据集应运而生,其高达近46万对的(噪声,干净)训练样本,特别是通过多级噪声预设(如轻量按键错误、Telex输入法漂移及重度OCR字符混淆)模拟真实场景,使得模型能够同时应对拼写打字错误、声调混淆和复杂形变字符替换。这一方向不仅超越了仅做声调恢复的局限,更与当前大语言模型在低资源语言中的鲁棒性提升需求深度契合,对于优化越南语OCR后处理、社交媒体内容规范及终端输入体验具有重要的落地意义。
以上内容由遇见数据集搜集并总结生成


