DimitriosPanagoulias/COGNET-MD
收藏Hugging Face2024-05-20 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/DimitriosPanagoulias/COGNET-MD
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-nc-nd-4.0
size_categories:
- n<1K
language:
- en
pretty_name: cognetmd
tags:
- medical
- MCQ
---
# COGNET-MD
Cognitive Network Evaluation Toolkit for Medical Domains (COGNET-MD)
## Dataset Details
Testing the ability of LLMs in finding more than one correct choices in a medical domains, where a penalty is added for incorrect ones, simulating real world evaluating scenarios
of medical students.
Large Language Models (LLMs) constitute a breakthrough state-of-the-art Artificial Intelligence (AI) technology which is rapidly evolving and promises to aid in medical diagnosis either by assisting doctors or by simulating a doctor's workflow in more advanced and complex implementations. In this technical paper, we outline Cognitive Network Evaluation Toolkit for Medical Domains (COGNET-MD), which constitutes a novel benchmark for LLM evaluation in the medical domain. Specifically, we propose a scoring-framework with increased difficulty to assess the ability of LLMs in interpreting medical text. The proposed framework is accompanied with a database of Multiple Choice Quizzes (MCQs). To ensure alignment with current medical trends and enhance safety, usefulness, and applicability, these MCQs have been constructed in collaboration with several associated medical experts in various medical domains and are characterized by varying degrees of difficulty. The current (first) version of the database includes the medical domains of Psychiatry, Dentistry, Pulmonology, Dermatology and Endocrinology, but it will be continuously extended and expanded to include additional medical domains.
### Dataset Description
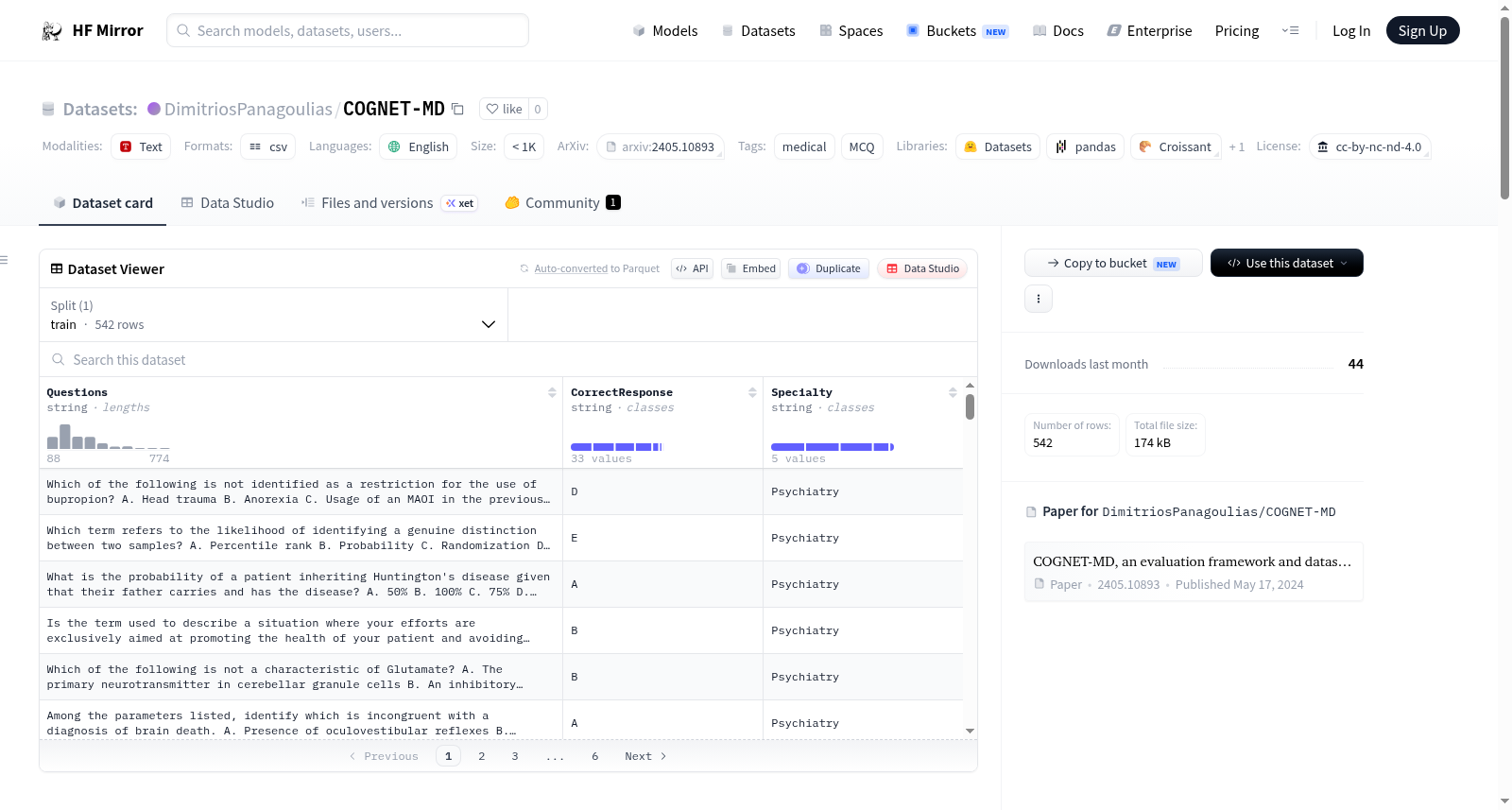
Cognitive Network Evaluation Toolkit for Medical Domains (COGNET-MD) consists of 542 datapoints of domain-specific questions (MCQs) with one or more correct choices/answers.
