VideoTemp-o3
收藏数据集概述:VideoTemp-o3
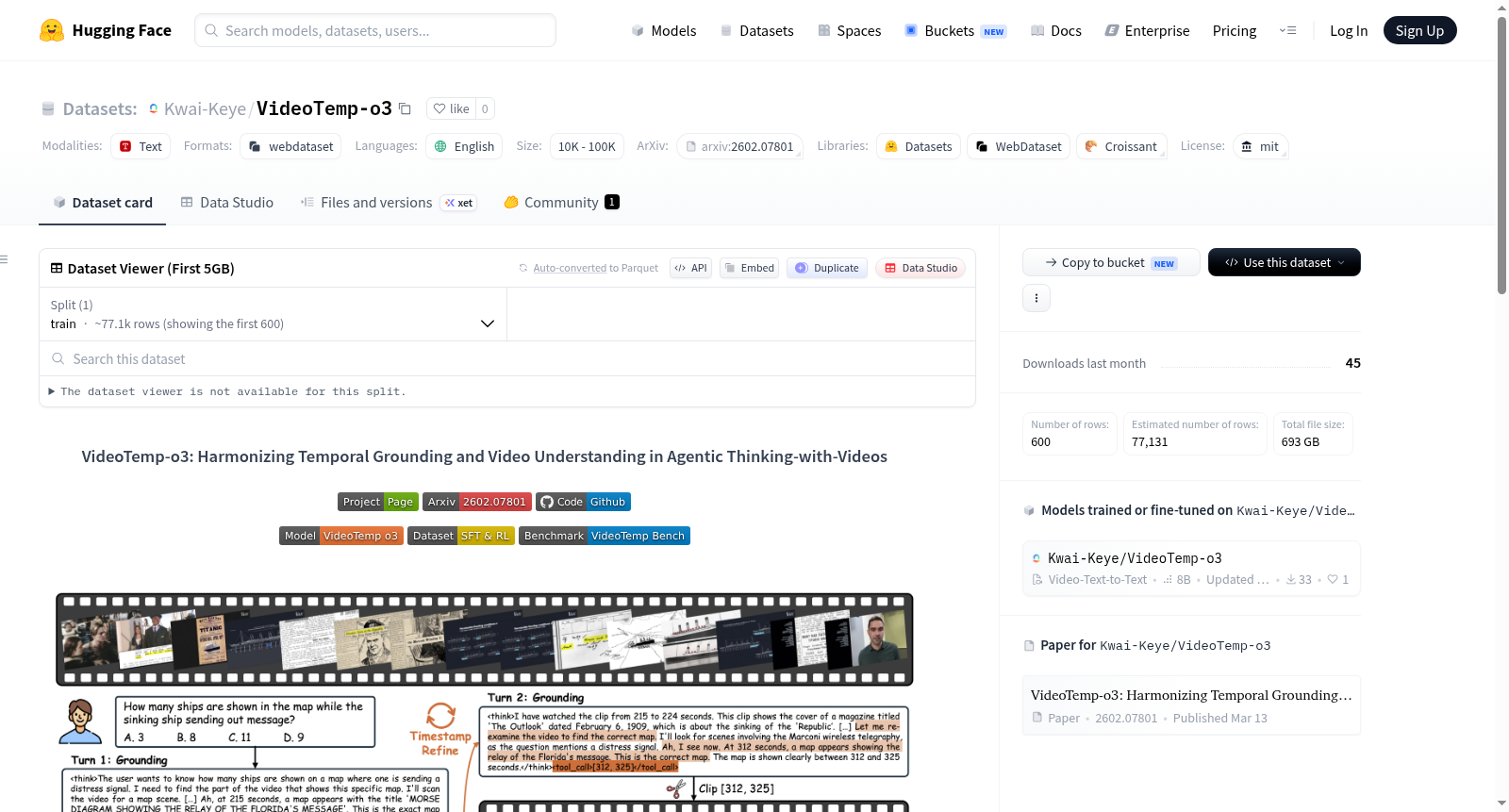
VideoTemp-o3 是一个面向视频理解与时间定位的联合训练数据集,旨在提升模型在“智能体式思考与视频交互(Agentic Thinking-with-Videos)”场景下的表现。该数据集包含监督微调(SFT)和强化学习(RL)两部分数据,由多个公开数据源整合而成,可用于训练具备按需时间定位与视觉证据推理能力的视频模型。
数据集构成
| 数据来源 | 原始仓库地址 |
|---|---|
| Charades-STA | https://github.com/jiyanggao/TALL |
| ActivityNet-MR | https://cs.stanford.edu/people/ranjaykrishna/densevid/ |
| VidChapters-7M | https://github.com/antoyang/VidChapters |
| QvHighlight | https://github.com/jayleicn/moment_detr |
| Time-R1 | https://huggingface.co/datasets/Boshenxx/TimeR1-Dataset |
| Video-R1 | https://huggingface.co/datasets/Video-R1/Video-R1-data |
| LongVideo-Reason | https://github.com/NVlabs/Long-RL |
| LongVILA | https://huggingface.co/datasets/LongVILA/longvila_sft_dataset |
特别地,sft/activitynet.jsonl、sft/charades.jsonl 和 sft/vidchapters.jsonl 三个子文件来源于 MultiTaskVideoReasoning 数据集。
数据用途与特点
- 训练目标:使模型能根据视频问答对(video QA pair)进行按需时间定位,定位最相关的视频片段,并经过迭代优化后,基于视觉证据产生可靠答案。
- 数据内容:包含多种视频理解任务(如时间定位、时间推理)的问答对,覆盖短视频(如 Charades-STA)和长视频(如 LongVideo-Reason、LongVILA)场景。
- 许可证:MIT 许可证。
- 语言:英语。
引用信息
如使用本数据集,请引用以下论文:
bibtex @article{liu2026videotemp, title={VideoTemp-o3: Harmonizing Temporal Grounding and Video Understanding in Agentic Thinking-with-Videos}, author={Liu, Wenqi and Wang, Yunxiao and Ma, Shijie and Liu, Meng and Su, Qile and Zhang, Tianke and Fan, Haonan and Liu, Changyi and Jiang, Kaiyu and Chen, Jiankang and Tang, Kaiyu and Wen, Bin and Yang, Fan and Gao, Tingting and Li, Han and Wei, Yinwei and Song, Xuemeng}, journal={arXiv preprint arXiv:2602.07801}, year={2026} }
相关链接
- 项目主页:https://liuwq-bit.github.io/VideoTemp-o3
- 论文:https://arxiv.org/abs/2602.07801
- 代码:https://github.com/Kwai-Keye/VideoTemp-o3
- 模型:https://huggingface.co/Kwai-Keye/VideoTemp-o3
- 数据集:https://huggingface.co/datasets/Kwai-Keye/VideoTemp-o3
- 基准测试:https://huggingface.co/datasets/Kwai-Keye/VideoTemp-Bench