Version 1 includes MCQs in Dentistry , Dermatology , Endocrinology , Psychiatry and Pulmonology. We have included a scoring system as a python code for benchmarking purposes (see associated files).
See #Uses
The dataset can be used to assess the model’s ability to infer relationships between specialties and knowledge spaces. Thus it can be analyzed either as a whole, encompassing all included specialties-full Dataset, partially or it can be narrowed down to focus on a specific medical domain-specialty.
- **Curated by:** Dimitrios P. Panagoulias, Persephone Papatheodosiou, Anastasios F. Palamidas, Mattheos Sanoudos, Evridiki Tsoureli-Nikita, Maria Virvou, George A. Tsihrintzis
- **Language(s) (NLP):** English
- **License:** https://creativecommons.org/licenses/by-nc-nd/4.0/
### Dataset Sources
- **Paper:** COGNET-MD, an evaluation framework and dataset for Large Language Model benchmarks in the medical domain
- **Code** Included in Files
- Or direct dl with with datasets (pip install datasets)
```python
from datasets import load_dataset
dataset = load_dataset('DimitriosPanagoulias/COGNET-MD', split='train')
```
## Uses
Scoring should be:
* Partial Credit: At least one correct answer equals to a half point - 0.5.
* Full Credit: To achieve full points depending on difficulty either all correct answers must be selected and no incorrect ones or a correct response gets the full credit, equals to 1 point.
* Penalty for Incorrect Answers: Points are deducted for any incorrect an- swers selected. -(minus) 0.5 point for each incorrect answer selected.
| Specialty | Beta | Production |
|:------------|:------------|:------------|
| Partial Credit(0.5) | Partial Credit(0.5) | Partial Credit(0.5) |
| Full Credit(P+0.5=1) | Full Credit(P+0.5=1) |Full Credit(P+0.5=1) |
| MistakePenalty (0.5) | MistakePenalty (0.5) | MistakePenalty (0.5) |
|Domain-Specific|50% per specialty|full Dataset|
## Dataset Structure
To be added
## Dataset Creation
2024
### Curation Rationale
This is a dataset curated by domain-experts.
For a score to be valid and be added in the COGNET-MD’s leader-boards the developers, should clearly state model used, add a short model description and use case scenario used,
as described in the previous section. In the following Benchmark Card two examples are presented:
Benchmark Card should include:
MODEL -- Description -- Domain -- Difficulty COGNET-MD VERSION
## Citation
COGNET-MD, an evaluation framework and dataset for Large Language Model benchmarks in the medical domain
**BibTeX:**
@misc{panagoulias2024cognetmd,
title={COGNET-MD, an evaluation framework and dataset for Large Language Model benchmarks in the medical domain},
author={Dimitrios P. Panagoulias and Persephone Papatheodosiou and Anastasios P. Palamidas and Mattheos Sanoudos and Evridiki Tsoureli-Nikita and Maria Virvou and George A. Tsihrintzis},
year={2024},
eprint={2405.10893},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
## Dataset Card Contact
panagoulias_d@unipi.gr
提供机构:
DimitriosPanagoulias
原始信息汇总
COGNET-MD 数据集概述
基本信息
- 名称: COGNET-MD
- 语言: 英语
- 许可证: CC-BY-NC-ND-4.0
- 大小: 小于1000条记录
- 标签: 医学, MCQ
数据集描述
- 目的: 评估大型语言模型在医学领域中寻找多个正确选项的能力,并对错误选项施加惩罚,模拟真实世界中医学生的评估场景。
- 内容: 包含542个特定领域的多选题(MCQs),每个问题有一个或多个正确答案。
- 版本: 第一版包括牙科、皮肤病学、内分泌学、精神病学和肺病学的MCQs。
- 使用: 用于评估模型推断专业间关系和知识空间的能力,可整体分析或聚焦特定医学领域。
数据集结构
- 待添加
数据集来源
- 论文: COGNET-MD, 一个用于医学领域大型语言模型基准的评估框架和数据集
- 代码: 包含在文件中
使用指南
- 评分系统:
- 部分信用: 至少一个正确答案得0.5分。
- 全信用: 根据难度,所有正确答案且无错误答案得1分。
- 错误答案惩罚: 每个错误答案选择扣除0.5分。
创建与维护
- 创建年份: 2024
- 维护者: Dimitrios P. Panagoulias, Persephone Papatheodosiou, Anastasios F. Palamidas, Mattheos Sanoudos, Evridiki Tsoureli-Nikita, Maria Virvou, George A. Tsihrintzis
- 联系方式: panagoulias_d@unipi.gr
引用信息
bibtex @misc{panagoulias2024cognetmd, title={COGNET-MD, an evaluation framework and dataset for Large Language Model benchmarks in the medical domain}, author={Dimitrios P. Panagoulias and Persephone Papatheodosiou and Anastasios P. Palamidas and Mattheos Sanoudos and Evridiki Tsoureli-Nikita and Maria Virvou and George A. Tsihrintzis}, year={2024}, eprint={2405.10893}, archivePrefix={arXiv}, primaryClass={cs.CL} }
搜集汇总
数据集介绍
背景与挑战
背景概述
COGNET-MD是一个医学领域的大语言模型评估数据集,包含542个多选问题,涵盖精神病学、牙科学等多个专业,并采用带有惩罚机制的评分框架以模拟真实医学考试场景。该数据集由领域专家构建,旨在测试模型在复杂医学文本中的推理能力,适用于基准测试和研究用途。
以上内容由遇见数据集搜集并总结生成


